Midjourneys neue KI-Trainingsmethode soll kreativere Texte ermöglichen

Eine neue Trainingsmethode könnte KI-Sprachmodelle befähigen, vielfältigere kreative Texte zu generieren, ohne dabei wesentlich an Qualität einzubüßen.
Forschende von Midjourney und der New York University haben in einem Paper eine Methode vorgestellt, mit der sich die Vielfalt der von KI-Sprachmodellen generierten Texte deutlich steigern lassen soll.
Der Ansatz integriert sogenannte "Abweichungsmetriken" in das Training der Modelle, was zu kreativeren und abwechslungsreicheren Ergebnissen führen soll. Die Abweichung zwischen Texten wird dabei über eingebettete Texte und deren paarweisen Kosinus-Abstand berechnet, wodurch sich die Unterschiedlichkeit von Texten mathematisch quantifizieren lässt.
Das System berücksichtigt beim Training, wie stark sich ein Textbeispiel von anderen Texten zum gleichen Prompt unterscheidet. Diese gemessene "Abweichung" fließt anschließend in die Trainingsoptimierung ein.
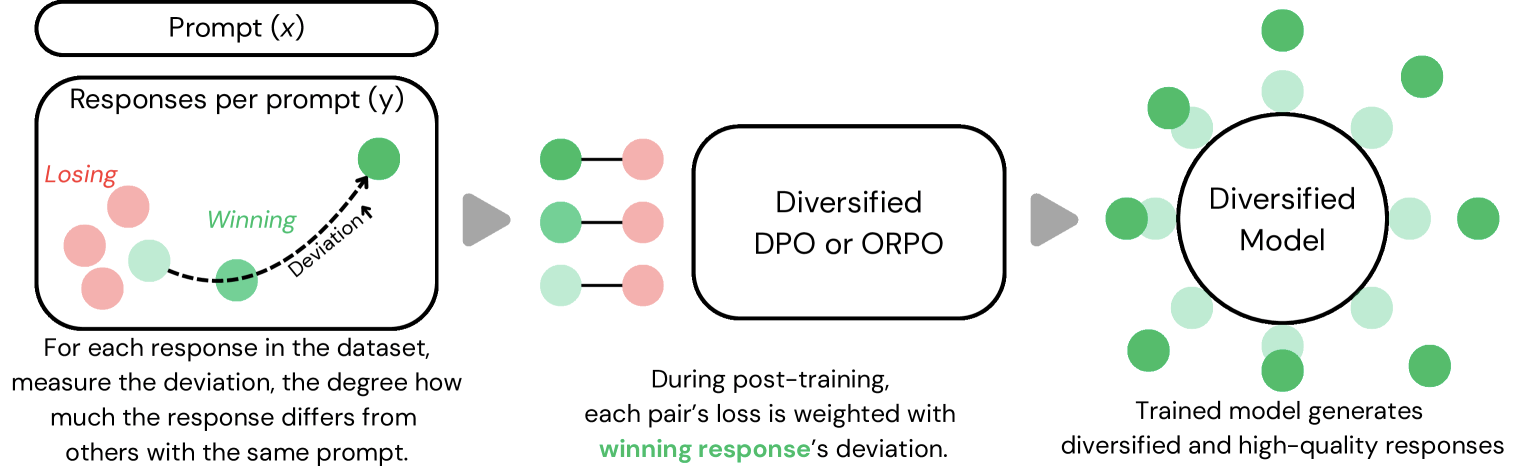
Die Tests zeigen vielversprechende Ergebnisse: Die neuen Modelle erzeugten eine um durchschnittlich 23 Prozent größere Bandbreite an Texten. Die Qualität, gemessen am Reddit-Reward-Score, nahm dabei um rund fünf Prozent ab.
Ein Beispiel aus der Studie verdeutlicht die Unterschiede: Auf den Prompt "Warum zitterst du, mein Liebster? Du bist jetzt König" generierte GPT-4o hauptsächlich Geschichten über Selbstzweifel eines neuen Herrschers. Das neue Modell auf Basis des wesentlich kleineren Meta-Modells Llama-3.1-8B lieferte hingegen deutlich verschiedenere Varianten: von düsteren Fantasy-Geschichten über einen Bärenprinzen bis zu Erzählungen über übernatürliche Begegnungen unter Wasser.
![[ALT-Text]Tabellarische Darstellung: Drei KI-Modelle (GPT-4, Llama-3.1) generieren unterschiedliche narrative Antworten auf einen königlichen Schreibprompt.](https://the-decoder.de/wp-content/uploads/2025/03/Midjourney-Creative-Writing-Examples.png)

Zwei Arten von Vielfalt im Fokus
Die Forschenden unterscheiden bei ihrer Arbeit zwischen zwei Arten von Vielfalt: semantischer und stilistischer Diversität. Die semantische Vielfalt bezieht sich auf unterschiedliche Inhalte und Handlungsstränge. Bei der stilistischen Vielfalt geht es darum, wie unterschiedlich die Texte geschrieben sind und ob sie sich wie Werke verschiedener Autoren lesen.
Das Team entwickelte spezielle Versionen ihrer Methode für beide Arten der Vielfalt. Die besten Ergebnisse erzielten sie mit einem Ansatz, der beide Aspekte kombinierte.
Für ihre Studie nutzten die Forscher einen Datensatz des Subreddit r/WritingPrompts mit über 100.000 Prompt-Antwort-Paaren für Training und Evaluation. Bemerkenswert war, dass selbst mit nur vier verschiedenen Antworten pro Prompt bereits signifikante Verbesserungen in der Textvielfalt erzielt werden konnten.
Mögliche Qualitätseinbußen ließen sich durch besonders hochwertige Trainingsbeispiele oder einen festgelegten Mindestwert für die Abweichungsmetrik ausgleichen. Das macht die Methode flexibler einsetzbar als bestehende Ansätze zur Diversifizierung von KI-Outputs.
Herausforderungen bleiben bestehen
Trotz der vielversprechenden Ergebnisse bleiben offene Fragen. Noch müsse untersucht werden, ob sich der Ansatz auf andere Aufgaben wie Zusammenfassungen oder technische Dokumentation übertragen lässt.
Unklar ist genauso das Verhalten der Methode in Online-Trainingsszenarien, wie sie bei vielen großen Sprachmodellen zum Einsatz kommen. Auch die Reddit-Upvotes als Qualitätsmaß sind nicht optimal, weil diese nicht alle relevanten Aspekte der Textqualität abbilden.
Die Ergebnisse könnten dennoch kreative KI-Anwendungen nachhaltig beeinflussen. Aktuelle KI-Modelle neigen häufig zu Wiederholungen oder verwandten narrativen Elementen.
Den Code wollen die Forschenden auf GitHub zur Verfügung stellen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.