Neuer KI-Mathe-Benchmark zeigt, wie relativ KI-Benchmarks sind

Ein von Spitzenmathematikern entwickelter Benchmark namens FrontierMath offenbart, dass selbst die fortschrittlichsten KI-Systeme bei komplexen mathematischen Aufgaben nahezu vollständig versagen.
Laut dem KI-Forschungsunternehmen Epoch AI lösen selbst die fortschrittlichsten KI-Modelle wie o1-preview, GPT-4o, Claude 3.5 und Gemini 1.5 Pro weniger als zwei Prozent der Aufgaben im neuen FrontierMath-Benchmark - und das, obwohl sie bei bisherigen Mathematik-Tests Erfolgsquoten von über 90 Prozent erreichen.
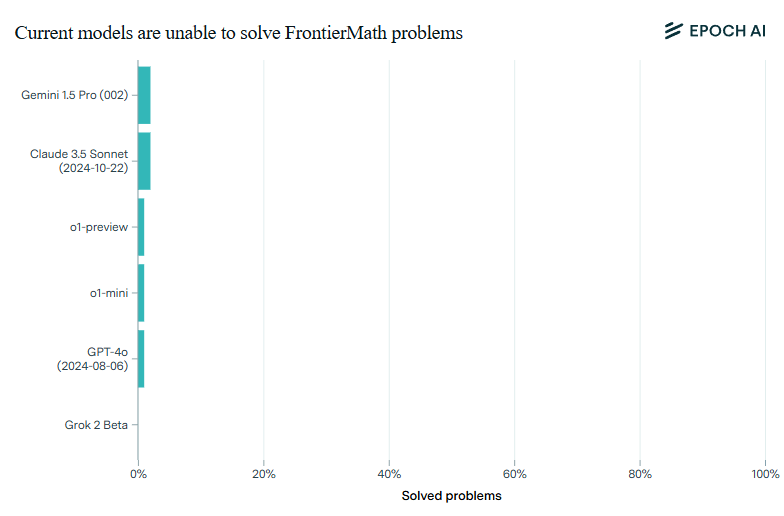
Für FrontierMath haben mehr als 60 führende Mathematikerinnen und Mathematiker hunderte neuer, extrem anspruchsvolle mathematische Probleme entwickelt. Die Probleme decken fast alle Bereiche der modernen Mathematik ab - von rechenintensiven Aufgaben der Zahlentheorie bis zu abstrakten Fragen der algebraischen Geometrie.
Laut EpochAI stecken hinter den Aufgaben oft stunden- oder tagelange Arbeit. Jede Aufgabe durchläuft ein Peer-Review durch Experten, die Korrektheit und Schwierigkeitsgrad prüfen. Bei Stichproben wurde eine Fehlerquote von etwa 5 Prozent festgestellt - vergleichbar mit anderen großen Machine-Learning-Benchmarks wie ImageNet.
Die stark abweichenden Ergebnisse zwischen den etablierten Tests und dem neuen Benchmark zeigen ein grundsätzliches Problem bei der Bewertung von KI-Systemen: KI-Tests erfassen immer nur einen sehr spezifischen Ausschnitt von Fähigkeiten.
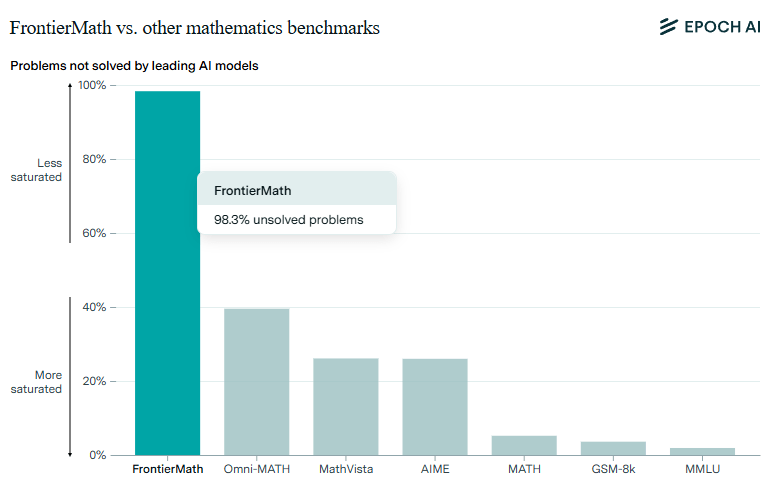
Außerdem haben die Forschenden einen Anreiz, die Modelle für genau diese Fähigkeiten zu optimieren, um gute Benchmark-Ergebnisse zu erzielen. Das müssen sie auch, schließlich fließen Millionen in die Entwicklung.
Das Paradox der KI-Bewertung
Der ehemalige OpenAI-Entwickler Andrej Karpathy sieht in den Ergebnissen eine neue Variante des Moravec-Paradoxons. Das Paradox besagt, dass KI-Systeme zwar beeindruckende analytische Leistungen erbringen und komplexe geschlossene Probleme lösen können, wenn diese klar formuliert sind, etwa auf hohem Niveau Schach spielen.
Sie versagen jedoch bei scheinbar einfachen Aufgaben, die gesunden Menschenverstand oder intuitives Problemlösen erfordern, und haben Schwierigkeiten, Lösungssequenzen zu entwickeln, die Menschen leicht fallen können.
"Trotz hervorragender Testergebnisse würde man sie [die LLMs] nicht anstelle eines Menschen für die einfachsten Arbeiten einstellen", sagt Karpathy.
Neue Arten von Tests seien nötig, um auch diese "einfachen" Fähigkeiten zu bewerten - vom Alltagsverständnis bis zur Fähigkeit, wie ein Praktikant selbstständig zu arbeiten.
Die Forscher von Epoch AI sehen in der Mathematik jedoch einen besonders geeigneten "Sandkasten", um komplexe Denkprozesse zu evaluieren. Sie erfordere Kreativität und lange Ketten präziser Logik, ermögliche aber gleichzeitig eine objektive Überprüfung der Ergebnisse.
Sie wollen den Benchmark kontinuierlich weiterentwickeln und regelmäßige Auswertungen durchführen, um die Fortschritte von KI-Systemen im mathematischen Denken zu dokumentieren. Außerdem sollen in den kommenden Monaten weitere Beispielaufgaben veröffentlicht werden, um der Forschungsgemeinschaft weitere Einblicke zu ermöglichen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.