Minecraft als Testfeld: KI-Agent ROCKET-1 setzt neuen Benchmark im Klötzchenspiel
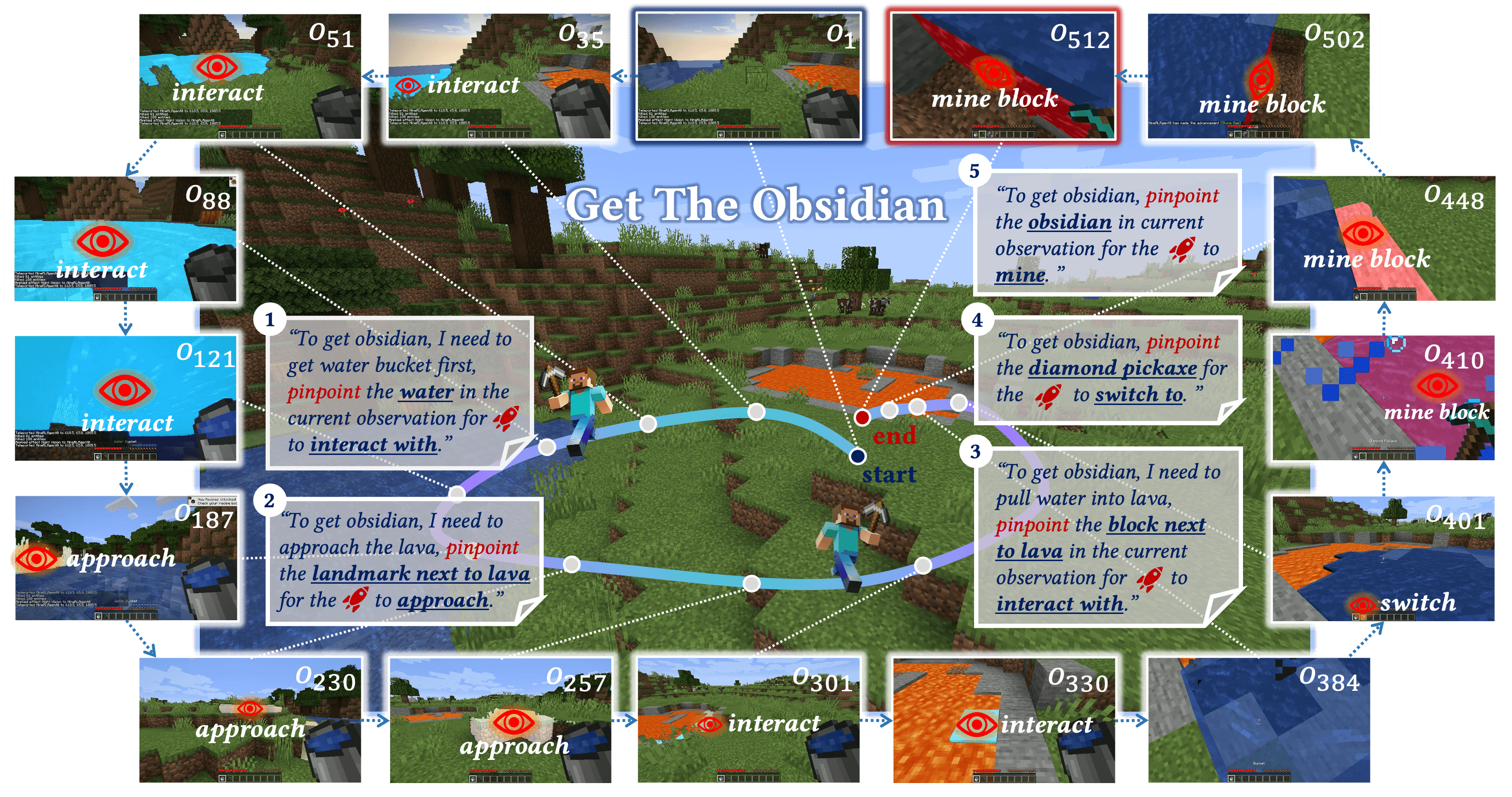
Ein Forscherteam stellt mit ROCKET-1 eine neue Methode vor, die es KI-Agenten ermöglicht, präziser in virtuellen Umgebungen wie Minecraft zu agieren. Der Ansatz kombiniert Objekterkennung und -verfolgung mit großen KI-Modellen.
Die Forscher haben eine neue Methode namens "Visual-temporal context prompting" entwickelt, die KI-Agenten eine präzisere Interaktion in virtuellen Umgebungen ermöglichen soll. Das System ROCKET-1 nutzt dabei eine Kombination aus Objekterkennung, -verfolgung und multimodalen KI-Modellen.
Bisherige Ansätze zur Steuerung von KI-Agenten, die etwa auf reine Sprachmodelle setzen, um Anweisungen zu generieren oder Diffusionsmodelle nutzen, um zukünftige Zustände in der Welt vorherzusagen, haben laut den Forschern Probleme: "Sprache scheitert oft daran, räumliche Informationen effektiv zu vermitteln, während die Generierung zukünftiger Bilder mit ausreichender Genauigkeit eine Herausforderung bleibt." ROCKET-1 setzt daher auf eine neue Art der visuellen Kommunikation zwischen KI-Modellen.
GPT-4o plant, ROCKET-1 führt aus
Das System funktioniert in mehreren Ebenen: GPT-4o arbeitet als übergeordneter "Planer", der komplexe Aufgaben wie "Besorge Obsidian" in Einzelschritte zerlegt. Das multimodale Modell Molmo identifiziert dann die relevanten Objekte in den Bildern durch Koordinatenpunkte. SAM-2 erzeugt aus diesen Punkten präzise Objektmasken und verfolgt die Objekte in Echtzeit. ROCKET-1 selbst ist die ausführende Komponente, die basierend auf diesen Objektmasken und den Anweisungen die tatsächlichen Aktionen in der Spielwelt durchführt - also Tastatur- und Mauseingaben steuert.
Der Ansatz orientiert sich laut dem Team an menschlichem Verhalten. Die Forscher erklären: "Bei der menschlichen Ausführung von Aufgaben, wie dem Greifen von Objekten, stellen sich Menschen nicht vor, wie sie einen Gegenstand halten werden, sondern konzentrieren sich auf das Zielobjekt, während sie sich seiner Griffmöglichkeit nähern." Kurz gesagt: Wir versuchen nicht, uns vorzustellen, wie es wäre, etwas in der Hand zu halten - wir nehmen es einfach mit Hilfe unserer Sinneswahrnehmung auf.
In einer Demo zeigt das Team, wie ein Mensch ROCKET-1 direkt steuern kann: Durch das Klicken auf Objekte in der Spielwelt wird das System zur Interaktion geprompted. In der vom Team vorgeschlagenen hierarchischen Agenten-Struktur, die auf GPT-4o, Molmo und SAM-2 setzt, reduziert sich der menschliche Input auf eine Textanweisung.
Mehrere KI-Modelle arbeiten zusammen
Für das Training nutzte das Forscherteam den "Contractor"-Datensatz von OpenAI, der aus 1,6 Milliarden Einzelbildern menschlichen Spielverhaltens in Minecraft besteht. Die Forscher entwickelten dabei eine spezielle Methode namens "Backward Trajectory Relabeling", um die Trainingsdaten automatisch zu erstellen.
Das System nutzt dafür das KI-Modell SAM-2, um rückwärts durch die Aufzeichnungen zu gehen und automatisch zu erkennen, mit welchen Objekten der Spieler interagiert hat. Diese Objekte werden dann in den vorherigen Frames markiert, wodurch ROCKET-1 lernt, relevante Objekte zu erkennen und mit ihnen zu interagieren.
ROCKET-1: Erhöhter Rechenaufwand
Besonders bei komplexen Langzeitaufgaben in Minecraft zeigt sich die Überlegenheit des Systems. Bei sieben Aufgaben wie der Herstellung von Werkzeugen oder dem Abbau von Ressourcen erreichte ROCKET-1 Erfolgsraten von bis zu 100 Prozent, während andere Systeme oft komplett versagten. Selbst bei komplexeren Aufgaben wie dem Abbau von Diamant oder dem Erschaffen von Obsidian erreichte das System eine Erfolgsrate von 25 bzw. 50 Prozent.
Die Forscher benennen auch die Grenzen von ROCKET-1: "Obwohl ROCKET-1 die Interaktionsfähigkeiten in Minecraft deutlich verbessert, kann es nicht mit Objekten interagieren, die sich außerhalb seines Sichtfelds befinden oder die es noch nicht gesehen hat." Diese Einschränkung führt zu einem erhöhten Rechenaufwand, da die übergeordneten Modelle häufiger eingreifen müssen.
Mehr Informationen und Beispiele gibt es auf der Projektseite auf GitHub.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.