Metas SeamlessM4T bringt die Universalübersetzung näher

Meta veröffentlicht ein neues KI-Modell, das gesprochene Sprache direkt in 35 Sprachen und Text in 100 Sprachen übersetzen kann.
Mit dem neuen multimodalen Encoder-Decoder-Modell "SeamlessM4T" kombiniert Meta Technologien aus den langjährigen KI-Übersetzungsprojekten No Language Left Behind (NLLB), Universal Speech Translator und Massively Multilingual Speech in einem einzigen Modell. M4T steht für "Massively Multilingual & Multimodal Machine Translation".
Durch die Implementierung der verschiedenen Vorgängermodelle in einem System werden laut Meta Fehler und Verzögerungen reduziert und somit die Effizienz und Qualität des Übersetzungsprozesses verbessert.
Das Modell ist multimodal, da es neben gesprochener Sprache, also Audio in 35 Sprachen, auch Text in 100 Sprachen übersetzen kann. Insgesamt kann das Modell Sprache in Text, Sprache in Sprache, Text in Sprache und Text in Text übersetzen und Sprache automatisch erkennen.
Laut Meta ist SeamlessM4T das erste Modell, das viele Sprachen (35) direkt wieder in gesprochene Sprache übersetzen kann, ohne den Umweg über eine Textübersetzung zu nehmen. Damit soll das Modell ein "signifikanter Schritt" auf dem Weg zu einem Universalübersetzer wie dem Babel Fish in Per Anhalter durch die Galaxis sein, den Meta in der Ankündigung explizit als Ziel nennt.
Video: Meta
Meta will Sprachbarrieren auf eigenen sozialen Plattformen überwinden
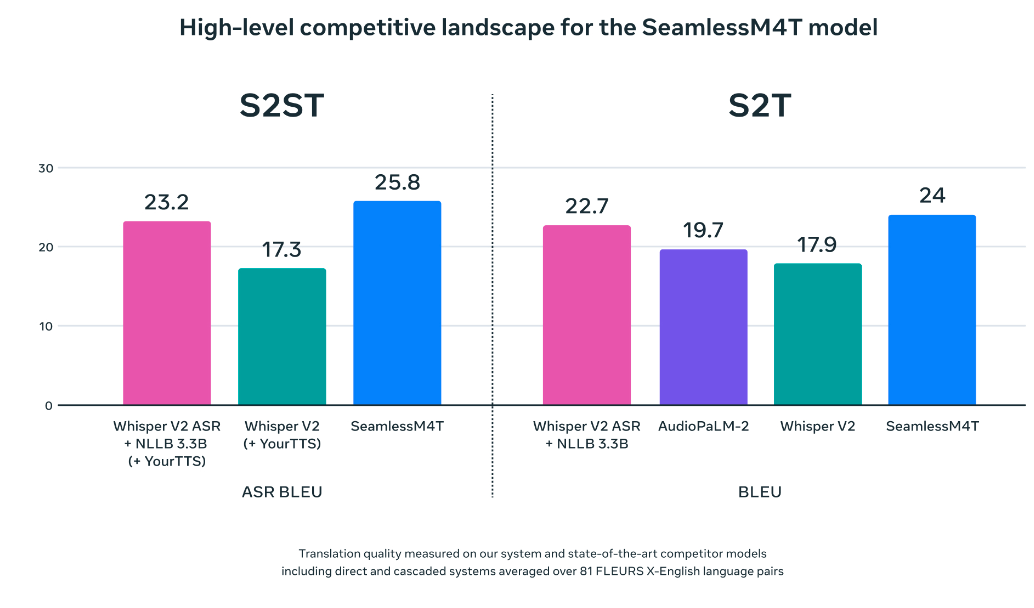
Laut Meta erzielt SeamlessM4T in den gängigen Übersetzungsbenchmarks neue State-of-the-Art-Ergebnisse und übertrifft Whisper von OpenAI. Wer sich selbst von den Qualitäten überzeugen möchte, kann hier eine interaktive Demo testen.
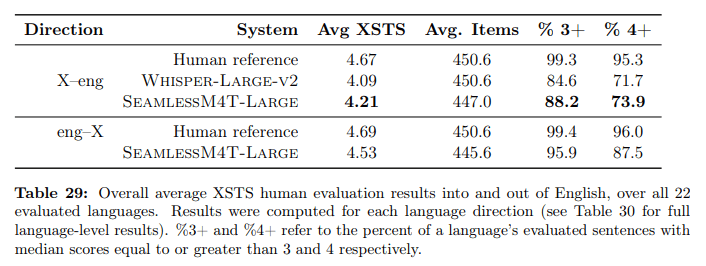
Auch bei der menschlichen Bewertung liegt das größte SeamlessM4T-Modell vor Whisper, allerdings ist der Abstand geringer. Beide Modelle liegen qualitativ noch hinter den menschlichen Übersetzungen, aber der Abstand verringert sich mit jedem neuen Modell.
Meta veröffentlicht das Modell unter der Lizenz CC BY-NC 4.0 als Open-Source-Modell bei Github, das allerdings nicht kommerziell genutzt werden darf. Laut Meta-Chef Mark Zuckerberg sollen die KI-Übersetzungstechnologien perspektivisch in die eigenen sozialen Plattformen Facebook, Instagram, WhatsApp, Messenger und Threads integriert werden.
Neben dem Modell veröffentlicht Meta auch den Datensatz "SeamlessAlign", den das Team für das Training von SeamlessM4T zusammengetragen hat. Der laut Meta größte offene Datensatz für multimodale Übersetzung umfasst 470.000 Stunden Material für 37 Sprachen. Eine Erweiterung auf 100 Sprachen ist ein Thema für zukünftige Entwicklungen. Das wäre dann der nächste Schritt zum Universalübersetzer.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.