Mini-Bild-KI Meissonic bietet große Bildqualität

Mit nur einer Milliarde Parametern könnte Meissonic die Entwicklung lokaler Text-zu-Bild-Anwendungen vor allem auf mobilen Geräten vorantreiben.
Forschende der Alibaba Group, Skywork AI sowie verschiedener Universitäten haben mit Meissonic ein Open-Source-Modell entwickelt, das durch eine spezielle Transformer-Architektur und fortschrittliche Trainingsmethoden hochauflösende Bilder effizient generieren und bearbeiten können soll. Es ist so klein, dass es auf Gaming-Rechnern und in Zukunft vielleicht sogar Smartphones betrieben werden kann.
Meissonic verwendet den maskierten Bild-Modellierungsansatz, bei dem Teile des Bildes während des Trainings verdeckt oder "maskiert" werden. Das Modell lernt dann, die fehlenden Teile des Bildes basierend auf den sichtbaren Teilen und der Textbeschreibung zu rekonstruieren. Dieser Prozess hilft dem Modell, die Zusammenhänge zwischen verschiedenen Bildelementen und der Textbeschreibung besser zu verstehen.
Zusätzlich nutzt Meissonic eine spezielle Transformer-Architektur, die es ermöglicht, hochauflösende Bilder mit einer Größe von bis zu 1024 × 1024 Pixeln zu generieren. Mit dieser Technik kann Meissonic neben fotorealistischen Motiven auch stilisierte Buchstaben, Memes oder Cartoon-Sticker erzeugen.
Im Gegensatz zu herkömmlichen autoregressiven Modellen, die Bilder sequenziell erzeugen, sagt Meissonic alle Bildtokens gleichzeitig in einem parallelen, iterativen Verfeinerungsprozess vorher.
Dieser nicht-autoregressive Ansatz reduziert laut Paper die Anzahl der Decodierungsschritte im Vergleich zu autoregressiven Methoden um etwa 99 Prozent, was die Bildsynthese erheblich beschleunigt.
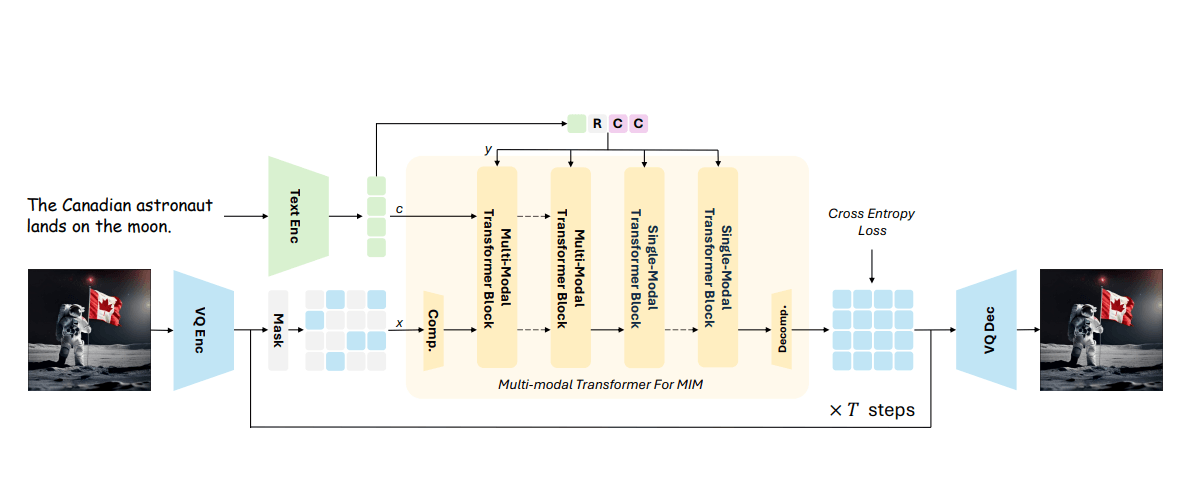
Um die Leistung des maskierten Bild-Modellierungsansatzes zu verbessern, kombiniert Meissonic mehrmodale und monomodale Transformer-Schichten. Die mehrmodalen Schichten erfassen Interaktionen zwischen Text und Bild, während die monomodalen Schichten die visuelle Repräsentation verfeinern. Laut den Forschenden ergibt ein Verhältnis von etwa 1:2 zwischen diesen beiden Schichttypen die optimale Leistung.
Progressives Training mit hochwertigen Daten und Funktionskompressionsschichten
Die Forscher haben das neue Bild-KI-Modell "Meissonic" in vier Schritten trainiert, um hochwertige Bilder zu erzeugen. Zunächst lernte das Modell grundlegende Konzepte aus einem großen, sorgfältig ausgewählten Datensatz mit etwa 200 Millionen Bildern in einer Auflösung von 256 × 256 Pixeln.
Im zweiten Schritt verbesserten die Forscher die Fähigkeit des Modells, lange und detaillierte Textbeschreibungen zu verstehen. Dazu nutzten sie einen stärker gefilterten Datensatz mit etwa zehn Millionen Bild-Text-Paaren und erhöhten die Trainingsauflösung auf 512 × 512 Pixel.
Im dritten Schritt führten die Forscher spezielle Schichten ein, die die Daten komprimieren und dekomprimieren, um den Übergang zu einer höheren Auflösung von 1024 × 1024 Pixeln zu ermöglichen. Diese Schichten reduzieren den Rechenaufwand.
Im letzten Schritt wurde das Modell mit einer niedrigen Lernrate und unter Berücksichtigung von menschlichen Präferenzen verfeinert. Dieser gezielte Anpassungsprozess verbessert die Leistung des Modells bei der Erzeugung hochauflösender und vielfältiger Bilder.
Vielversprechende Ergebnisse in Benchmarks und Anwendungen
In verschiedenen Benchmarks, darunter Human Preference Score v2 (HPSv2) und GenEval, zeigte Meissonic trotz seiner vergleichsweise geringen Größe von nur einer Milliarde Parametern eine überlegene Leistung im Vergleich zu anderen führenden Text-zu-Bild-Modellen. Im HPSv2-Benchmark erzielte Meissonic einen Wert von 28,83 und übertraf damit größere Modelle wie SDXL und DeepFloyd-XL.


Neben der Bildsynthese ist Meissonic auch in der Lage, Bilder ohne zusätzliches Training oder Fine-Tuning per In- und Outpainting zu bearbeiten. Die Forscher:innen geben in ihrem Paper Beispielbilder, in denen sie Hintergründe oder Stil ändern sowie Objekte entfernen oder hinzufügen.

Die Forschenden sehen in ihrem Ansatz das Potenzial, maßgeschneiderte KI-Modelle schneller und kostengünstiger zu entwickeln. Meissonic könnte auch die Entwicklung lokaler Text-zu-Bild-Anwendungen auf mobilen Geräten vorantreiben.
Hier gab es in der Vergangenheit bereits große Fortschritte von Snap und Google, die bislang jedoch nur wenig Anwendung im Nutzer:innenalltag fanden. Auch wenn generative KI immer mehr auf Android-Smartphones und iPhones Einzug hält und kleine Textmodelle teilweise lokal ausgeführt werden, verlassen sich Google und Apple bei der Bildgeneration vorerst weiter auf die Cloud. Ein Modell wie Meissonic zeigt, dass sich das ändern könnte.
Das Modell lässt sich auf Consumer-GPUs mit 8 GB VRAM ausführen. Eine Demo ist auf Hugging Face verfügbar, der Code auf GitHub.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.