Microsoft veröffentlicht kleines Phi-4-LLM als Open-Source-Modell mit Gewichten
Update vom 8. Januar 2025:
Nach der Ankündigung im Dezember hat Microsoft nun die vollständigen Modellgewichte seines kompakten und leistungsfähigen KI-Modells Phi-4 auf Hugging Face veröffentlicht.
Mit der Veröffentlichung unter der MIT-Lizenz können Entwickler und Forscher das Modell jetzt frei nutzen, modifizieren und weiterentwickeln - auch für kommerzielle Zwecke. Durch die Veröffentlichung der Modellgewichte erhalten Entwickler und Forscher zudem Zugang zu den genauen Parametern, was weitergehende Anpassungen ermöglicht.
Ursprünglicher Artikel vom 13. Dezember 2024:
Microsofts Phi-4-Modell zeigt, wie synthetische Daten die KI-Leistung steigern können
Microsoft Research stellt mit Phi-4 ein KI-Sprachmodell vor, das es trotz seiner geringen Größe mit den Schwergewichten der Branche aufnehmen kann. Gezielt eingesetzte synthetische Trainingsdaten spielen eine entscheidende Rolle.
Microsoft Research hat ein neues KI-Sprachmodell namens Phi-4 entwickelt, das mit nur 14 Milliarden Parametern die Leistung von bis zu fünfmal größeren Modellen erreicht. Laut dem technischen Bericht des Unternehmens übertrifft Phi-4 sogar das eigene Lehrermodell GPT-4 bei der Beantwortung von Fragen aus den Bereichen Naturwissenschaft und Technik.
Besonders beeindruckend sind die Ergebnisse bei mathematischen Aufgaben: Bei Fragen auf Universitätsniveau erreicht das Modell laut Microsoft eine Trefferquote von 56,1 Prozent. Bei mathematischen Wettbewerbsaufgaben liegt die Trefferquote sogar bei 80,4 Prozent.
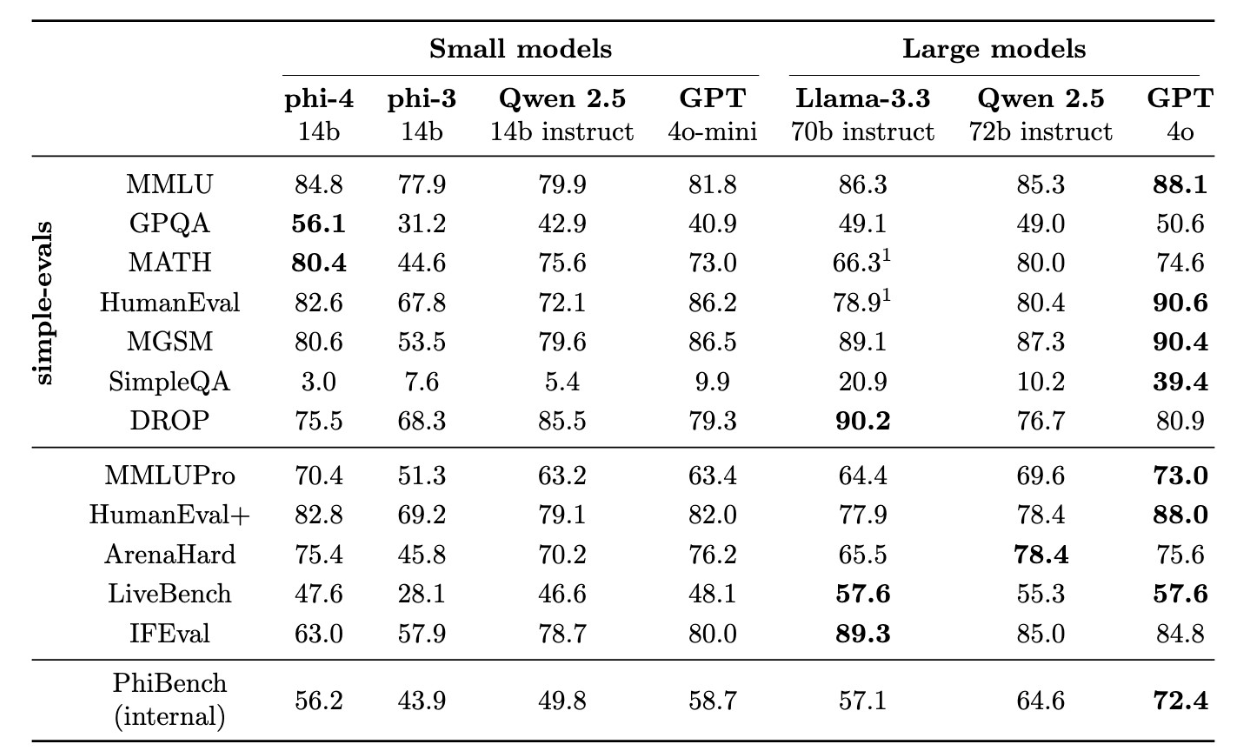
Schwächen hat das Modell laut Microsoft hingegen bei der genauen Einhaltung von Prompts und Formatvorgaben wie Tabellen. Laut der Forscher lag der Fokus des Trainings auf Q&A und Reasoning, weniger auf strenger Befolgung von Anweisungen.
Wie alle LLMs kann Phi-4 halluzinieren, z.B. falsche Biographien für unbekannte Personen erfinden. Auch bei einfachen logischen Aufgaben kann Phi-4 Fehler machen. Zum Beispiel kann es fälschlicherweise zu dem Schluss kommen, dass 9,9 kleiner als 9,11 ist - ein beliebter LLM-Logik-Test.
Wie immer sind gute Benchmark-Ergebnisse keine Garantie für eine überzeugende Leistung in der Praxis. Frühere Phi-Modelle hatten ebenfalls hervorragende Benchmark-Ergebnisse, erwiesen sich aber in der Praxis als weniger brauchbar.
Synthetische Daten als Schlüssel zum Erfolg
Im Gegensatz zu den meisten Sprachmodellen, die hauptsächlich mit Webinhalten oder Code trainiert werden, verwendet Phi-4 gezielt generierte Datensätze. "Synthetische Daten sind kein billiger Ersatz für organische Daten, sondern bieten direkte Vorteile", heißt es im technischen Bericht.
Die Entwicklung von Phi-4 basiert laut Microsoft auf drei Säulen. Erstens der Einsatz hochwertiger, synthetischer "lehrbuchartiger" Daten für das Vor- und Zwischentraining. Die Forscher entwickelten 50 verschiedene Arten synthetischer Datensätze mit insgesamt etwa 400 Milliarden Token in Bereichen wie mathematisches Denken, Programmierung und Allgemeinwissen.
Zweitens, eine sorgfältige Auswahl und Filterung von qualitativ hochwertigen organischen Daten; neben öffentlichen Dokumenten und qualitativ hochwertigen Bildungsmaterialien verwendet das Modell auch Programmiercode.
Drittens eine Weiterentwicklung der Trainingsmethoden in der Endphase, in der das Modell lernt, qualitativ hochwertige von weniger hochwertigen Antworten zu unterscheiden.
Eine technische Neuerung ist die Verwendung besonders wichtiger Schlüsselwörter, so genannter "pivotal tokens": bestimmte Tokens innerhalb einer Antwort, die einen überproportional großen Einfluss darauf haben, ob die Antwort richtig oder falsch ist.
Dabei kann es sich um ein bestimmtes Wort oder Symbol handeln, das im Sinne einer Weggabelung zu einem besseren oder schlechteren Ergebnis führt. Die Forscherinnen und Forscher entwickelten eine Methode, um diese Tokens zu identifizieren, und trainierten das Modell gezielt auf diese entscheidenden Wendepunkte, die bei eindeutigen Fragen zu richtigen Ergebnissen führten.
Das Team bezeichnet den Lernprozess von Phi-4 als "spoonfeeding" - "Fütterung mit dem Löffel" -, da das Modell die Informationen schrittweise und in "leicht verdaulicher" Form erhält.
Während organische Daten oft komplexe und indirekte Beziehungen zwischen Tokens aufweisen, seien synthetisch generierte Daten besser für das Training geeignet. Das Modell könne dadurch strukturierter lernen.
Bubeck kündigt Open-Weights-Veröffentlichung an
Der Microsoft-Phi-Entwickler Sebastien Bubeck, jetzt bei OpenAI tätig, kündigte auf X an, dass die Gewichte des Modells öffentlich zugänglich gemacht werden sollen. "Phi-4 spielt in der Liga von Llama 3.3-70B, mit fünfmal weniger Parametern", schreibt Bubeck.
Das Team testete Phi-4 auch an den amerikanischen Mathematik-Wettbewerben vom November 2024 - also an Aufgaben, die erst nach Abschluss des Trainings veröffentlicht wurden. Damit wollten die Forschenden ausschließen, dass die Testaufgaben bereits in den Trainingsdaten enthalten waren, was die Ergebnisse verfälscht hätte. Die guten Ergebnisse bei diesen garantiert neuen Aufgaben hätten das Team überrascht, so Bubeck.

Phi-4 ist derzeit bei Microsofts Azure AI Foundry verfügbar und soll in der kommenden Woche bei HuggingFace veröffentlicht werden, voraussichtlich mit einer Forschungslizenz.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.