o3-Benchmark: OpenAIs KI-Modell erreicht Bestwert bei Verarbeitung langer Texte
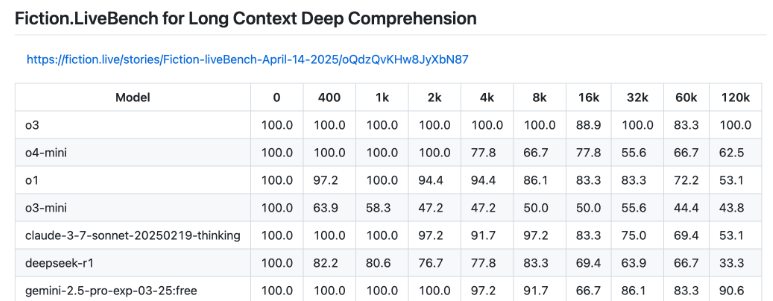
Der wohl interessanteste o3-Benchmark ist die Ausperformance bei der Verarbeitung langer Kontexte. Bei 128K Token (etwa 96.000 Wörter) von maximal 200K Token erreicht o3 im Fiction.live-Benchmark als erstes Modell 100 Prozent – das ist vielversprechend für KI-Anwendungen mit sehr langen Texten. Nur Googles Gemini 2.5 Pro kann mithalten und kommt auf 90,6 Prozent. o3-mini und o4-mini fallen deutlich ab. Fiction.LiveBench prüft, wie gut KI-Modelle komplexe Geschichten und Zusammenhänge bei sehr langen Texten komplett verstehen und korrekt wiedergeben. Ein Negativbeispiel ist Metas Llama 4, das zwar mit einem Kontextfenster von bis zu zehn Millionen Token wirbt, das aber über eine einfache Wortsuche hinaus kaum brauchbar ist.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.