MLPerf: Nvidia sieht sich an der Spitze in Leistung und Vielseitigkeit

Nvidia führt auch den diesjährigen MLPerf Inference Benchmark an. Neue Daten zeigen Leistungssprünge bei Hopper und neuer Hardware.
Im Benchmark MLPerf messen sich Hardwarehersteller und Dienstleister mit ihren KI-Systemen. Der Test wird von MLCommons abgewickelt und zielt auf einen transparenten Vergleich unterschiedlicher Chip-Architekturen und Systemvarianten ab.
Heute hat MLPerf neue Ergebnisse des MLPerf Inference 3.0 Benchmarks veröffentlicht. Neu ist eine Netzwerkumgebung, in der die KI-Leistung verschiedener Systeme unter realistischeren Bedingungen getestet wird: Die Daten werden zu einem Inferenzserver gestreamt. Der Test soll so genauer abbilden, wie Daten im realen Einsatz zum KI-Beschleuniger gelangen und ausgegeben werden, und so Engpässe in Netzwerken aufdecken.
Nvidia Hopper legt im Vergleich zu Vorjahr deutlich zu
Laut Nvidia haben die H100 Tensor Core Grafikprozessoren in DGX H100 Systemen durch Softwareoptimierungen bis zu 54 Prozent mehr Inferenzleistung als im Vorjahr. Dieser Sprung findet sich in der RetinaNet Inferenz, andere Modelle wie BERT mit 99 % Genauigkeit laufen 12 % schneller, ResNet-50 13 % und 3D U-Net, das z.B. in der Medizin eingesetzt wird, 31 % schneller.
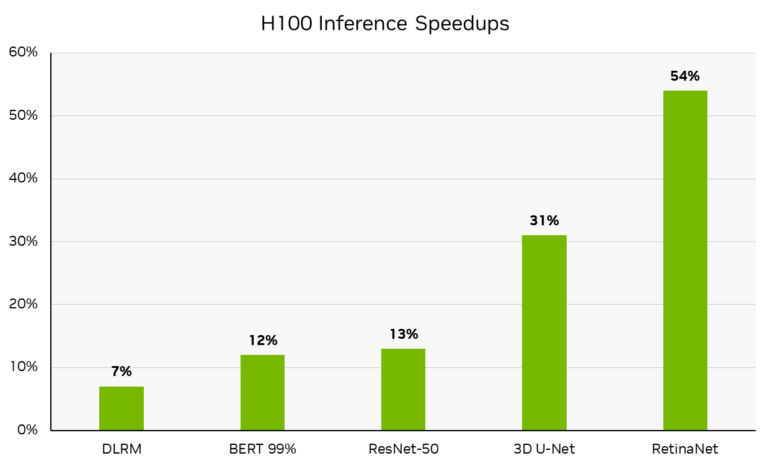
Bei der Präsentation der Ergebnisse betonte Nvidia, dass man sich klar an der Spitze der Performance sieht, aber auch die ebenso wichtige Führungsposition bei der vielseitigen Einsetzbarkeit der eigenen Architektur. Nvidia ist das einzige Unternehmen, das für alle Aufgaben in MLPerf Inference 3.0 Ergebnisse vorgelegt hat.
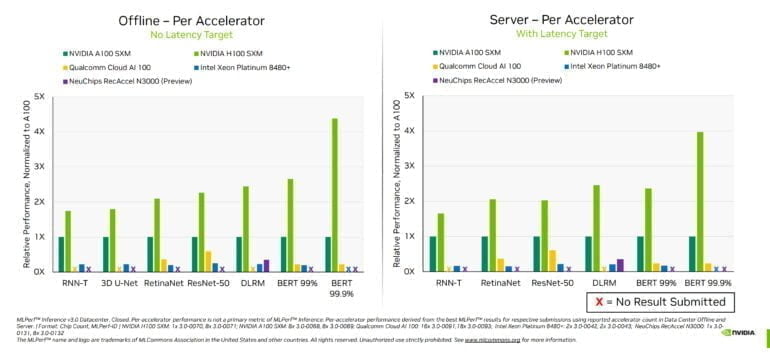
Im Vergleich zu einer A100-GPU ist die H100-GPU dank der Transformer-Engine auch deutlich stärker bei der Inferenz von Transformer-Modellen mit hoher Genauigkeit wie BERT 99.9. Hier liefert die H100 eine mehr als viermal so hohe Leistung.
Die Karte verspricht daher große Leistungsgewinne für viele generative KI-Modelle, die etwa Texte, Bilder oder 3D-Modelle generieren.
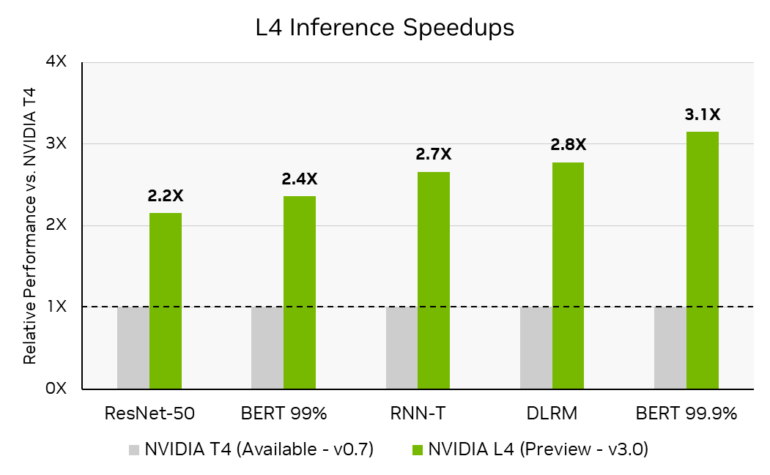
Neue L4-Karte bis zu 3-mal schneller als Vorgängerin
Neu im Benchmark ist die L4 Tensor GPU von Nvidia, die das Unternehmen erst kürzlich auf der GTC vorgestellt hat. Die Karte ist bereits bei einigen Cloud-Anbietern erhältlich und liefert in den Benchmarks eine 2,2- bis 3,1-fach höhere Inferenzleistung als das Vorgängermodell T4.
Nvidias Jetson AGX Orin für den Edge ist dank zahlreicher Verbesserungen zudem bis zu 63 Prozent energieeffizienter und bis zu 81 Prozent leistungsfähiger als noch im letzten Jahr.
Im neu hinzugekommenen Netzwerktest lieferten die DGX A100-Systeme von Nvidia beim BERT-Modell 96 Prozent der maximalen lokalen Leistung - also der Leistung, die das System liefert, wenn das Modell lokal läuft. Laut Nvidia liegt die Ursache für den leichten Leistungsverlust in der Wartezeit der CPUs. Im RestNet-50-Test, der ausschließlich auf GPUs durchgeführt wird, erreichten die DGX-Systeme 100 Prozent der lokalen Leistung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.