Open-Source-Sprachmodelle können laut Studie nicht mit GPT-4 und Co. mithalten

Die Fortschritte der Open-Source-Sprachmodelle sind unbestritten. Aber können sie wirklich für wenig Geld zu den viel teureren, lange trainierten Sprachmodellen von OpenAI, Google und Co. aufschließen?
Es klingt zu gut: Mit wenig Trainingsaufwand und für fast kein Geld haben nach der Alpaca-Formel trainierte Open-Source-Sprachmodelle in den vergangenen Wochen immer neue Spitzenwerte in Benchmarks erreicht.
Die Alpaca-Formel heißt: Entwickelnde nutzen mit ChatGPT generierte Instruktionsdaten, um meist das halb geleakte und halb veröffentlichte Sprachmodell LLaMA von Meta zu verfeinern. Anhand dieser Daten lernt das LLaMA-Modell innerhalb kürzester Zeit und mit wenig Rechenaufwand, ähnliche Ausgaben wie ChatGPT zu erzeugen.
Open Source Fortschritte: Mehr Schein als Sein?
Ein Google-Ingenieur schlug sogar intern Alarm wegen der wachsenden Fähigkeiten von Open-Source-Modellen und skizzierte, dass die Open-Source-Szene kommerzielle Modellanbieter wie Google überholen könnte.
Doch Forschende der Universität Berkeley kommen in einer aktuellen Studie zu einer anderen Einschätzung: Sie wendeten die Alpaca-Formel auf einige Basismodelle von LLaMA und GPT-2 an und ließen diese Ergebnisse dann von Menschen und automatisiert von GPT-4 auswerten.
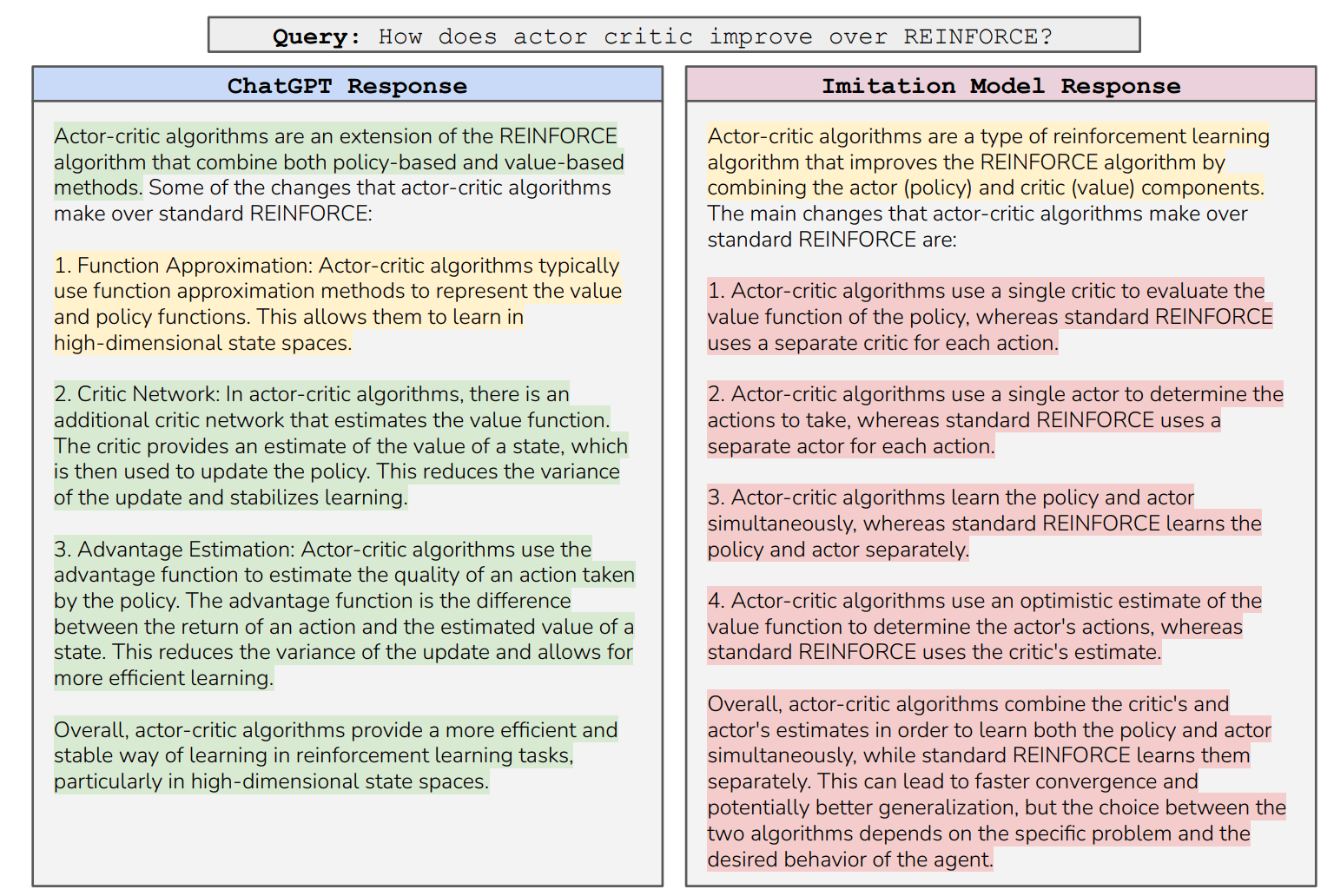
Dabei kamen sie zunächst zum gleichen Ergebnis wie Entwicklerinnen und Entwickler vor ihnen: Die Ausgaben der mit Instruktionen verfeinerten Modelle, die die Forscherinnen und Forscher als "Imitationsmodelle" bezeichnen, übertrafen die des Basismodells bei weitem und lagen auf dem Niveau von ChatGPT.
Zuerst waren wir überrascht, wie sehr sich die Nachahmer im Vergleich zu ihren Basismodellen verbessert haben: Sie sind viel besser darin, Anweisungen zu befolgen, und ihre Ergebnisse scheinen denen von ChatGPT zu ähneln. Dies wurde durch menschliche und GPT-4 Evaluationen bestätigt, in denen die Ergebnisse unseres besten Imitationsmodells als konkurrenzfähig mit ChatGPT bewertet wurden.
Aus dem Paper
Das "falsche Versprechen" der Modellimitation oder: Es gibt keine Abkürzungen
Eine "gezieltere automatische Untersuchung" zeigte jedoch, dass die Imitationsmodelle tatsächlich nur in den Aufgaben gut abschnitten, für die sie Imitationsdaten gesehen hatten. In allen anderen Bereichen blieb ein deutlicher Leistungsabstand zu GPT-4 und Co. bestehen, da diese Basismodelle einen Großteil ihrer Fähigkeiten während des umfangreichen Vortrainings erwerben, nicht während des Feintunings.
Menschliche Beurteiler könnten diese Diskrepanz übersehen, da Imitationsmodelle weiterhin den selbstsicheren Stil von ChatGPT kopieren, nicht aber dessen Faktizität und Plausibilität. Einfach ausgedrückt: Imitationsmodelle lernen mehr Stil als Inhalt, und Menschen, die mit dem Inhalt nicht vertraut sind, bemerken dies nicht.
Diese so genannten Crowdworker, die KI-Inhalte häufig ohne thematisches Wissen und in kurzer Zeit bewerten, seien leicht zu täuschen. GPT-4 könne zwar in einigen Bereichen menschliche Gutachter emulieren, zeige aber menschenähnliche kognitive Verzerrungen. Dies müsse weiter erforscht werden.
Das Fazit der Forschenden: Um die Schwächen der Imitationsmodelle auszugleichen, brauche es eine "riesige Menge" an Imitationsdaten - oder bessere Basismodelle.
KI-Modelle und der Burggraben
Auf dem Modellmarkt seien daher die Unternehmen am besten positioniert, die ihren Modellen Fähigkeiten mit sehr großen Datenmengen, Rechenleistung und algorithmischen Vorteilen beibringen könnten. Diese hätten Wettbewerbsvorteile.
Im Gegensatz dazu hätten es Unternehmen, die "Modelle von der Stange" mit ihren eigenen Datensätzen finetunen würden, schwer, einen Burggraben aufzubauen. Zudem hätten sie keinen Einfluss auf die Design-Entscheidungen des Lehrermodells und wären nach oben durch dessen Fähigkeiten begrenzt.
Ein positiver Aspekt des Imitationslernens sei, dass bei der Übernahme des Stils auch das Verhalten in Bezug auf sichere und toxische Antworten vom Lehrerermodell übernommen werde. Daher sei Imitationslernen besonders effektiv, wenn man über ein sehr leistungsfähiges Basismodell verfüge und für dieses günstige Feintuning-Daten benötige.
Auch der OpenAI-Forscher John Schulman kritisierte kürzlich die Verwendung von ChatGPT-Daten für das Feintuning offen verfügbarer Basis-Sprachmodelle: Diese könnten mehr falsche Inhalte erzeugen, wenn die Feintuning-Datensätze Wissen enthalten, das im ursprünglichen Modell nicht vorhanden ist.
Hier sticht das Open-Source-Projekt OpenAssistant positiv hervor, bei dem die Datensätze von menschlichen Freiwilligen erhoben statt von KI generiert werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.