Neuer Ansatz filtert nützlichste Teile aus riesigen KI-Datensätzen heraus

Es klingt paradox, doch eine neue Studie von MIT-Forschenden unterstreicht eine Annahme, die bereits in den letzten Jahren immer wieder auftaucht: Weniger Daten können tatsächlich zu besseren Sprachmodellen führen.
Das Team hat eine Technik entwickelt, bei der kleine KI-Modelle nur die nützlichsten Teile von Trainingsdatensätzen auswählen. Diese ausgewählten Daten haben sie dann verwendet, um viel größere Modelle zu trainieren. Sie beobachteten, dass die Sprachmodelle sowohl in Benchmarks besser abschneiden als auch weniger Trainingsschritte benötigen.
Der Ansatz, der als "perplexity-based data pruning" bezeichnet wird, lässt das kleinere Modell jedem Trainingsdatensatz einen Perplexitätswert zuweisen. Perplexität ist ein Maß dafür, wie "überrascht" das Modell von einem bestimmten Beispiel ist. Die Idee dahinter ist, dass die überraschendsten Beispiele die meisten Informationen enthalten und somit potenziell am nützlichsten für das Training des Modells sind.
Unterschiedliche Ansätze für verschiedene Arten von Trainigsdaten
In Experimenten verwendeten die Forschenden ein vergleichsweise kleines Modell mit 125 Millionen Parametern, um Trainingsdaten für Modelle zu reduzieren, die mehr als 30 Mal so groß sind.
Die großen Modelle, die mit diesen reduzierten Daten trainiert wurden, übertrafen die Basismodelle, die mit den vollständigen Datensätzen trainiert wurden, deutlich. In einem Test steigerte das Pruning die Genauigkeit eines Modells mit drei Milliarden Parametern um mehr als zwei Prozentpunkte.
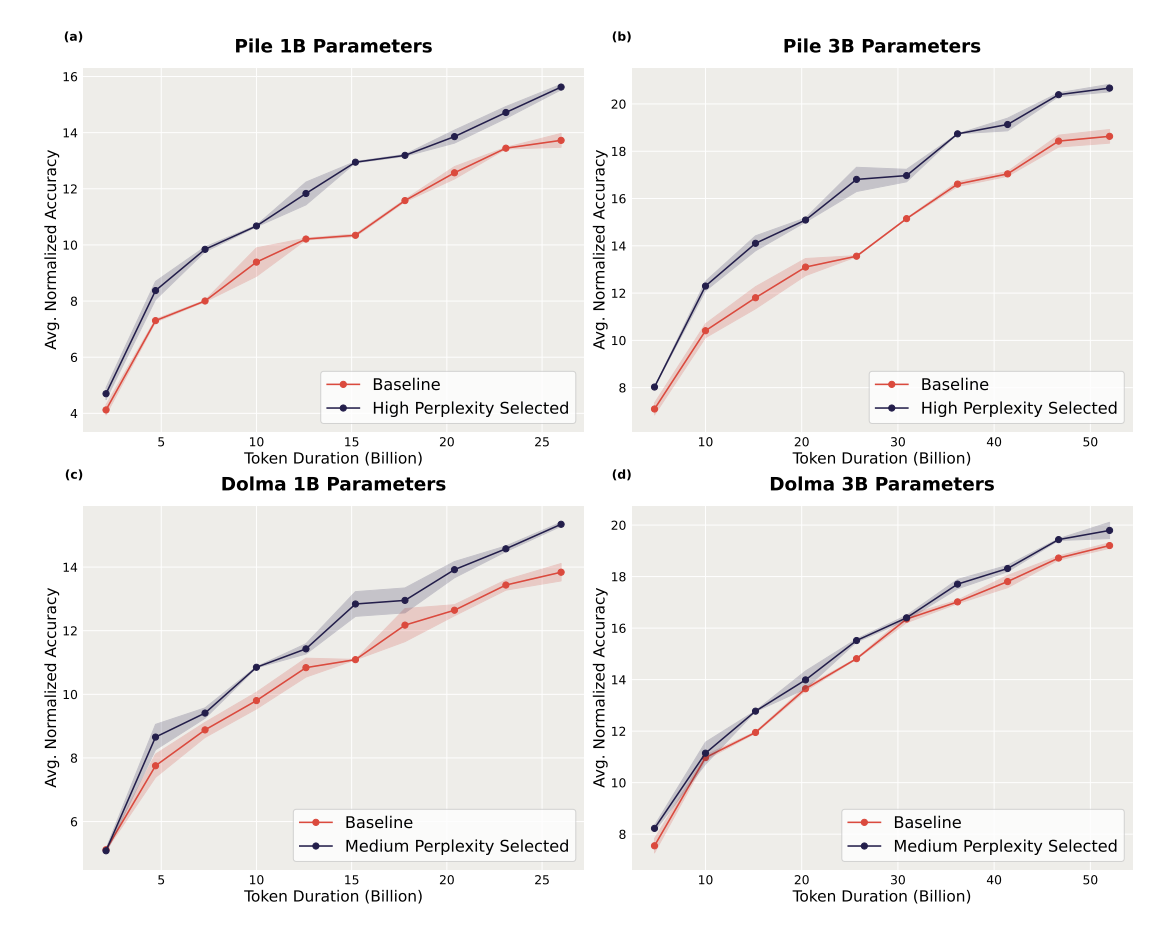
Interessanterweise stellten sie fest, dass verschiedene Datensätze von unterschiedlichen Pruning-Ansätzen profitieren, je nach Zusammensetzung der Daten. Sie empfehlen daher, die Wahl der Methode an den jeweiligen Datensatz anzupassen.
Die MIT-Forscher sehen ihre Arbeit als einen wichtigen Schritt, um die Datenreduktion zu einem Standardbestandteil des KI-Trainings zu machen, und bestätigen frühere Forschungsergebnisse, dass mehr Daten nicht zwangsläufig zu besseren Sprachmodellen führen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.