Microsofts MAI-DxO sorgt für präzisere KI-Diagnosen und spart fast 70 Prozent der Kosten
Ein neues KI-System von Microsoft soll bei komplexen medizinischen Fällen eine viermal höhere diagnostische Genauigkeit als erfahrene Ärzte erreichen und gleichzeitig die Kosten senken. Ein neuer Benchmark simuliert dafür den realen, schrittweisen Diagnoseprozess.
Forscher von Microsoft AI haben ein KI-System vorgestellt, das die Art und Weise, wie komplexe Krankheiten diagnostiziert werden, grundlegend verändern könnte. Laut dem Paper "Sequential Diagnosis with Language Models" übertrifft das System menschliche Ärzte bei schwierigen Fällen deutlich in Genauigkeit und Kosteneffizienz.
Um die Fähigkeiten von KI-Modellen realistischer zu bewerten, entwickelten die Forscher zuerst den "Sequential Diagnosis Benchmark" (SDBench). Bestehende Tests, so die Autoren, würden die Kompetenz von Sprachmodellen oft überschätzen, da sie Informationen in fertigen Vignetten präsentieren und nicht den schrittweisen Prozess der klinischen Praxis abbilden.
SDBench basiert auf 304 diagnostisch anspruchsvollen Fallberichten aus dem New England Journal of Medicine (NEJM). Ein KI- oder menschlicher Diagnostiker erhält zu Beginn nur eine kurze Fallzusammenfassung und muss aktiv weitere Informationen durch gezielte Fragen oder die Anforderung von Tests anfordern. Ein "Gatekeeper"-Modell gibt dabei nur die explizit angeforderten Informationen preis und kann laut dem Paper sogar realistische, synthetische Ergebnisse für Tests generieren, die im ursprünglichen Fall nicht beschrieben wurden, um keine unbeabsichtigten Hinweise zu geben.
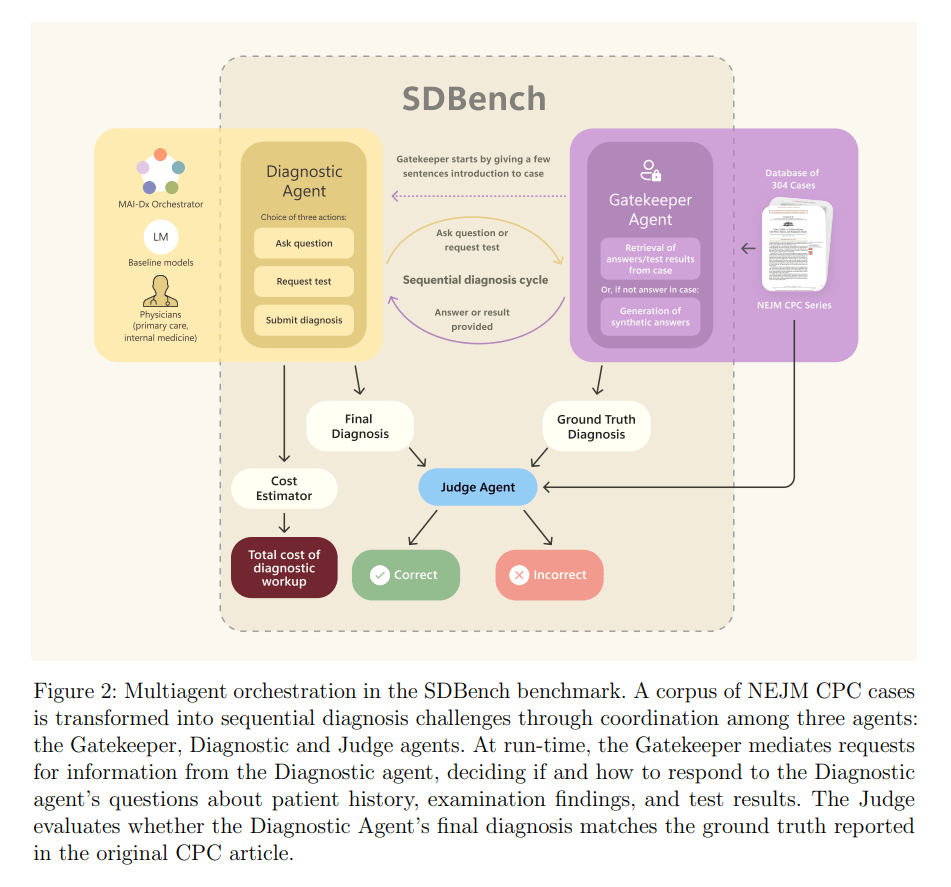
Die Kosten werden dabei als Summe der angeforderten Tests und Arztbesuche berechnet. Laut den Forschern wird jeder Diagnose-Durchgang, der aus Fragen an den Patienten besteht, pauschal mit 300 US-Dollar für einen Arztbesuch veranschlagt. Die Kosten für spezifische Tests werden über ein System ermittelt, das die Anfragen in standardisierte CPT-Codes (Current Procedural Terminology) übersetzt und mit einer Preistabelle eines großen US-Gesundheitssystems aus dem Jahr 2023 abgleicht.
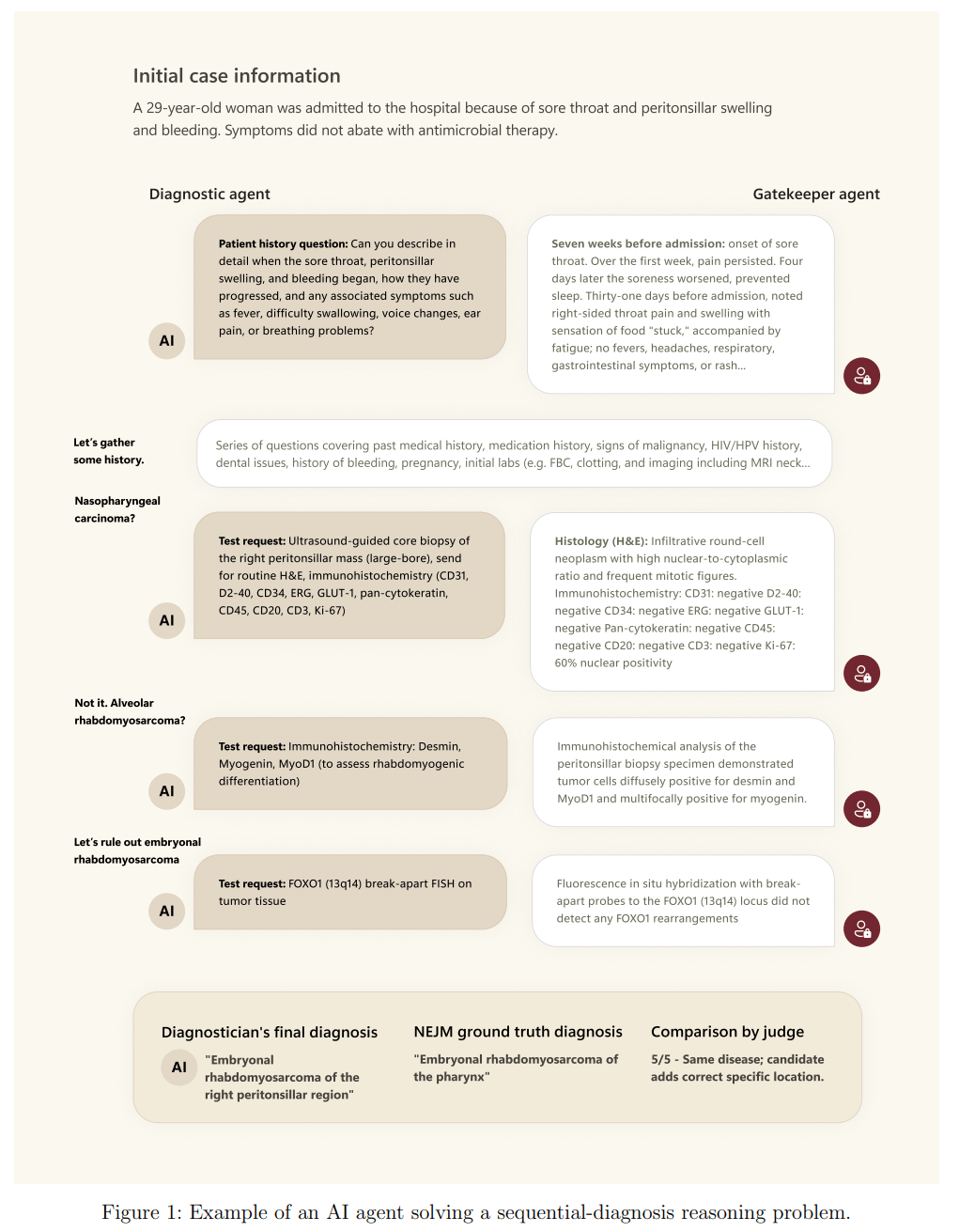
In diesem Test erreichte eine Gruppe von 21 erfahrenen Ärzten aus den USA und Großbritannien eine diagnostische Genauigkeit von 19,9 Prozent bei durchschnittlichen Kosten von 2.963 US-Dollar pro Fall. Im Gegensatz dazu erzielte das von Microsoft entwickelte System "MAI Diagnostic Orchestrator" (MAI-DxO) in Kombination mit dem o3-Modell von OpenAI eine Genauigkeit von 79,9 Prozent bei Kosten von nur 2.397 US-Dollar.
Der wesentliche Beitrag von MAI-DxO ist dabei vor allem die Kostensenkung: Ohne die Orchestrierung erreichte o3 mit 78,6 Prozent zwar die höchste Genauigkeit unter den Standardmodellen, verursachte aber mit 7.850 US-Dollar pro Fall auch die mit Abstand höchsten Kosten. Durch den Einsatz von MAI-DxO konnte die Genauigkeit also leicht gesteigert, aber vor allem die Kosten um fast 70 Prozent gesenkt werden.
Virtuelles Ärzteteam verbessert Diagnose
Der Erfolg von MAI-DxO basiert laut dem Paper auf einem orchestrierten Ansatz, der ein virtuelles Gremium von Ärzten simuliert. Dabei übernimmt ein einziges Sprachmodell fünf verschiedene Rollen: "Dr. Hypothesis" pflegt eine Liste wahrscheinlicher Diagnosen, "Dr. Test-Chooser" wählt die aussagekräftigsten Tests aus, und "Dr. Challenger" agiert als " Advocatus Diaboli", um kognitive Verzerrungen wie vorschnelle Urteile zu vermeiden. "Dr. Stewardship" überwacht die Kosten und "Dr. Checklist" sichert die Qualität.
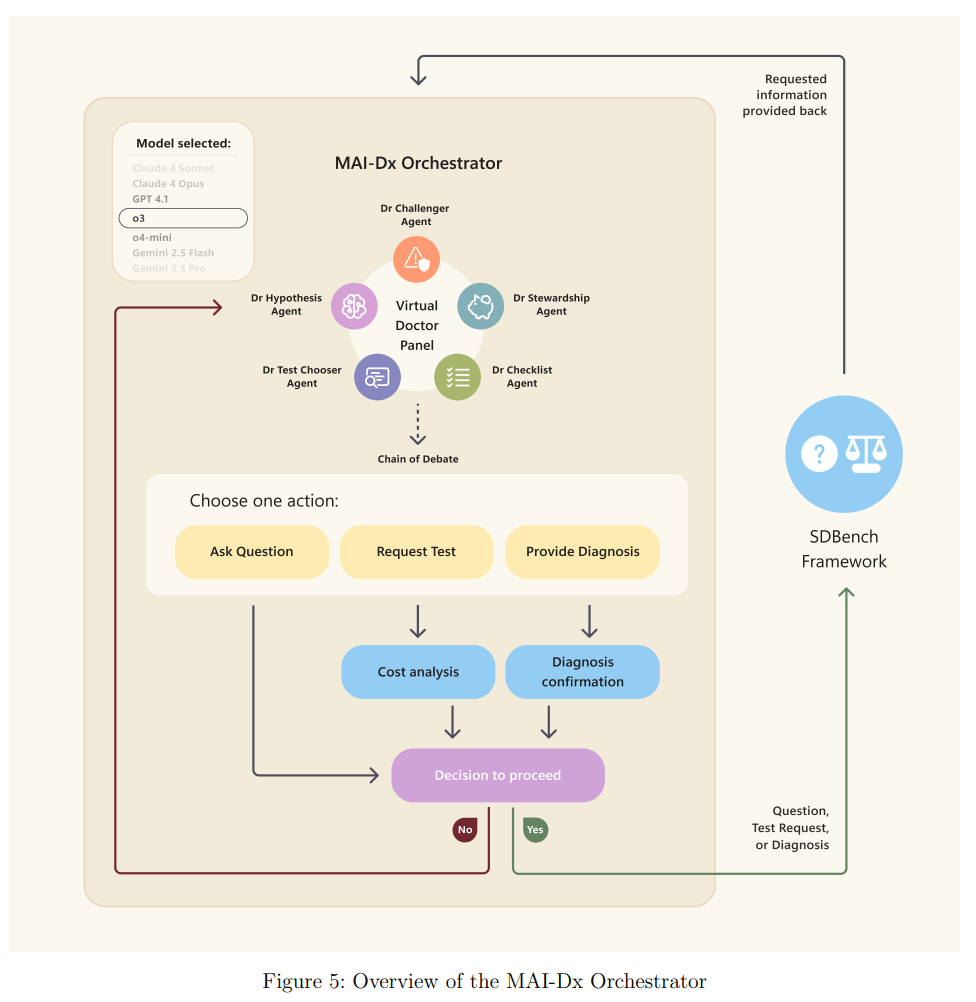
Diese strukturierte Vorgehensweise soll verhindern, dass das System sich auf eine frühe Hypothese festlegt. In einem Fallbeispiel habe ein Standard-Sprachmodell fälschlicherweise eine Antibiotika-Toxizität vermutet, teure Tests für 3.431 US-Dollar angeordnet und eine falsche Diagnose gestellt. MAI-DxO hingegen habe durch gezielte Fragen nach einer möglichen Toxin-Exposition die wahre Ursache – die Einnahme von Händedesinfektionsmittel – für nur 795 US-Dollar korrekt identifiziert.
Einschränkungen und offene Fragen
Die Autoren räumen in ihrem Paper mehrere Einschränkungen ein. Der Benchmark basiere ausschließlich auf komplexen und für Lehrzwecke kuratierten Fällen des NEJM. Er spiegle daher nicht die Verteilung von Krankheiten in der realen klinischen Praxis wider und enthalte keine Fälle von gesunden Patienten oder harmlosen Syndromen. Ob die Leistungsgewinne des Systems auch auf häufige, alltägliche Erkrankungen übertragbar sind, sei daher unklar.
Zudem seien die berechneten Kosten nur eine Annäherung. Sie basieren auf US-Preisen und berücksichtigen keine realen Faktoren wie geografische Unterschiede, Versicherungssysteme, die Invasivität von Tests, Wartezeiten oder die Verfügbarkeit von Geräten.
Auch der Vergleich mit menschlichen Ärzten sei limitiert. Die teilnehmenden Ärzte waren Allgemeinmediziner, die solche komplexen Fälle in der Praxis an Spezialisten überweisen würden. Außerdem durften sie im Gegensatz zum realen Alltag keine externen Hilfsmittel wie Suchmaschinen oder Fachliteratur verwenden. Die Autoren betonen, dass die "übermenschliche" Leistung der KI auch darauf zurückzuführen sei, dass sie das breite Wissen eines Allgemeinarztes mit der tiefen Expertise mehrerer Spezialisten kombinieren könne, was für einen einzelnen Menschen unrealistisch sei.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.