Neue Prompting-Technik soll Mensch-LLM-Verständnis verbessern

Missverständnisse treten häufig in der menschlichen Kommunikation auf, aber auch zwischen Menschen und großen Sprachmodellen (LLMs). Eine neue Prompting-Technik könnte Abhilfe schaffen.
Wenn Missverständnisse auftreten, geben LLMs nutzlose Antworten oder, schlimmer noch, sie beginnen zu halluzinieren. Um das zu verhindern, haben Forscherinnen und Forscher der University of California (UCLA) eine neue Prompting-Technik namens "Rephrase and Respond" (RaR) entwickelt, die die Leistung von LLMs bei der Beantwortung von Fragen verbessern kann.
Neue Prompting-Technik: Rephrase and Respond
Die RaR-Methode ermöglicht es LLMs, Fragen, die von Menschen gestellt werden, umzuformulieren und zu erweitern, bevor sie eine Antwort generieren. Die grundlegende Idee ist, dass man eine bessere Antwort erhält, wenn man eine klarere Frage stellt.

Der Prozess ähnelt der Art und Weise, wie Menschen manchmal eine Frage in ihrem Kopf umformulieren, um sie besser zu verstehen, bevor sie antworten. Indem man den LLM Zeit gibt, über die Frage nachzudenken und sie zu klären, kann die Genauigkeit der Antworten erheblich verbessert werden.
One-step RaR:"{question}" Rephrase and expand the question, and respond.
In den von den Forschenden durchgeführten Experimenten konnte die RaR-Methode die Genauigkeit von zuvor für GPT-4 schwierigen Aufgaben in einigen Fällen auf nahezu 100 Prozent steigern.
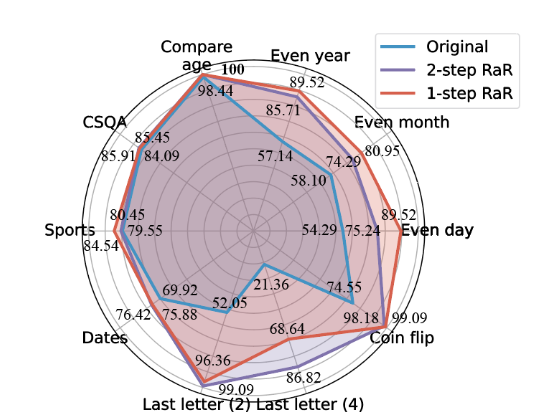
Andere LLMs wie GPT-3.5 und Vicuna zeigten ebenfalls deutliche Leistungsverbesserungen. Das gilt insbesondere für eine zweistufige Variante von RaR, bei der eine ursprüngliche Anfrage von einem leistungsfähigen großen Sprachmodell (LLM) wie GPT-4 umformuliert und dann zur Erstellung einer verfeinerten Anfrage verwendet wird.

Two-step RaR:
"{question}"
Given the above question, rephrase and expand it to help you do better answering. Maintain all information in the original question.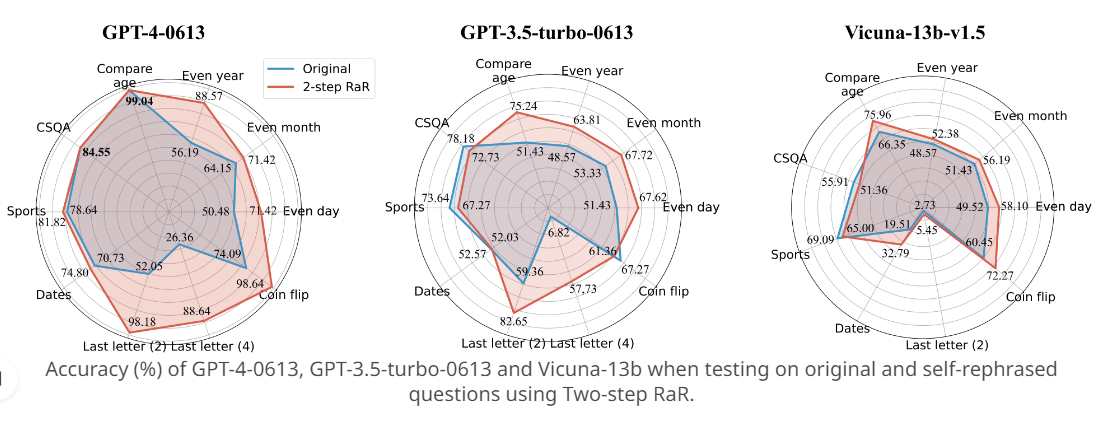
Die Forscher verglichen die RaR-Methode mit der bekannten Chain-of-Thought-Technik (CoT). Beide Methoden zielen darauf ab, die Leistung von LLMs zu verbessern.
RaR erwies sich in den Experimenten der Forscherinnen und Forscher als effektiv bei Aufgaben, bei denen CoT keine Leistungssteigerung brachte. Außerdem können RaR und CoT miteinander kombiniert werden, indem man an den RaR-Prompt das typische "Denke Schritt für Schritt" anhängt.
RaR + CoT
Given the above question, rephrase and expand it to help you do better answering. Lastly, let’s think step by step to answer.
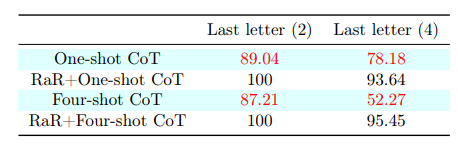
Die für LLMs sehr anspruchsvolle Aufgabe "Last Letter Concatenation" konnte von GPT-4 mit dem RaR-CoT-Prompt auch bei bis zu vier Namen zu fast 100 Prozent zuverlässig gelöst werden. Dabei muss das Sprachmodell die Endbuchstaben einer vorgegebenen Namensliste zu einem neuen Wort zusammensetzen.
Die Fragen und Beispiele aus der Studie sowie die Prompt-Varianten sind im Paper oder bei Github verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.