Open-Source Bild-KI Stable Diffusion ist da und die Medienrevolution beginnt

Stable Diffusion ist Open-Source-Konkurrenz für DALL-E 2. Ihr könnt das Modell jetzt auf eurer Grafikkarte in Betrieb nehmen.
Interessierte haben mittlerweile eine ganze Reihe von Alternativen, wenn sie mit Künstlicher Intelligenz Bilder per Texteingabe generieren wollen. Neben den Vorreitern DALL-E 2 von OpenAI und dem schwächeren Craiyon ist vorwiegend Midjourney stark verbreitet.
Vor kurzem verkündete dann das Startup StabilityAI die Veröffentlichung von Stable Diffusion, einem DALL-E-2-ähnlichen System, das zuerst über einen geschlossenen Discord-Server verfügbar war.
Das Besondere an Stable Diffusion: Das leistungsstarke generative Modell ist in einer Kooperation zwischen Forschenden bei Stability AI, RunwayML, der LMU München sowie EleutherAI und LAION entstanden. Es ist Open-Source und läuft auf einer herkömmlichen Grafikkarte.
Stable Diffusion ist offen und auf vielen Plattformen verfügbar
Für das Training des Stable-Diffusion-Modells setzte Stability AI Server 4.000 Nvidia A100-GPU ein und nutzte eine Variante des LAION-5B-Datensatzes. Stable Diffusion kann daher auch Bilder prominenter Personen und andere Motive generieren, die OpenAI bei DALL-E 2 verbietet.
Nach der Testphase über Discord veröffentlichte Stability AI einen Zugang über ein Web-Interface via Dreamstudio. Hier gibt es allerdings einen NSFW-Filter ("not safe for work") und einige Restriktionen bei der Eingabe. Auch HuggingFace bietet ein rudimentäres Web-Interface für Stable Diffusion.
Delighted to announce the public open source release of #StableDiffusion!
Please see our release post and retweet! https://t.co/dEsBX7cRHw
Proud of everyone involved in releasing this tech that is the first of a series of models to activate the creative potential of humanity
— Emad (@EMostaque) August 22, 2022
Am Montagabend veröffentlicht das Team um Stable Diffusion nun das fertig trainierte Modell auf HuggingFace inklusive zugehörigem Code auf Github. Vor knapp einer Woche war bereits eine ältere Version des Modells auf dem berüchtigten Imageboard 4chan geleakt.
Open-Source macht’s möglich: Stable Diffusion läuft auf lokaler Grafikkarte samt grafischer Nutzeroberfläche
Mit dem knapp vier Gigabyte großen Modell und zugehörigen Repos kann jede Person mit einer Nvidia-Grafikkarte mit mehr als 4 Gigabyte VRAM Stable Diffusion lokal in Betrieb nehmen. Höhere Bildauflösungen erfordern allerdings mehr VRAM.
AMD-Grafikkarten werden offiziell nicht unterstützt, können aber mit ein paar Tricks dennoch genutzt werden. Apples M1-Chips sollen in Zukunft ebenfalls unterstützt werden.
Dank der Open-Source-Community existiert die Option, Stable Diffusion mit wenigen Code-Zeilen in einem lokalen Browserfenster mit funktionalem Interface zu bedienen (Anleitung zur lokalen Ausführung von Stable Diffusion). Wer Hilfe bei der Prompt-Suche benötigt, kann den hervorragenden Prompt-Builder nutzen.
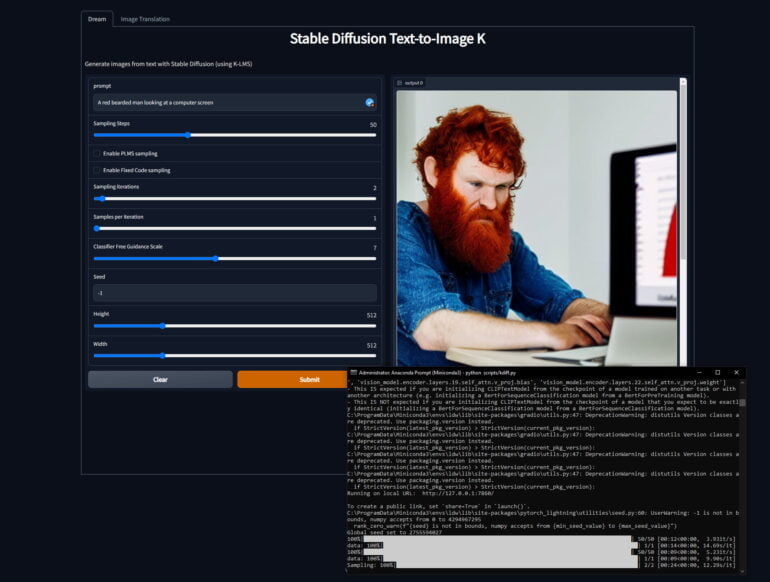
Wer keine entsprechende Grafikkarte besitzt, kann weiter Dreamstudio nutzen oder auf eines der zahlreiche Google Collabs zurückgreifen. Weitere Informationen und Anleitungen gibt es im Reddit-Thread zur Ausführung von Stable Diffusion. Midjourneys Beta-Modell nutzt mittlerweile ebenfalls Stable Diffusion als Teil der eigenen Grafikgenerierung.
Stable Diffusion läutet eine Medienrevolution ein
Viele Menschen werden Stable Diffusion nutzen, um interessante Bilder zu generieren. Manche werden fragwürdiges Material mit entsprechend spezialisierten Stable-Diffusion-Varianten erstellen. Doch Stable Diffusion ist mehr als das: Die in den wenigen Stunden nach der Veröffentlichung hinzugefügten Verbesserungen, wie die zuvor beschriebene Nutzeroberfläche, sind erst der Anfang.
Die Open-Source-Community wird zahlreiche Anwendungen entwickeln, die überraschen und neue Medienformate erreichen. Nach der ersten Stable-Diffusion-Version wird es weitere geben, die die Fähigkeit der aktuellen Version noch übertreffen. Stability AI arbeitet bereits an weiteren Open-Source-Modellen, etwa für generative Audio-Tools von HarmonAI.
Es herrscht eine Aufbruchstimmung in der Open-Source KI-Forschung, denn bisher waren alle leistungsstarken generativen KI-Systeme durch Filter, Zugänge und Hardwareanforderungen eingeschränkt.
Mit der Veröffentlichung von Stable Diffusion beginnt eine neue Ära, in der die Open-Source-Community freie Hand hat, wie der bekannte deutsche KI-Forscher Joscha Bach bei Twitter herausstreicht.
The public release of the Stable Diffusion model is not just the death knell of the stock photo industry. Unless there are significant legal changes, an ecosystem of apps that let everyone generate produce and modify audio, 3d, animations, video will trigger a media revolution.
— Joscha Bach (@Plinz) August 22, 2022
Der Forscher prognostiziert nicht weniger als eine Medienrevolution. Wer die Entwicklungen der letzten zwei Jahre bei generativer KI verfolgt hat, weiß: Bach hat gute Gründe für diese Prognose.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.