Mistral Large 2 soll Meta Llama 3 in Sachen Effizienz schlagen und der LLM-Ozean wird roter
Das französische KI-Unternehmen Mistral AI veröffentlicht mit Large 2 ein neues Sprachmodell, das bei ähnlicher Leistung effizienter sein soll als das gerade erst vorgestellte Llama 3 von Meta.
Das französische KI-Unternehmen Mistral AI hat die zweite Generation seines Flaggschiff-Modells Mistral Large vorgestellt. Im Vergleich zu seinem Vorgänger soll der neue Mistral Large 2 deutlich leistungsfähiger in den Bereichen Codegenerierung, Mathematik und Logik sein und eine verbesserte Mehrsprachigkeit sowie erweiterte Funktionsaufrufe bieten.
Mit einem Kontextfenster von 128.000 Token unterstützt Mistral Large 2 Dutzende Sprachen, darunter Französisch, Deutsch, Spanisch, Italienisch, Portugiesisch, Arabisch, Hindi, Russisch, Chinesisch, Japanisch und Koreanisch, sowie über 80 Programmiersprachen wie Python, Java, C, C++, JavaScript und Bash.
Laut Mistral setzt Large 2 neue Maßstäbe in Bezug auf das Verhältnis von Leistung zu Bereitstellungskosten. Im oft zitierten LLM-Benchmark MMLU erreicht die vortrainierte Version eine Genauigkeit von 84,0 Prozent und setze damit einen neuen Bestwert "auf der Pareto-Front der Leistung/Kosten offener Modelle."
Bei Code übertrifft es das vorherige Mistral Large deutlich und liegt gleichauf mit führenden Modellen wie GPT-4o, Claude 3.5 Sonnet und Llama 3 405B.
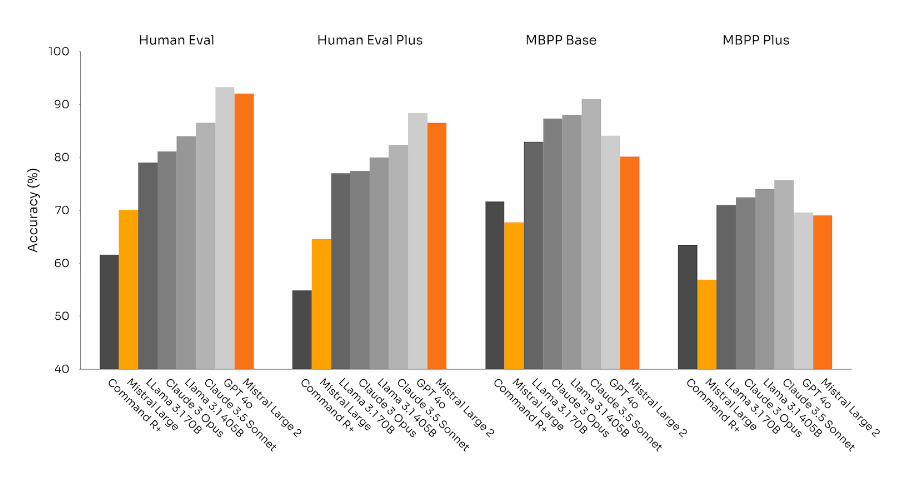
Im Vergleich zum neuen Llama-Modell braucht es dafür nur etwa gut ein Viertel der Parameter (123B vs. 405B).
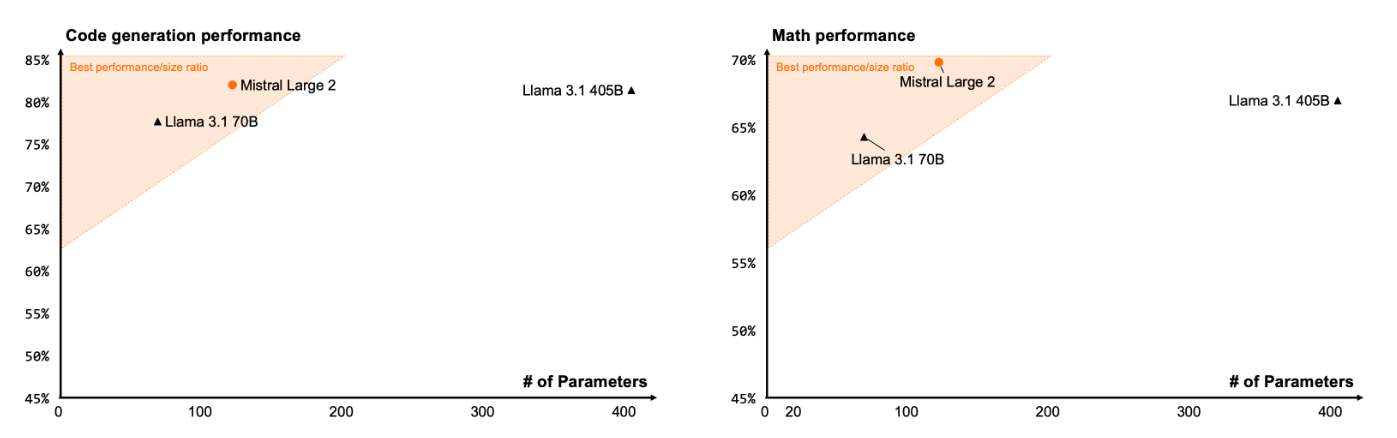
Ein Schwerpunkt bei der Entwicklung lag auf der Verbesserung der Reasoning-Fähigkeiten. Ziel war es, die Tendenz des Modells zu minimieren, plausibel klingende, aber sachlich falsche oder irrelevante Informationen zu "halluzinieren".
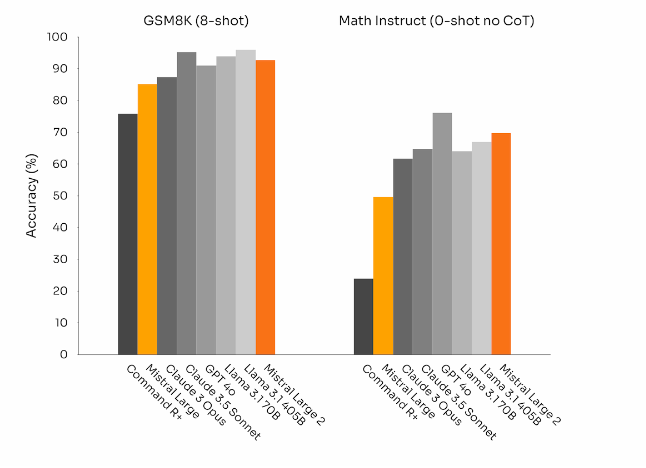
Laut Mistral wurde Large 2 so optimiert, dass es vorsichtiger und kritischer in seinen Antworten ist und zugibt, wenn es keine Lösung finden kann oder nicht über genügend Informationen verfügt, um eine sichere Antwort zu geben. Dieses Bemühen um Genauigkeit spiegele sich in der verbesserten Leistung bei mathematischen Aufgaben wider. Allerdings erreicht Large 2 auch hier keine neuen Spitzenleistungen.
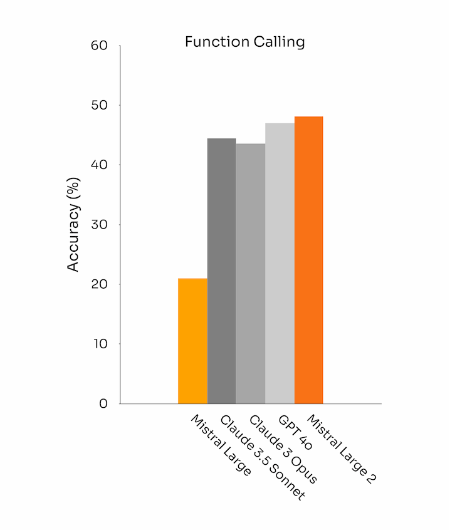
Das Modell verfügt auch über verbesserte Funktionsaufruf- und Informationsabruffähigkeiten. Es wurde darauf trainiert, sowohl parallele als auch sequentielle Funktionsaufrufe zuverlässig auszuführen. Damit soll Large 2 als Basis für komplexe Geschäftsanwendungen dienen können.
Mistral Large 2 ist ab sofort über die Mistral-Plattform, Azure AI Studio, Amazon Bedrock, IBM watsonx.ai und Google Vertex AI verfügbar. Die Gewichte für das Instruktionsmodell sind hier verfügbar (228GB) und auf HuggingFace gehostet.
Das Modell ist unter der Mistral Research License veröffentlicht, die die Nutzung und Modifikation für Forschung und nicht-kommerzielle Zwecke erlaubt. Für die kommerzielle Nutzung mit eigenem Hosting ist eine Mistral Commercial License erforderlich. Mit 123 Milliarden Parametern ist es für die Inferenz auf einem einzelnen Knoten mit Anwendungen mit langem Kontext ausgelegt.
Der LLM-Ozean färbt sich rot
Dass Mistral nur einen Tag nach Llama 3 405B bereits das nächste große LLM am Start hat, das bei den Fähigkeiten inkrementelle Updates bietet, dafür aber mit Preis und Effizienz punktet, zeigt, dass sich der LLM-Markt langsam in einen "roten Ozean" verwandelt: Immer mehr Modelle konkurrieren mit ähnlicher Leistung um dieselben Kunden und Anwendungen. Die Stellhebel sind seit Monaten Effizienz und Preise, die stark sinken, während die Entwicklungskosten hoch bleiben.
Die Frage ist, ob es einem Modellanbieter gelingt, durch ein signifikantes Upgrade im Bereich Reasoning aus dem roten Ozean auszubrechen, bestehende Geschäftsfelder auszubauen und neue zu erschließen. Andernfalls dürfte der noch junge Markt schon bald vor einer ernsthaften Bewährungsprobe stehen, wenn er den hohen Bewertungen der Investoren gerecht werden will.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.