Neuer Player in Chinas KI-Landschaft: Rednote veröffentlicht erstes Open-Source-KI-Modell

Das chinesische Social-Media-Unternehmen Rednote hat sein erstes großes Sprachmodell vorgestellt. Das Mixture-of-Experts-System soll bei deutlich geringeren Kosten mit Konkurrenzmodellen mithalten können.
Laut dem technischen Bericht des Unternehmens aktiviert das Mixture-of-Experts-System 14 Milliarden Parameter aus insgesamt 142 Milliarden Parametern. Die inzwischen weit verbreitete MoE-Technik trennt das KI-System in verschiedene Experten-Module auf, von denen nur ein Teil für jede Anfrage aktiviert wird. Konkret wählt das System für jeden Token die besten sechs von 128 verfügbaren Experten-Modulen aus, zusätzlich zu zwei Modulen, die immer aktiv sind.
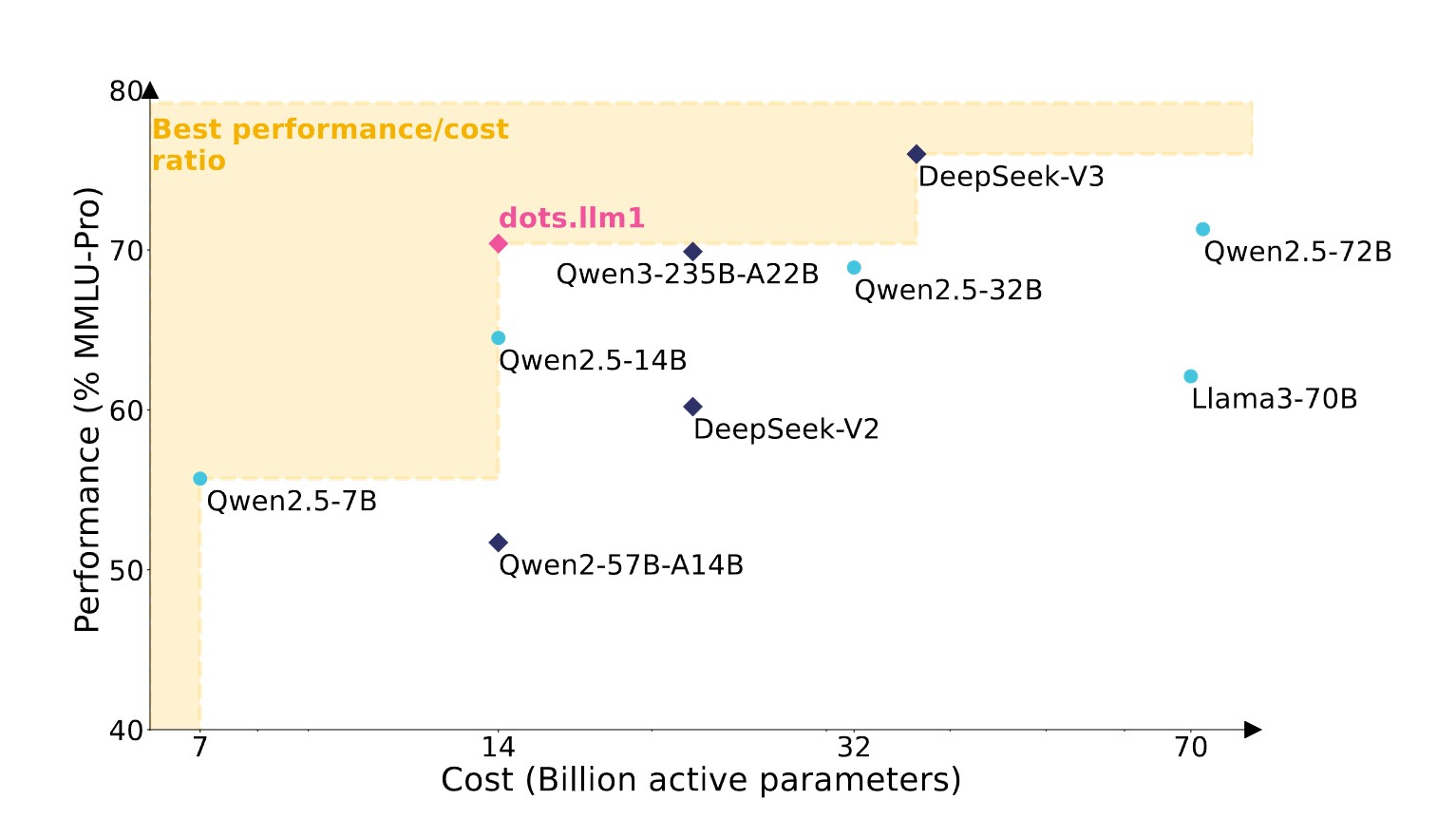
Diese Architektur soll erhebliche Kosteneinsparungen ermöglichen. Bei den Trainingskosten gibt Rednote an, dass dots.llm1 nur 130.000 GPU-Stunden pro einer Billion Tokens benötigt, während Qwen2.5-72B 340.000 GPU-Stunden erforderte. Für den gesamten Pre-Training-Prozess benötigte dots.llm1 1,46 Millionen GPU-Stunden gegenüber 6,12 Millionen bei Qwen2.5-72B, also nur rund ein Viertel der Ressourcen, erreichte aber vergleichbare Performance.
Laut den Benchmark-Ergebnissen zeigt dots.llm1 seine Stärken vor allem beim chinesischen Sprachverständnis. Bei Tests wie C-Eval, die umfassendes chinesisches Sprachwissen messen, und CMMLU, einem chinesischen Pendant zum bekannten MMLU-Benchmark, übertrifft das Modell sowohl Qwen2.5-72B als auch Deepseek-V3.
Bei englischen Wissens- und Verständnisaufgaben schneidet dots.llm1 dagegen weniger gut ab. Tests wie MMLU, die allgemeines Wissen in verschiedenen Fachbereichen prüfen, oder MMLU-Pro, eine schwierigere Variante davon, zeigen, dass das Modell hier leicht hinter Qwen2.5-72B zurückbleibt.
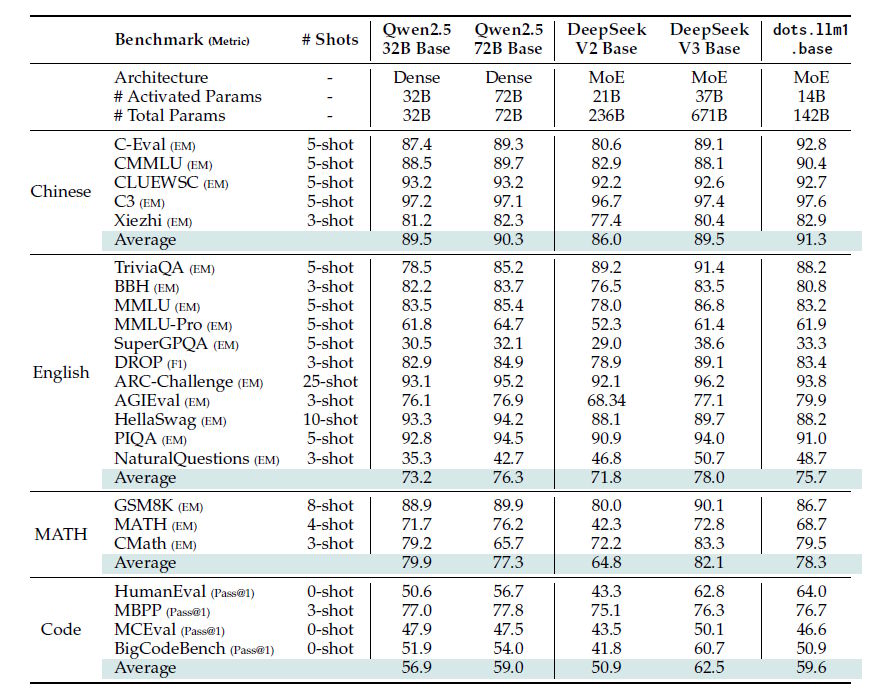
Bei Mathematik-Benchmarks wie GSM8K für grundlegende Rechenaufgaben und MATH für fortgeschrittene mathematische Probleme zeigt dots.llm1 solide Leistungen, bleibt aber meist hinter den größeren Vergleichsmodellen. Überraschend stark ist die Performance bei Code-Generierung: Bei HumanEval, einem Standard-Test für Programmieraufgaben, übertrifft dots.llm1 sogar Qwen2.5-72B deutlich, in anderen ist es wiederum gleichauf oder leicht schwächer.
Keine synthetischen Daten
Das Forschungsteam trainierte das Modell auf 11,2 Billionen hochwertigen Tokens ohne synthetische Daten. Das bedeutet, dass ausschließlich echte Texte aus dem Internet verwendet wurden, keine künstlich generierten Inhalte.
Es ist gut denkbar, dass die Forschenden dabei das Urheberrecht der Texte nicht sonderlich beachtet haben. Kürzlich hat EleutherAI mit dem Common Pile die bisher größte Sammlung lizenzierter Texte für das KI-Training veröffentlicht.
Rednote beschreibt ein dreistufiges Verfahren zur Datenaufbereitung: Dokumentenvorbereitung, regelbasierte Verarbeitung und modellbasierte Verarbeitung. Besonders zwei Innovationen hebt das Unternehmen hervor: ein System zur Entfernung von störenden Webseiten-Elementen wie Werbung und Navigationsleisten sowie eine automatische Kategorisierung der Inhalte.
Für letzteres entwickelte das Unternehmen einen Klassifikator mit 200 Kategorien, um die Zusammensetzung der Trainingsdaten zu optimieren. Dadurch konnte der Anteil wissensbasierter und faktischer Inhalte wie Enzyklopädie-Einträge und populärwissenschaftliche Artikel erhöht werden. Gleichzeitig hat der Vorgang fiktionale Texte und stark strukturierte Web-Inhalte wie Produktbeschreibungen reduziert.
Open-Source-Strategie und internationale Expansion
Rednote veröffentlicht Zwischencheckpoints nach jeder verwendeten Billion Trainingstoken als Open-Source, um der Forschungsgemeinschaft Einblicke in die Trainingsdynamik großer Modelle zu ermöglichen. Die Modelle sind auf Hugging Face unter der Apache-2.0-Lizenz verfügbar, den nötigen Code gibt es auf GitHub.
Die Shanghai-basierte Firma mit 300 Millionen monatlich aktiven Nutzer:innen tritt damit in den umkämpften chinesischen KI-Markt ein, der von Tech-Giganten wie Alibaba, Baidu, Tencent, Bytedance und dem Überraschungs-Start-up Deepseek dominiert wird. Das Modell wurde von Rednotes hauseigenem Humane Intelligence Lab entwickelt, das aus dem früheren KI-Forschungsteam des Unternehmens hervorgegangen ist und jetzt verstärkt Forschende mit geisteswissenschaftlichem Hintergrund einstellt.
Rednote testet bereits einen KI-Forschungsassistenten namens Diandian auf seiner Plattform, der nach Angaben des Unternehmens von einem hauseigenen Modell angetrieben wird.
Die Social-Media-Plattform erlangte im Frühjahr kurz vor dem angekündigten TikTok-Bann in den USA internationale Aufmerksamkeit und galt als digitales Refugium für US-Nutzer:innen. Nachdem die Blockade jedoch wieder zurückgenommen wurde, nahm auch das öffentliche Interesse außerhalb Chinas ab.
Das Unternehmen hat dennoch am 7. Juni sein erstes Büro außerhalb Festland-Chinas in Hongkong und plant eine internationale Expansion. Laut Bloomberg erreichte Rednotes Bewertung 26 Milliarden US-Dollar und übertraf damit den Höchststand aus der Pandemie-Zeit 2021. Ein Börsengang wird noch in diesem Jahr erwartet.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.