OpenAI bringt mit Codex-Spark ein Echtzeit-Coding-Modell auf Cerebras-Hardware
Kurz & Knapp
- OpenAI hat mit GPT-5.3-Codex-Spark ein kompaktes Coding-Modell vorgestellt, das auf Echtzeit-Programmierung ausgelegt ist.
- Es läuft erstmals auf einem Inferenz-optimierten Cerebras-Chip und liefert dabei mehr als 1000 Tokens pro Sekunde. Entwickler können das Modell in Echtzeit unterbrechen, umlenken und sofort Ergebnisse sehen.
- Im Vergleich zum größeren GPT-5.3-Codex ist Codex-Spark deutlich schneller, aber weniger präzise: Auf dem Benchmark Terminal-Bench 2.0 erreicht es 58,4 Prozent Genauigkeit gegenüber 77,3 Prozent beim großen Modell.
OpenAI stellt GPT-5.3-Codex-Spark vor, ein kleineres Coding-Modell, das speziell für Echtzeit-Programmierung optimiert ist. Es läuft auf Cerebras-Chips und liefert mehr als 1000 Tokens pro Sekunde.
Codex-Spark ist das erste Resultat der im Januar angekündigten Partnerschaft mit Cerebras. Das Modell läuft auf dem Wafer Scale Engine 3 von Cerebras, einem speziell für schnelle Inferenz konzipierten KI-Beschleuniger.
Die Research Preview steht zunächst ChatGPT-Pro-Nutzern in der Codex-App, der CLI und der VS-Code-Erweiterung zur Verfügung. OpenAI will den Zugang in den kommenden Wochen schrittweise erweitern. Wegen der spezialisierten Hardware gelten eigene Rate Limits, die bei hoher Nachfrage angepasst werden können.
Während OpenAIs größere Frontier-Modelle darauf ausgelegt sind, autonom über Minuten oder Stunden an zunehmend komplexen Programmieraufgaben zu arbeiten, verfolgt Codex-Spark einen anderen Ansatz: Das Modell ist für interaktive Arbeit optimiert, bei der Latenz genauso wichtig ist wie Intelligenz, so OpenAI. Entwickler können das Modell in Echtzeit unterbrechen, umlenken und sofort Ergebnisse sehen.
Codex-Spark arbeitet dabei bewusst zurückhaltend: Es führt standardmäßig minimale, gezielte Änderungen durch und startet keine automatischen Tests, sofern man es nicht ausdrücklich dazu auffordert. Das Modell verfügt über ein 128k-Kontextfenster und verarbeitet ausschließlich Text.
Schneller, aber weniger präzise als das große Modell
Auf den Benchmarks SWE-Bench Pro und Terminal-Bench 2.0, die agentenbasierte Software-Engineering-Fähigkeiten bewerten, zeigt Codex-Spark laut OpenAI starke Ergebnisse, benötigt dafür aber nur einen Bruchteil der Zeit im Vergleich zu GPT-5.3-Codex. Im SWE-Bench-Pro-Vergleich erreicht Codex-Spark eine ähnliche Genauigkeit bei einer geschätzten Aufgabendauer von rund zwei bis drei Minuten, während GPT-5.3-Codex etwa 15 bis 17 Minuten benötigt.
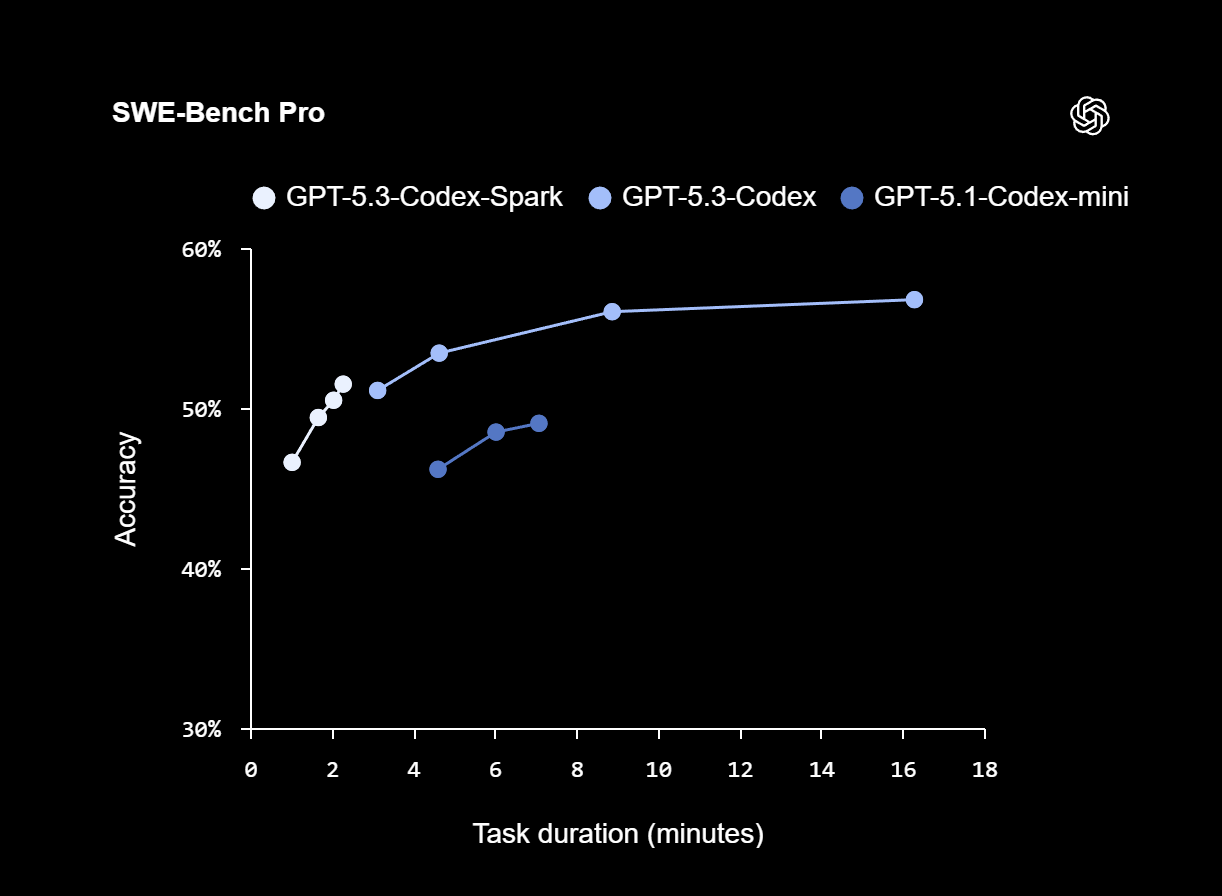
Bei Terminal-Bench 2.0 kommt Codex-Spark auf 58,4 Prozent Genauigkeit. Das größere GPT-5.3-Codex erreicht 77,3 Prozent, das ältere GPT-5.1-Codex-mini liegt bei 46,1 Prozent. Die beiden kleineren Modelle tauschen also Präzision gegen Geschwindigkeit ein.
| Modell | Terminal-Bench 2.0 (Accuracy) |
|---|---|
| GPT-5.3-Codex-Spark | 58,4 % |
| GPT-5.3-Codex | 77,3 % |
| GPT-5.1-Codex-mini | 46,1 % |
Echtzeit- und Reasoning-Modi sollen künftig verschmelzen
Codex-Spark ist laut OpenAI das erste Modell einer geplanten Familie von "ultra-schnellen" Modellen. Weitere Fähigkeiten, darunter größere Modelle, längere Kontextfenster und multimodale Eingaben, sollen folgen.
Langfristig plant OpenAI für Codex zwei komplementäre Arbeitsmodi: einen für längerfristiges Reasoning und autonome Ausführung sowie einen für Echtzeit-Kollaboration. Beide sollen künftig ineinander übergehen. Codex soll Nutzer in einer schnellen interaktiven Schleife halten und gleichzeitig längere Aufgaben an Sub-Agenten im Hintergrund delegieren oder parallel an viele Modelle verteilen können.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren