Neues Bytedance-KI-Modell animiert Porträts passend zu Audiodateien
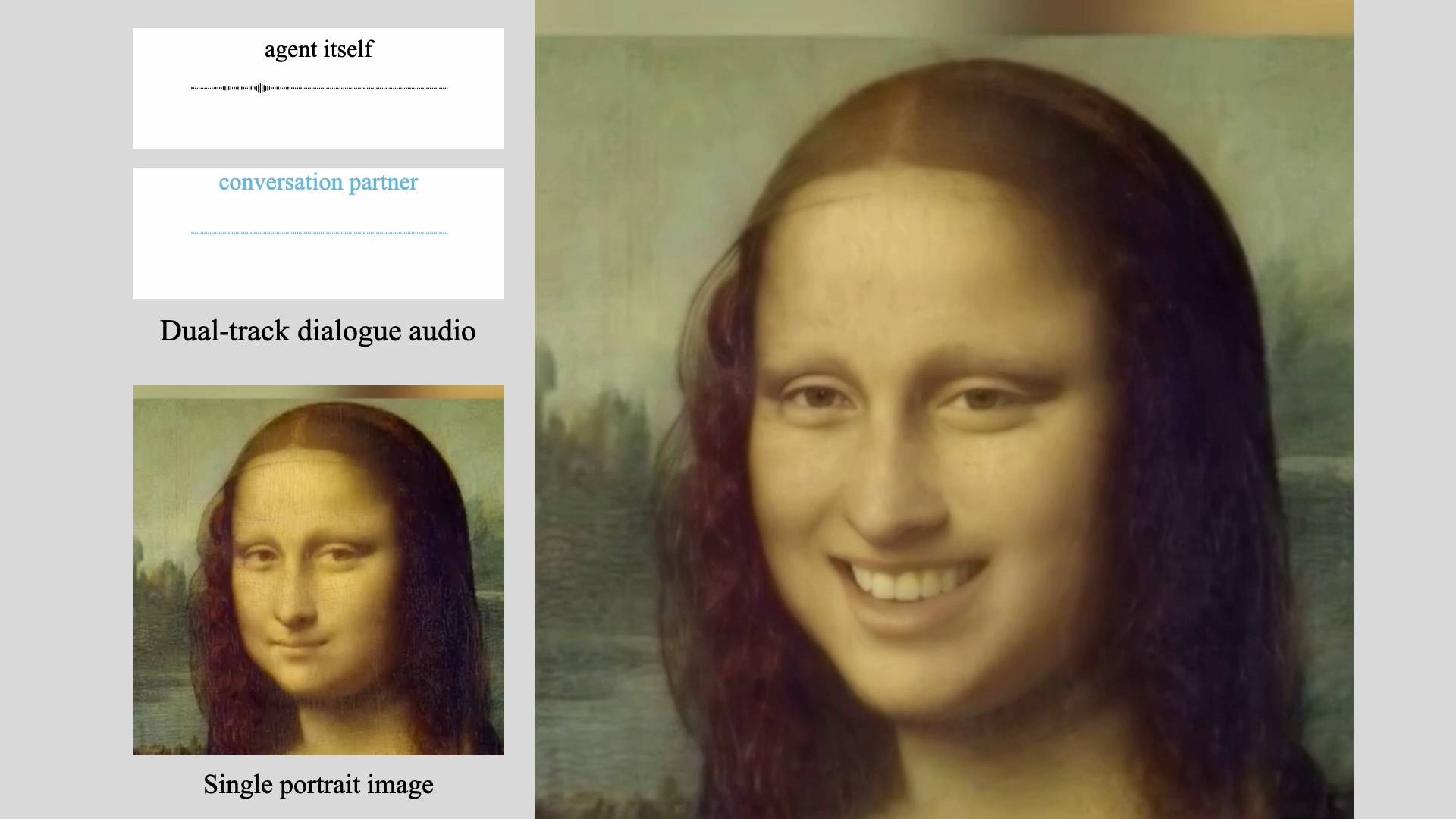
Forscher:innen von TikToks chinesischem Mutterkonzern Bytedance haben ein KI-Framework namens INFP vorgestellt, das einzelne Bilder anhand von Audiodateien zum Leben erweckt.
Das Besondere an INFP, das für "Interactive, Natural, Flash and Person-generic" steht: Es kann lebensechte Dialogvideos für Gespräche zwischen zwei Personen generieren, benötigt dabei allerdings keine manuelle Zuweisung der Rollen "Zuhörer" und "Sprecher" oder einen expliziten Wechsel zwischen diesen Rollen.
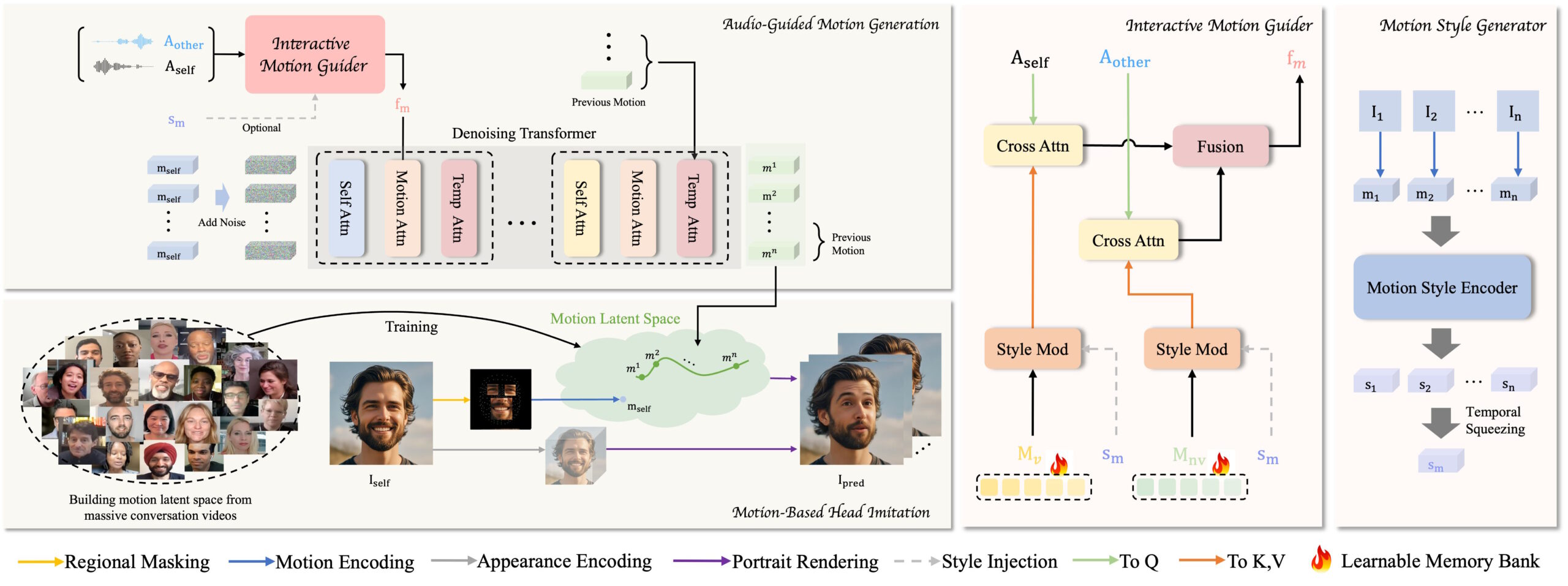
Die Software besteht aus zwei Stufen: In der ersten Stufe, der "Motion-Based Head Imitation", lernt das Modell, kommunikative Verhaltensweisen wie Gesichtsausdrücke und Kopfbewegungen aus Videos in einen kompakten Bewegungs-Latenzraum zu übertragen. Mit diesen Latenzcodes kann dann ein statisches Bild animiert werden, das die Person im Video authentisch nachahmt.
In der zweiten Stufe, der "Audio-Guided Motion Generation", lernt das Modell die Abbildung vom Eingabeaudio auf die Bewegungs-Latenzcodes. Dazu führen die Forschenden einen interaktiven "Motion Guider" ein, der aus dem Audio beider Dialogpartner:innen gemischte Bewegungsmuster für Sprechen und Zuhören konstruiert. Ein Diffusions-Transformer generiert dann durch schrittweises Entrauschen die passenden Bewegungs-Latenzcodes zum Audio.
DyConv: Datensatz für lebensechte Dialoge
Um die Forschung zu unterstützen, haben die Autoren auch DyConv zusammengestellt, einen umfangreichen Datensatz mit über 200 Stunden an Dialogvideos von Gesprächspaaren aus dem Internet. Im Vergleich zu bestehenden Datensätzen wie ViCo oder RealTalk verspricht DyConv eine größere Vielfalt an Emotionen und Ausdrücken bei hoher Videoqualität.
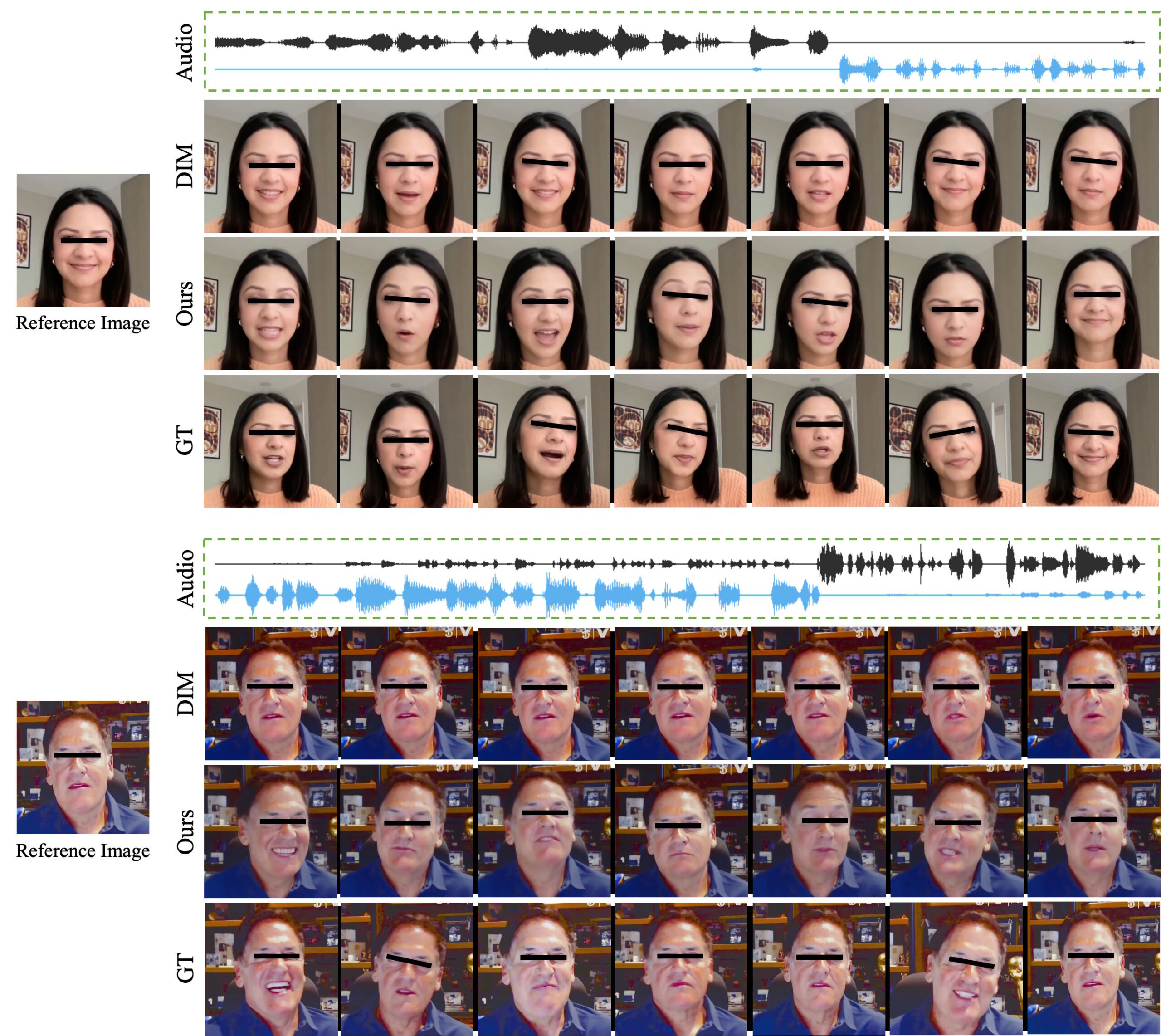
In Experimenten übertrifft INFP laut Bytedance den Stand der Technik bei verschiedenen Metriken wie Audio-Lippensynchronisation, Identitätserhaltung und Bewegungsvielfalt. Auch bei Anwendungen wie der Generierung von nur zuhörenden oder sprechenden Köpfen erzielt das Framework gute Ergebnisse.
Noch großes Verbesserungspotenzial
Derzeit verwendet INFP nur Audiodaten als Eingabe, Bilder oder Texte könnten jedoch zusätzliche Möglichkeiten bieten. Auch eine Erweiterung der Generierung auf den Ober- oder ganzen Körper wäre ein interessanter nächster Schritt, heißt es im Paper.
Die Forschenden weisen jedoch auch auf einen möglichen Missbrauch der Technologie zur Erzeugung von Desinformation hin. Um dem entgegenzuwirken, wollen sie den Zugang zu den Kernmodellen auf Forschungseinrichtungen beschränken.
Ähnlich sah es bei Microsofts Modell zum Stimmenklonen aus dem Sommer aus, das den Wissenschaftler:innen als zu mächtig erschien, als dass sie es öffentlich zugänglich machen wollten.
Bytedance hat bereits im Frühjahr angekündigt, bei generativer KI "all-in" zu gehen. INFP fügt sich in eine Reihe von KI-Experimenten ein. Mit TikTok und CapCut betreibt der chinesische Konzern zudem Plattformen, auf denen vielversprechende KI-Projekte mit großer Reichweite umgesetzt werden können.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.