Nvidias DoRA-Methode ermöglicht effizientes Fine-Tuning von KI

Forscher von Nvidia stellen eine Methode zur ressourceneffizienten Feinabstimmung von KI-Modellen vor. DoRA erreicht eine höhere Genauigkeit als das weit verbreitete LoRA, ohne den Rechenaufwand für die Inferenz zu erhöhen.
Für das Fine-Tuning großer KI-Sprachmodelle für spezifische Aufgaben hat sich der LoRA-Ansatz (Low-Rank Adaptation) etabliert. LoRA passt die Gewichte des vortrainierten Modells mit wenigen Parametern an und reduziert so den Rechenaufwand gegenüber dem klassischen Fine-Tuning des gesamten Netzes. Das so genannte "Full Fine-Tuning" erreicht aber immer noch eine höhere Genauigkeit.
Forscher von Nvidia haben nun die Unterschiede im Lernverhalten zwischen LoRA (Low-Rank Adaptation) und dem klassischen Full Fine-Tuning untersucht, um Methoden zu finden, diese Unterschiede zu minimieren. Dabei analysierten sie die Änderungen der Modellgewichte während des Fine-Tunings, wobei sie besonders die Betrags- und Richtungskomponenten der Gewichte betrachteten. Die Betragskomponenten zeigen, wie stark sich die Gewichte ändern, während die Richtungskomponenten angeben, in welche Richtung diese Änderungen erfolgen, also wie sich das Verhältnis der Gewichte zueinander verändert.
Hier zeigen sich deutliche Unterschiede: Während LoRA Betrags- und Richtungsänderungen proportional vornimmt, kann Full Fine-Tuning subtilere Anpassungen vornehmen. LoRA fehlt die Fähigkeit, große Betragsänderungen mit kleinen Richtungsänderungen zu kombinieren oder umgekehrt.
DoRA nähert sich Lernfähigkeit von Full Fine-Tuning an
Basierend auf diesen Erkenntnissen stellen die Forscher Weight-Decomposed Low-Rank Adaptation (DoRA) vor. DoRA zerlegt die vortrainierten Gewichte zunächst in Betrags- und Richtungskomponenten und trainiert dann beide. Da die Richtungskomponente viele Parameter hat, wird sie zusätzlich mit LoRA zerlegt, um das Training zu beschleunigen.
Durch die getrennte Optimierung von Betrag und Richtung vereinfacht DoRA die Aufgabe für LoRA gegenüber dem ursprünglichen Ansatz. Zusätzlich stabilisiert die Aufteilung der Gewichte die Optimierung der Richtungsanpassung. Durch diese Modifikation erreicht DoRA eine ähnliche Lernfähigkeit wie Full Fine-Tuning.
In Experimenten mit verschiedenen Aufgaben wie Commonsense Reasoning, Visuelle Anweisungsoptimierung und Bild-Text-Verständnis übertrifft DoRA konsistent LoRA ohne zusätzlichen Rechenaufwand bei der Inferenz. Die verbesserte Lernfähigkeit ermöglicht es DoRA, mit weniger Parametern eine höhere Genauigkeit als LoRA in den getesteten Benchmarks zu erreichen.
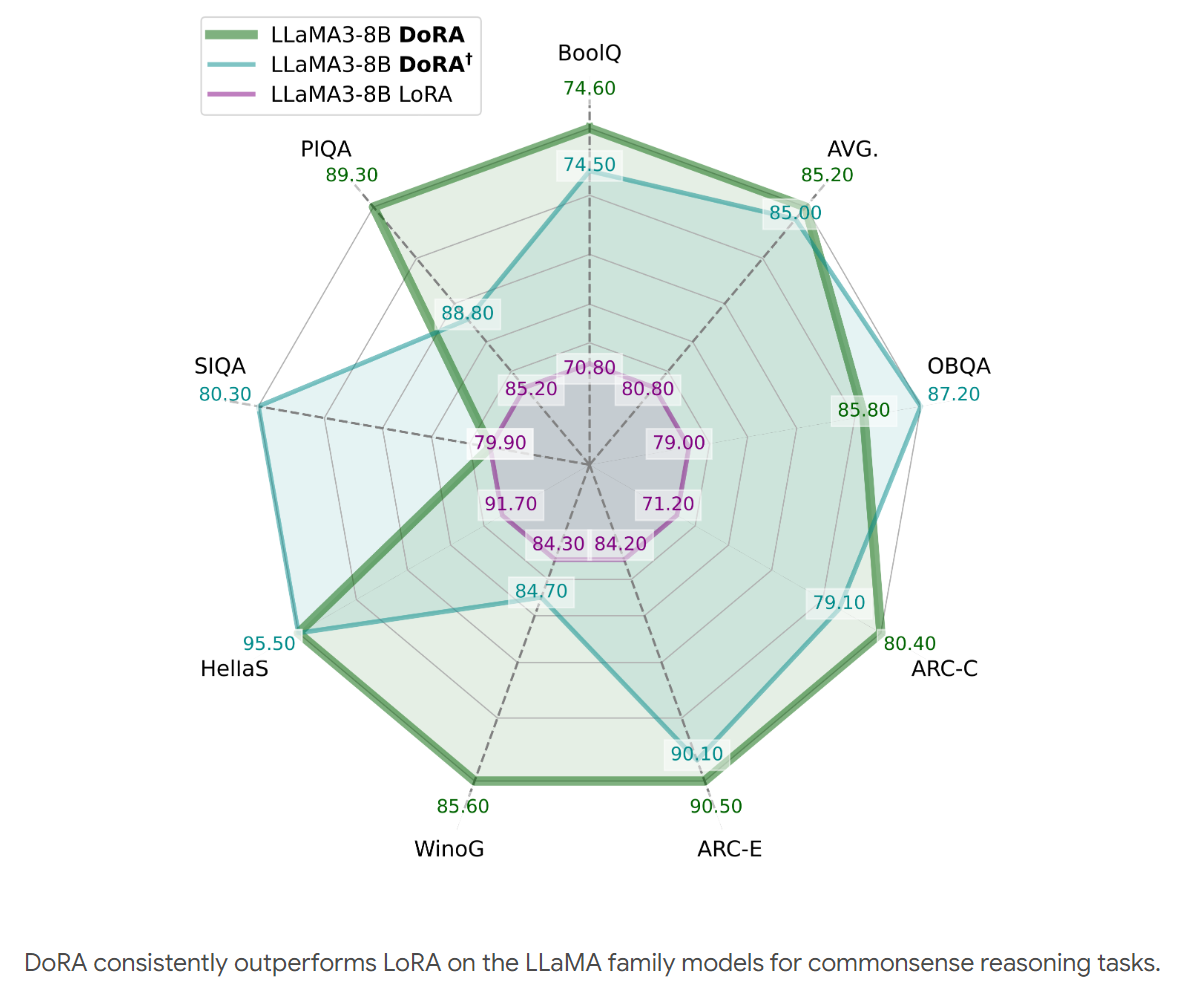
DoRA ist kompatibel mit LoRA und seinen Varianten wie VeRA. Die Methode kann zudem auf verschiedene Modellarchitekturen wie Large Language Models (LLM) und Large Vision Language Models (LVLM) angewendet werden. Die Forscher wollen DoRA in Zukunft auch auf andere Domänen wie Audio übertragen.
Mehr Informationen und den Code gibt es auf der DoRA-Projektseite.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.