Neue KI-Prompting-Technik verbessert Genauigkeit und Nachvollziehbarkeit von LLMs

Eine neue Prompting-Technik namens "Highlighted Chain of Thought" (HoT) soll große Sprachmodelle dazu bringen, ihre Antworten besser zu belegen und für Menschen nachvollziehbarer zu machen.
Die Technik besteht aus zwei Hauptschritten: Zunächst reformatiert das KI-Modell die ursprüngliche Frage und hebt Schlüsselfakten mit XML-Tags hervor. Anschließend generiert es eine Antwort, die mit entsprechenden Tags versehen ist, um auf die markierten Fakten in der Frage zu verweisen.
Das zwinge die Modelle, die Fakten der Frage besser zu berücksichtigen und reduziere so möglicherweise Halluzinationen, erklären die Forscher. Gleichzeitig helfen die farbigen Hervorhebungen den Menschen, die Antworten der KI schneller zu überprüfen.

Für ihre Experimente nutzten die Wissenschaftlerinnen und Wissenschaftler insgesamt 15 von Menschen annotierte Beispielpaare (Frage-Antwort-Paare), um KI-Modelle mittels Prompts darauf zu trainieren, selbstständig Hervorhebungen zu erzeugen.
HoT verbessert laut den Forschern die Genauigkeit der KI-Modelle über verschiedene Aufgabentypen hinweg. In der Spitze konnte das Prompting-Prinzip je nach Modell und Benchmark Verbesserungen von bis zu 15 Prozent erzielen.
Bei arithmetischen Aufgaben stieg die Genauigkeit durchschnittlich um 1,6 Prozentpunkte, bei Frage-Antwort-Aufgaben um 2,58 Punkte und bei logischen Schlussfolgerungen um 2,53 Punkte im Vergleich zur herkömmlichen Chain-of-Thought-Methode (CoT), die auch aktuellen Reasoning-Modellen wie OpenAI o3 zugrunde liegt.
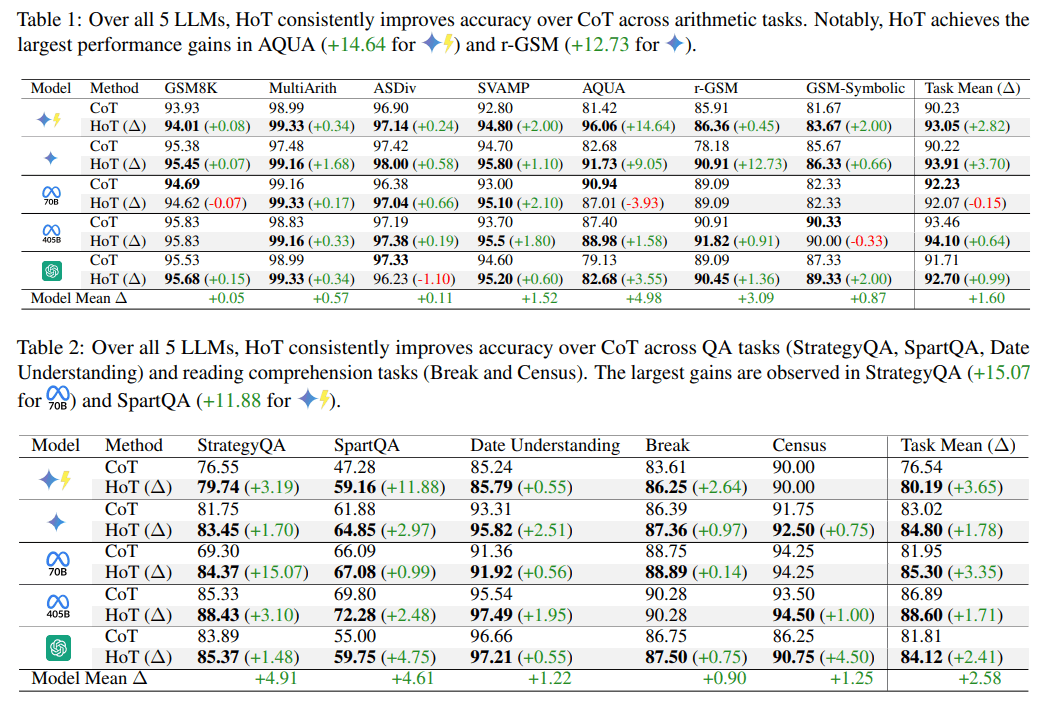
Die Wissenschaftler testeten HoT mit fünf verschiedenen KI-Modellen, darunter GPT-4o, Gemini-1.5-Pro, Gemini-1.5-Flash sowie Llama-3.1-70B und Llama-3.1-405B. Die Tests umfassten 17 verschiedene Aufgabentypen aus den Bereichen Arithmetik, Leseverständnis und logisches Denken.
Reasoning-Modelle profitierten in den Tests kaum oder nicht von HoT, im Gegenteil, Deepseek-R1 schnitt sogar etwas schlechter ab. Die Wissenschaftler führen das auf das Beispiel-Prompting zurück, das bei Reasoning-Modellen zu schlechteren Ergebnissen führen kann.
Schnellere, aber nicht immer bessere Überprüfung
Tests mit menschlichen Nutzern ergaben, dass diese mit den hervorgehobenen Antworten rund 25 Prozent weniger Zeit für die Überprüfung benötigten. Allerdings führten die Hervorhebungen auch dazu, dass die Benutzer den KI-Antworten eher vertrauten, auch wenn diese falsch waren.
Bei richtigen Antworten lag die Erkennungsrate mit Hervorhebungen bei 84,5 Prozent, ohne Hervorhebungen bei 78,8 Prozent. Bei falschen Antworten hingegen sank die Erkennungsrate von 72,2 auf 54,8 Prozent, wenn Hervorhebungen vorhanden waren. Tests mit KI-Modellen als Prüfer zeigten keine generelle Verbesserung.

Dennoch sehen die Forscher großes Potenzial in der Technologie: HoT könne ein Schritt sein, um KI-Systeme transparenter und verständlicher zu machen, so ihr Fazit. Allerdings müsse noch weiter erforscht werden, wie sich die Hervorhebungen auf das Vertrauen der Nutzer auswirken.
Trotz der vielversprechenden Ergebnisse hat die HoT-Methode auch Einschränkungen. Bei kleineren Modellen wie Llama-3.1-8B und Qwen-2.5-Coder-32B zeigt HoT keine konsistenten Verbesserungen. Diese Modelle haben Schwierigkeiten, den Tagging-Anweisungen zu folgen, und tendieren dazu, berechnete Ergebnisse innerhalb der Gedankenketten zu markieren oder die Beispiele zu wiederholen.
Außerdem kann das Verschieben von Tags in der Antwort zu zufälligen Phrasen die Genauigkeit erheblich beeinträchtigen, was die Bedeutung der Übereinstimmung zwischen Tags in Fragen und Antworten unterstreicht.
Für die Zukunft planen die Wissenschaftler, KI-Modelle direkt für die Generierung von HoT-Antworten zu trainieren, anstatt sich auf Beispiele im Prompt zu verlassen. Dies könnte die Methode noch effektiver machen und breiter anwendbar.
Die Forschungsarbeit wurde auf dem Preprint-Server arXiv veröffentlicht und auf einer Projektseite. Die Forscher stellen ihren Code und ihre Daten bei Github zur Verfügung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.