Neue Prompting-Methode kann logisches Schlussfolgern von LLMs verbessern

Eine neue Methode ermöglicht es Sprachmodellen, irrelevante Informationen in Textaufgaben zu erkennen und herauszufiltern. Dadurch verbessert sich die Genauigkeit beim logischen Schlussfolgern deutlich, wie eine Studie zeigt. Allerdings gibt es noch Limitierungen.
Forscher der Guilin University of Electronic Technology und weiterer chinesischer Forschungseinrichtungen haben eine Methode entwickelt, mit der Sprachmodelle irrelevante Informationen in Textaufgaben erkennen und herausfiltern können. Dadurch verbessert sich die Genauigkeit beim logischen Schlussfolgern deutlich, wie eine Studie zeigt.
Die Wissenschaftler erstellten dazu den Datensatz GSMIR mit 500 Mathematikaufgaben für die Grundschule, in die sie gezielt irrelevante Sätze einfügten. Der GSMIR-Datensatz ist aus dem GSM8K-Datensatz abgeleitet.
Bei Tests auf dem GSMIR-Datensatz stellten die Forscher fest, dass die Large Language Models (LLMs) GPT-3.5-Turbo und GPT-3.5-Turbo-16k in bis zu 74,9 Prozent der Fälle der Lage sind, irrelevante Informationen zu erkennen. Allerdings gelingt es den Modellen nicht, diese Informationen selbstständig auszuschließen, sobald sie identifiziert wurden.
Irrelevante Informationen erkennen, filtern - und erst dann antworten
Um dieses Problem zu lösen, entwickelten die Wissenschaftler die zweistufige Methode "Analysis to Filtration Prompting" (ATF). Zuerst analysiert das Modell die Aufgabe und identifiziert irrelevante Informationen, indem es jeden Teilsatz einzeln analysiert. Dann filtert es diese Informationen heraus, bevor es mit dem eigentlichen logischen Schlussfolgern beginnt.
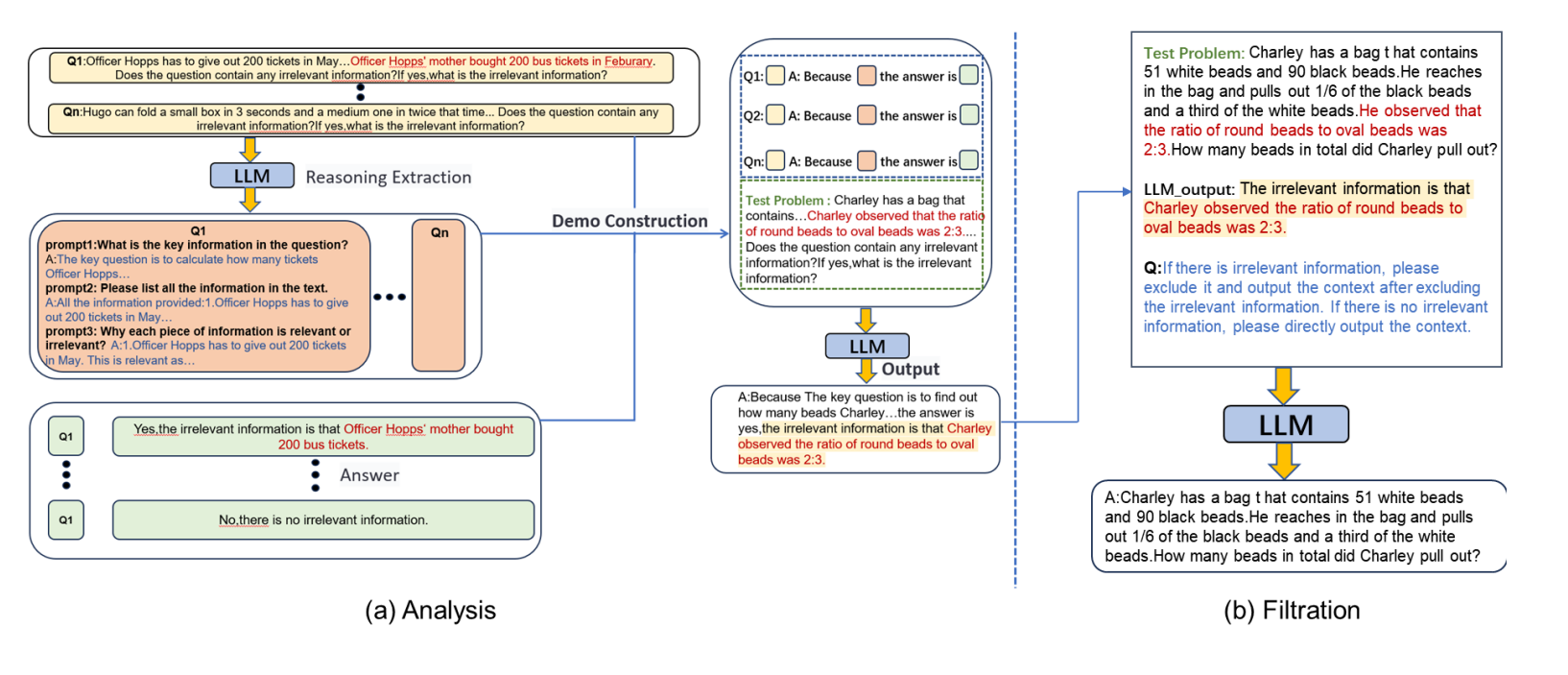
Mit ATF näherte sich die Genauigkeit der LLMs beim Lösen der Aufgaben mit irrelevanten Informationen der Genauigkeit bei den ursprünglichen Aufgaben ohne irrelevante Informationen an. Die Methode funktionierte mit allen getesteten Prompting-Techniken.
Besonders gut schnitt die Kombination von ATF mit "Chain-of-Thought Prompting" (COT) ab: Hier stieg die Genauigkeit von GPT-3.5-Turbo von 50,2 Prozent ohne ATF auf 74,9 Prozent mit ATF. Das entspricht einer Verbesserung um fast 25 Prozentpunkte.
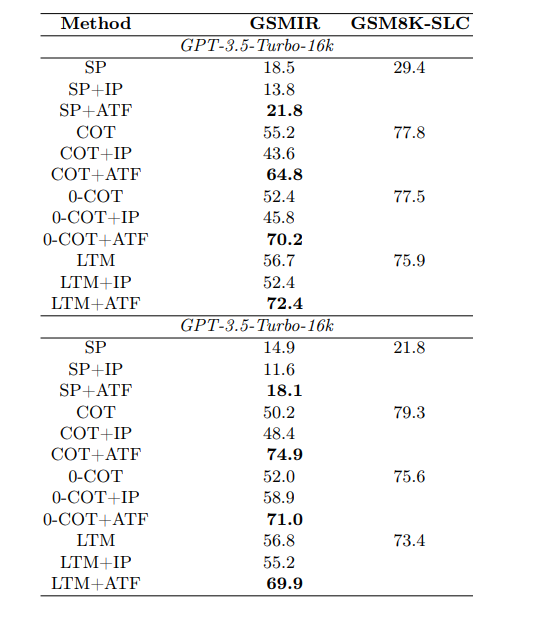
Die geringste Verbesserung gab es bei der Kombination von ATF mit der "Standard Prompting" (SP) Methode. Hier stieg die Genauigkeit nur um 3,3 Prozentpunkte. Die Forscher vermuten, dass dies daran liegt, dass die Genauigkeit von SP auf den ursprünglichen Fragen ohne irrelevante Informationen mit 18,5 Prozent bereits sehr niedrig war. Die meisten Fehler entstanden hier wohl durch Rechenfehler und nicht durch irrelevante Informationen.
Da die ATF-Methode speziell darauf abzielt, die Auswirkungen irrelevanter Informationen zu reduzieren, nicht aber die allgemeine Rechenfähigkeit der LLMs zu verbessern, war der Effekt von ATF in Kombination mit SP begrenzt. Bei anderen Prompting-Techniken wie COT, die die LLMs besser beim korrekten Lösen der Aufgaben unterstützen, konnte ATF die Leistung deutlicher verbessern, da hier irrelevante Informationen einen größeren Anteil an den Fehlern hatten.
Die Studie hat jedoch Limitierungen. So verwendeten die Forscher für ihre Experimente lediglich GPT-3.5. Leistungsfähigere Sprachmodelle könnten irrelevante Informationen womöglich noch besser erkennen. Außerdem untersuchte die Studie nur Aufgaben, die eine einzige irrelevante Information enthielten. In der Praxis können Problembeschreibungen aber mehrere solcher Störfaktoren aufweisen.
In circa 15 Prozent der Fälle wurden zudem irrelevante Informationen nicht als solche erkannt. Dabei soll es sich in mehr als der Hälfte der Fälle um "schwach irrelevante Informationen" gehandelt haben, die die Fähigkeit des Modells, die korrekte Antwort abzuleiten, nicht beeinträchtigen.
Das deute daraufhin, dass die ATF-Methode vorwiegend bei "stark irrelevanten" Informationen, die den Denkprozess wirklich stören, effektiv ist. Nur bei 2,2 Prozent der Fälle sollen relevante Informationen fälschlicherweise als irrelevant eingestuft worden sein.
Trotz der Einschränkungen zeigt die Studie, dass die Fähigkeit von Sprachmodellen, logische Schlussfolgerungen zu ziehen, verbessert werden kann, indem irrelevante Informationen durch Prompt Engineering gezielt herausgefiltert werden.
Die ATF-Methode könnte ein Schritt in Richtung LLMs sein, die besser mit verrauschten realen Daten umgehen können. Sie ist jedoch kein Allheilmittel für die grundlegende Logikschwäche von LLMs.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.