Nächste Studie äußert Zweifel an "Denk"fähigkeit von Reasoning-Modellen

Eine neue Studie von Forschern der Arizona State University stellt die scheinbar menschenähnlichen Denkprozesse von KI-Modellen infrage. Die Autoren zeigen, dass vermeintliche Denkprozesse oft an Trainingsmuster gebunden sind und schnell zusammenbrechen.
Mit der sogenannten Chain-of-Thought-Methode (CoT) sollen große Sprachmodelle (LLMs) zu menschenähnlichem Denken befähigt werden. Indem sie komplexe Probleme in logische Zwischenschritte zerlegen, verbessern sie ihre Leistung bei Aufgaben, die Schlussfolgerungen, Mathematik oder – im Optimalfall – gesunden Menschenverstand erfordern.
Der Erfolg dieser Techniken hat manche zu der Annahme verleitet, dass es sich dabei um ein Anzeichen für emergentes, menschenähnliches Denken in LLMs handelt, das mit mehr Rechenleistung skaliert und generalisiert werden kann. Also der nächste große Durchbruch in der KI-Entwicklung.
Laut einer neuen Arbeit der Arizona State University ist dieses Bild jedoch trügerisch. Chain‑of‑Thought‑Reasoning erscheine "als eine fragile Fata Morgana", die in Verteilungen funktioniere, die der Trainingsverteilung nahekommen, und bei moderaten Verschiebungen verschwinde, heißt es im Preprint "Is Chain‑of‑Thought Reasoning of LLMs a Mirage? A Data Distribution Lens".
Eine Frage der Datenverteilung, nicht der Intelligenz
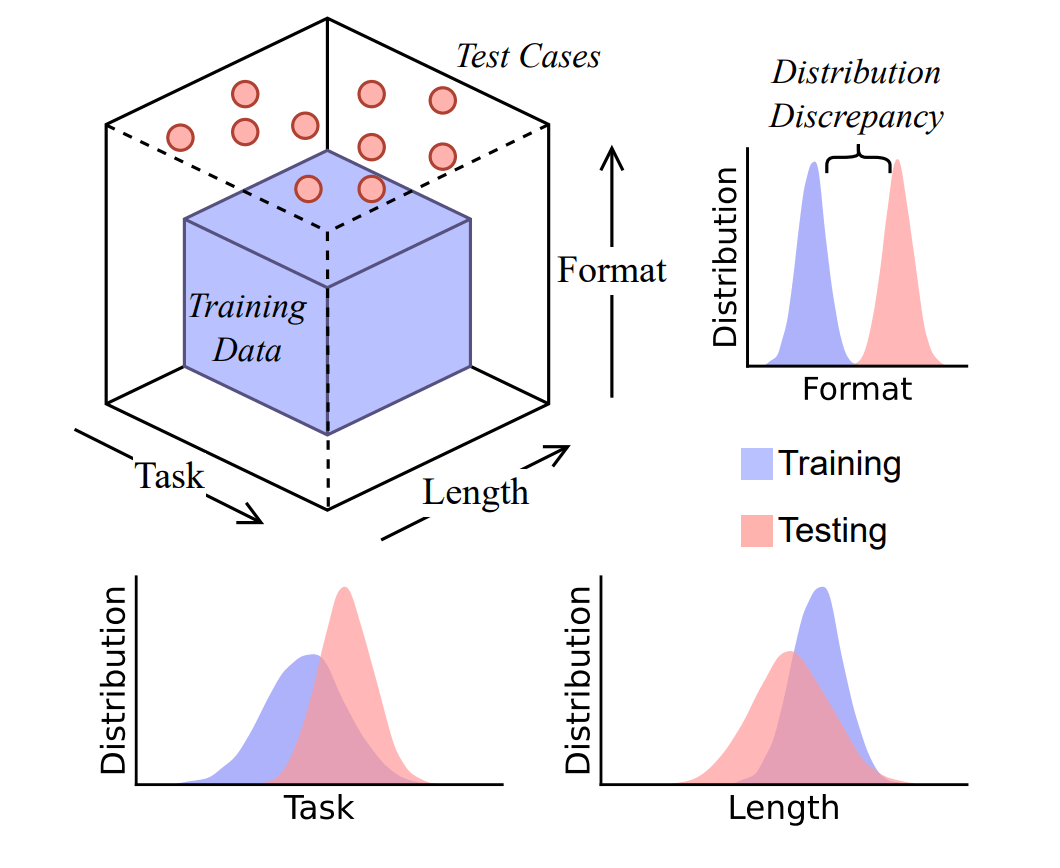
Die Forscher argumentieren, dass die Effektivität der Denkschritte grundsätzlich durch die Diskrepanz zwischen Trainings- und Testverteilung begrenzt ist: Je ähnlicher die Testanfrage den im Training gesehenen Mustern ist, desto eher gelingen passende Denkschritte; bereits bei moderaten Verteilungsverschiebungen wird das Verhalten fragil und bricht häufig ein.
Um diese Hypothese zu testen, entwickelten die Forscher DataAlchemy, eine kontrollierte Umgebung, in der sie ein Sprachmodell von Grund auf trainierten. In diesem isolierten Rahmen untersuchten sie die Robustheit von CoT systematisch entlang dreier kritischer Dimensionen: Aufgabe, Länge und Format.
Die getesteten Denkaufgaben waren simple, zyklische mathematische Transformationen. Die beiden Hauptregeln waren die ROT-Transformation, bei der jeder Buchstabe im Alphabet um eine feste Anzahl von Stellen verschoben wird (zum Beispiel wird aus A mit einer Verschiebung um 13 Stellen ein N, aus P ein C) und eine Verschiebung, bei der die Buchstaben des Wortes rotiert werden (z. B. wird APPLE zu EAPPL).
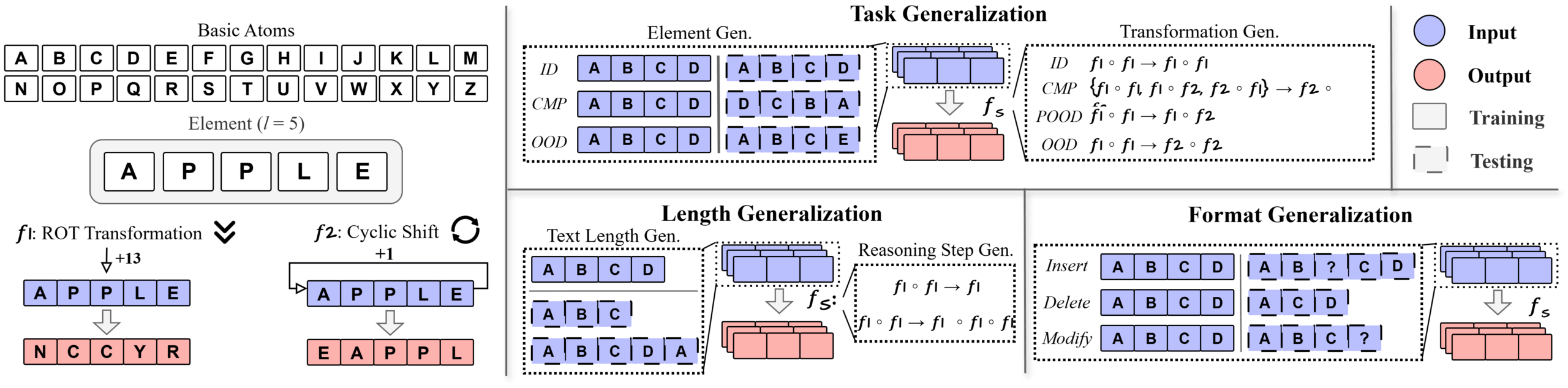
Nachdem das Modell gelernt hatte, diese Regeln anzuwenden, wurde es mit gezielt veränderten Testdaten konfrontiert. So wurde es etwa nur auf eine Regel trainiert und dann mit einer gänzlich neuen konfrontiert. Oder es wurde ausschließlich mit Wörtern der Länge 4 trainiert und dann mit Wörtern der Länge 3 oder 5 getestet.
Die Ergebnisse der Studie zeigen, dass das Modell bereits bei neuen Aufgabenstrukturen oder unbekannten Transformationen scheitert und statt echter Logik lediglich bekannte Muster reproduziert. Auch bei veränderten Längen der Denkschritte oder Eingaben bricht die Leistung ein, da das Modell versucht, die gewohnte Schrittzahl durch willkürliches Hinzufügen oder Entfernen von Zeichen zu erzwingen.
Selbst oberflächliche Änderungen im Format der Anfrage – etwa das Einfügen von Störzeichen (noise tokens) vor den eigentlichen Zeichen – reichen aus, um das Chain-of-Thought-Reasoning des Modells negativ zu beeinflussen.
Nach Einschätzung der ASU-Autoren sollten CoT-Ausgaben daher nicht mit verlässlichem Denken verwechselt werden, insbesondere in kritischen Anwendungsbereichen. Die Fähigkeit der Modelle, plausibel klingenden, aber logisch fehlerhaften Unsinn zu produzieren ("fluent nonsense"), berge erhebliche Risiken.
Die Forscher sehen Reasoning-Modelle eher als "hochentwickelte Simulatoren von denkähnlichem Text" als prinzipientreue Denker. Ein systematisches Verständnis dafür, wann diese Logikketten versagen, fehle. Es sei ein "Mysterium".
Die Forscher illustrieren diese trügerische Kohärenz an einem Beispiel: Auf die Frage, ob der Gründungstag der USA im Jahr 1776 in einem Schaltjahr lag, leitet ein Google-Gemini-Modell zunächst korrekt ab: "1776 ist durch 4 teilbar, aber es ist kein Jahrhundertjahr, also ist es ein Schaltjahr."
Unmittelbar danach zieht es jedoch die widersprüchliche Schlussfolgerung: "Daher war der Tag der Gründung der USA in einem normalen Jahr." Das Modell behauptet also, 1776 sei ein Schaltjahr, nur um im nächsten Satz das Gegenteil zu folgern. Dieses Ergebnis sei sprachlich plausibel, aber logisch inkonsistent.
(Hinweis aus eigenem Test: GPT-5-Thinking löst diese Aufgabe souverän, ebenso wie Gemini 2.5 Pro. Gemini 2.5 Flash scheitert an der korrekten Schaltjahrrechnung, zeigte dabei aber keinen Gedankengang an.)
Erstautor Chengshuai Zhao kündigte das Paper bei X an und veröffentlicht Code und Daten auf GitHub, zudem gibt es eine Paper‑Seite bei Hugging Face.
Logikfähigkeiten von "Reasoning"-Modellen stehen weiter zur Debatte
Die Erkenntnisse der Studie fügen sich in eine Reihe ähnlicher Beobachtungen ein. Apples viel diskutiertes Paper "The Illusion of Thinking" argumentiert, dass LLMs bei symbolischer Planung scheitern und Muster statt Strukturen lernen; Kritik bemängelte jedoch eine zu binäre Interpretation und verweist darauf, dass Modelle Aufgaben funktional per Code oder durch andere Werkzeuge lösen können.
Eine Analyse der Tsinghua University und der Shanghai Jiao Tong University zeigt, dass Reinforcement Learning mit verifizierbaren Belohnungen (RLVR) zwar die Trefferquote beim ersten Versuch erhöht, aber keine neuen Problemlösestrategien erschließt; es fokussiert bekannte Pfade und verringert die Vielfalt.
Eine Studie der New York University testet Zero‑Shot das Befolgen formaler Grammatiken: Auch spezialisierte Reasoning‑Modelle brechen bei steigender Komplexität ein und zeigen "Underthinking" – weniger statt mehr Denk‑Zwischenschritte bei schwierigen Fällen. Die Autoren argumentieren daher, dass zukünftige Sprachmodelle zur Bewältigung solcher Aufgaben entweder deutlich mehr Rechenleistung oder grundlegend effizientere Lösungsstrategien benötigen werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.