Neues RAG-System RetroLLM ist effizienter und genauer als bisherige Lösungen

RetroLLM vereint die Suche nach Informationen (RAG) und die Textgenerierung in einem einzigen Prozess. Das System arbeitet effizienter als bisherige Lösungen und soll dabei genauer sein.
Wissenschaftler der Renmin University of China, der Tsinghua University und des Huawei Poisson Lab haben ein KI-System namens RetroLLM entwickelt, das die bisher getrennten Prozesse der Informationssuche und Textgenerierung in einem einzigen Arbeitsschritt zusammenführt.
Bislang mussten KI-Systeme für die sogenannte Retrieval-augmented Generation (kurz RAG, eine Technik, bei der Sprachmodelle auf externe Informationsquellen zugreifen können) in zwei Schritten arbeiten: Erst suchen sie relevante Informationen in einer Datenbank, dann generieren sie daraus einen Text. RetroLLM kann beides gleichzeitig.
Die Ergebnisse der Studie zeigen, dass RetroLLM etwa 2,1-mal weniger Rechenaufwand als herkömmliche Systeme benötigt und dabei präzisere Ergebnisse liefert.
RetroLLM schaut ein bisschen in die Zukunft
RetroLLM arbeitet in drei aufeinander aufbauenden Schritten: Zunächst generiert das System "Hinweise" (Clues). Diese Hinweise sind zentrale Schlüsselwörter oder Phrasen, die aus der ursprünglichen Frage abgeleitet werden. Wenn beispielsweise jemand nach dem ersten Nobelpreisträger für Physik fragt, könnte das System "Nobelpreis" und "Physik" als Hinweise generieren.
Im zweiten Schritt kommen mehrere Techniken zum Einsatz. Der "Constrained Beam Search" ist eine fortgeschrittene Suchmethode, die wie ein Entscheidungsbaum funktioniert: Das System prüft verschiedene mögliche Fortsetzungen eines Textes und bewertet deren Wahrscheinlichkeit. Dabei behält es mehrere vielversprechende "Pfade" bei und verwirft weniger relevante.
Diese Suche wird durch "Forward-Looking Constrained Decoding" optimiert. Diese Technik ermöglicht es dem System abzuschätzen, ob ein Textabschnitt zu relevanten Informationen führen wird, bevor er vollständig verarbeitet wird. Dadurch wird vermieden, dass das System Zeit mit der Verarbeitung von Informationen verschwendet, die letztlich irrelevant sind.
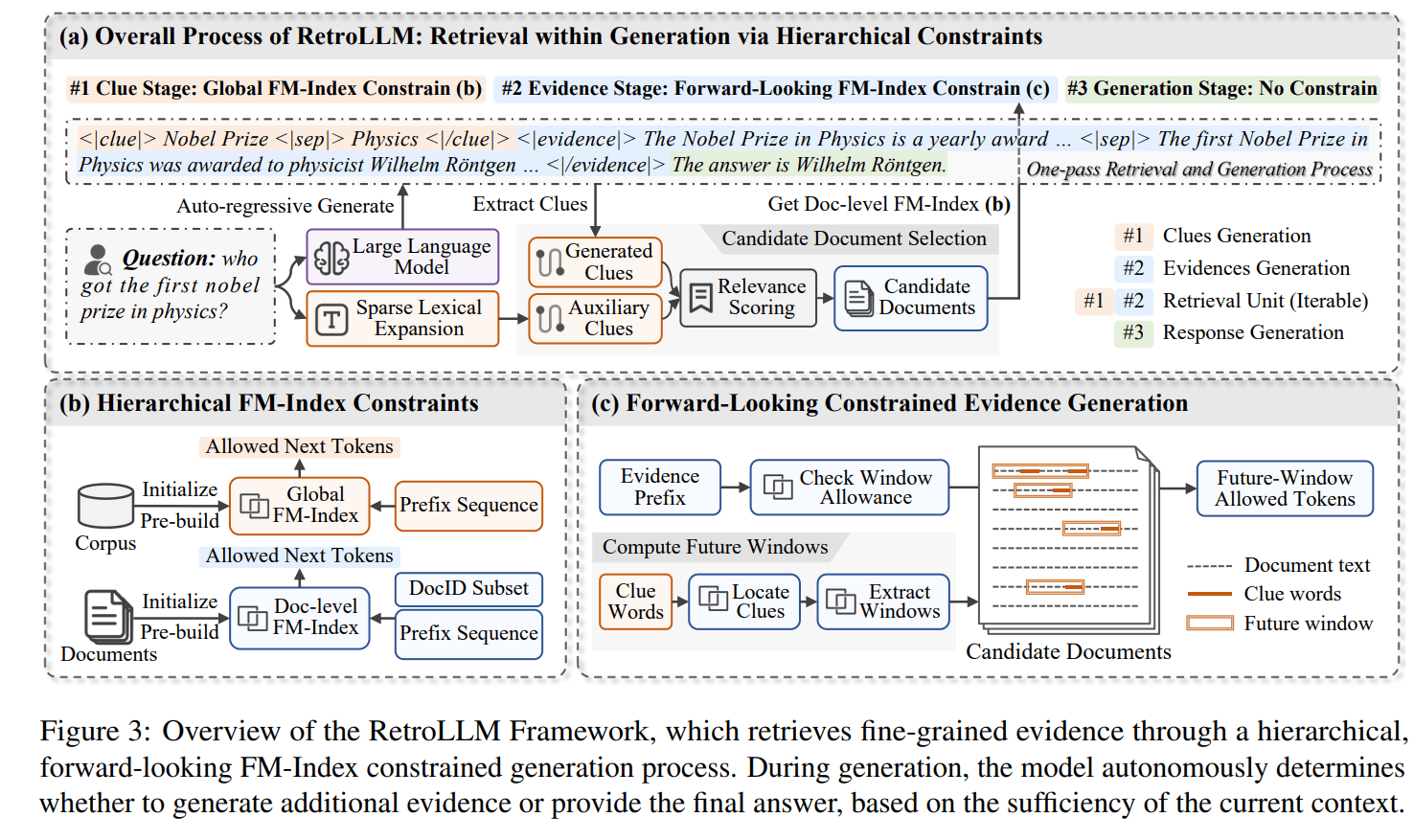
Für die effiziente Navigation durch die Texte nutzt RetroLLM "hierarchische FM-Index Constraints". Diese Datenstruktur funktioniert wie ein mehrstufiges Inhaltsverzeichnis: Auf der obersten Ebene hilft sie, relevante Dokumente zu finden, auf den unteren Ebenen führt sie zu den genauen Textpassagen innerhalb dieser Dokumente.
Im letzten Schritt generiert das System die endgültige Antwort. Anders als bisherige Systeme muss RetroLLM die gefundenen Informationen nicht erst in einem separaten Schritt verarbeiten. Stattdessen kann es während der Antwortgenerierung kontinuierlich auf die Informationsquellen zugreifen und relevante Details einbauen.
Das System entscheidet dabei selbstständig, wie viele Informationen es für eine fundierte Antwort benötigt. Bei einfachen Fragen reichen oft wenige präzise Fakten, bei komplexeren Fragen zieht es automatisch mehr Quellen heran.
RetroLLM schlägt klassische RAG-Methoden
In Tests übertraf RetroLLM die Leistung bestehender Systeme deutlich. Bei Frage-Antwort-Aufgaben erreichte das System eine um durchschnittlich 10 bis 15 Prozent höhere Genauigkeit als vergleichbare Lösungen.
Das System funktioniert dabei laut dem Team nicht nur bei einfachen Fragen gut, sondern auch bei komplexeren Aufgaben, bei denen mehrere Informationsquellen kombiniert werden müssen. Bei solchen "Multi-Hop"-Fragen, die mehrere Gedankenschritte erfordern, zeigte RetroLLM eine besonders deutliche Verbesserung gegenüber herkömmlichen Systemen.
Trotz der Fortschritte hat das System noch Einschränkungen. Die Forscher räumen ein, dass RetroLLM bei der Verarbeitungsgeschwindigkeit einzelner Anfragen etwas langsamer ist als einfache RAG-Systeme, auch wenn es insgesamt weniger Rechenressourcen verbraucht. Eine Mischung aus kleineren und größeren Modellen könne das in Zukunft ändern, vermutet das Team.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.