
KI-Forschende von Microsoft zeigen NÜWA, ein KI-Tausendsassa der Bildmanipulation, der mit OpenAIs DALL-E mithalten kann. Besonders beeindruckend ist die Generierung kurzer Videos anhand von Textbeschreibungen.
Anfang des Jahres zeigte OpenAI DALL-E, ein multimodales KI-Modell, das aus Textbeschreibungen Bilder generiert. In Kombination mit dem ebenfalls vorgestellten CLIP, das als Qualitätsfilter dient, entstanden so Originalbilder von teils beeindruckender Qualität und Kreativität – Avocado-Stühle oder Pinguine aus Knoblauch seien an dieser Stelle genannt.
Die angesprochene Multimodalität ist die Besonderheit an DALL-E: Die KI wurde mit Bildern und Texten trainiert. Diese Verknüpfung von Bild und Text verhilft ihr zu einem besseren Verständnis von Motiven und so letztlich zu hochwertigeren Ergebnissen.
Ein neues KI-System von Microsoft geht jetzt einen Schritt weiter: NÜWA wurde neben Texten und Bildern auch mit Videos trainiert.
NÜWA macht aus Texten Bilder und Videos
Das KI-System trägt den Namen der Schöpfergöttin Nüwa aus der frühchinesischen Mythologie. Ganz so mächtig ist die Künstliche Intelligenz zwar nicht, doch die Forschenden zeigen, dass das umfassende Training mit Text, Bild und Video ein leistungsfähiges KI-Modell geschaffen hat.
Für die Architektur setzt das Team auf eine Reihe verschiedener Encoder, die auf die jeweiligen Dimensionen der Inputs zugeschnitten sind und diese in Tokens verwandeln. Die einzelnen Tokens werden anschließend von Transformer-Modulen verarbeitet und vom Decoder in Bildausgaben verwandelt.
Besonders beeindruckend ist, dass NÜWA anhand von Textbeschreibungen kurze Videos generieren kann. | Video: Microsoft
Microsofts Forschende trainierten NÜWA für Text-zu-Bild-Generierung, Video-Vervollständigung und Text-zu-Video-Generierung mit 2,9 Millionen Text-Bild-Paaren, knapp 720000 Videos und etwa 240000 Text-Video-Paaren. Das finale KI-Modell hat eine Größe von 870 Millionen Parametern. Das KI-Training auf 64 Nvidia A100 GPUs dauerte rund zwei Wochen.
NÜWA schlägt bisherige KI-Modelle
Nach diesem umfassenden multimodalen Training kann NÜWA Bilder und Videos aus Textbeschreibungen generieren und vorhandene Videos allein anhand von Texteingaben fortführen.
Bei der Fortführung von Videos lässt NÜWA eine gezielte Steuerung per Texteingabe zu. | Video: Microsoft, Wu et al.
Die Qualität der generierten Bilder und Videos übertrifft häufig bisherige KI-Modelle inklusive der aktuell verfügbaren DALL-E-Versionen. Bildfehler oder unsinnige Details treten jedoch auch bei NÜWA noch auf.

Die Forschenden trainierten NÜWA zusätzlich auf weitere Bildaufgaben und konnten zeigen, dass ihr Modell bessere Ergebnisse liefert als spezialisierte Modelle. Zu diesen Aufgaben gehören Sketch-zu-Bild, Sketch-zu-Video und Bildergänzung.
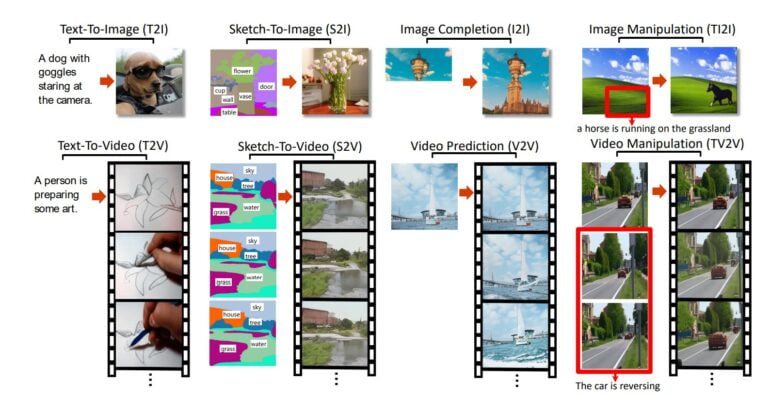
Das Entwicklungsteam bezeichnet NÜWA als den ersten Schritt zum Aufbau einer KI-Plattform, "welche die Schaffung visueller Welten ermöglicht und Content-Creator unterstützt". Ob der Code veröffentlicht wird, ist nicht bekannt.
Mehr Bild- und Videobeispiele gibt es im Github des NÜWA-Projekts.



