MIT-Forscher beschleunigen und verbessern Bild-KI mit neuem Ansatz

Bisher konnten Diffusionsmodelle nur mit vielen Iterationen qualitativ hochwertige Bilder erzeugen. Einem Team des MIT ist es nun gelungen, den Prozess auf einen einzigen Schritt zu komprimieren - mit einer Qualität, die mit Stable Diffusion vergleichbar ist.
Wissenschaftler des MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) haben eine neue Methode entwickelt, mit der sich die Bilderzeugung mit Diffusionsmodellen wie Stable Diffusion oder DALL-E dramatisch beschleunigen lässt.
Statt der bisher erforderlichen 20 oder mehr Iterationsschritte benötigt das neue Verfahren namens Distribution Matching Distillation (DMD) nur noch einen einzigen Schritt.
Ähnliche Experimente wurden bereits durchgeführt, auch direkt von Stability AI, der Firma hinter Stable Diffusion. Die Qualität der Bilder, die mit der MIT-Methode erzeugt werden, soll jedoch mit den rechenintensiveren Verfahren vergleichbar sein.
"Diese Weiterentwicklung reduziert nicht nur die Rechenzeit erheblich, sondern behält auch die Qualität der erzeugten visuellen Inhalte bei oder übertrifft sie sogar", sagt Tianwei Yin, Doktorand in Elektrotechnik und Informatik am MIT und Hauptautor der Studie.
Diffusionsmodelle erzeugen Bilder, indem sie einem verrauschten Ausgangszustand schrittweise Struktur hinzufügen, bis ein klares Bild entsteht. Dieser Prozess erfordert in der Regel zahlreiche Iterationen für ein gelungenes Bild.
Der neue Ansatz des MIT basiert auf einem "Lehrer-Schüler"-Modell: Ein neues KI-Modell lernt, das Verhalten komplexerer Originalmodelle zur Bilderzeugung nachzuahmen. Dabei kombiniert DMD die Bewertungsprinzipien von Generative Adversarial Networks (GANs) mit denen von Diffusionsmodellen.
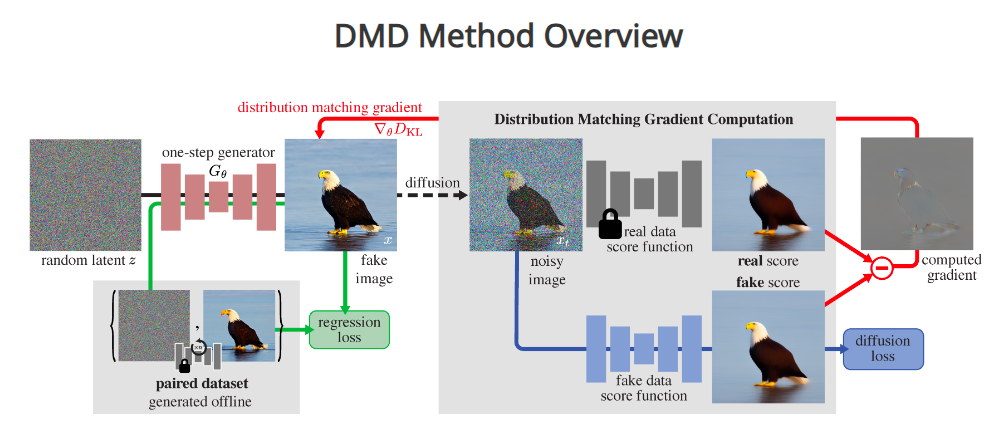
Für das neue Schülermodell verwendeten die Forscher vortrainierte Netze, was den Prozess vereinfachte. Indem sie die Parameter der ursprünglichen Modelle kopierten und verfeinerten, erreichten sie eine schnelle Trainingskonvergenz des neuen Modells. Auf diese Weise bleibt die architektonische Basis erhalten.
"Das ermöglicht die Kombination mit anderen Systemoptimierungen, die auf der ursprünglichen Architektur basieren, um den Erstellungsprozess weiter zu beschleunigen", sagt Yin.
In Tests hat DMD durchweg gute Ergebnisse erzielt. Bei der Generierung von Bildern aus bestimmten Klassen des ImageNet-Datensatzes ist DMD die erste einstufige Diffusionstechnik, die Bilder erzeugt, die den Bildern der komplexeren Originalmodelle nahezu ebenbürtig sind.


Die Fréchet Inception Distance (FID) betrug nur 0,3. Sie misst die Qualität und Vielfalt der generierten Bilder anhand der statistischen Verteilung von Merkmalen wie Farben, Texturen und Formen der generierten Bilder im Vergleich zu realen Bildern. Ein niedriger FID-Wert weist auf eine höhere Qualität und Ähnlichkeit der generierten Bilder mit den realen Bildern hin.
Auch bei der Text-zu-Bild-Generierung im industriellen Maßstab erreicht DMD bei der einstufigen Generierung den Stand der Technik. Bei anspruchsvolleren Text-zu-Bild-Anwendungen gibt es noch eine kleine Qualitätslücke und Raum für Verbesserungen.
Die Leistung der mit DMD erzeugten Bilder hängt auch von den Fähigkeiten des während des Distillationsprozesses verwendeten Lehrermodells ab. In seiner derzeitigen Form, mit Stable Diffusion v1.5 als Lehrermodell, erbt der Schüler Einschränkungen wie die Unfähigkeit, detaillierten Text oder nur "kleine Gesichter" zu generieren.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.