OpenAI stellt neues KI-Modell 'o1' vor, das für bessere Antworten länger nachdenkt
Update –
- Einschätzung von Jim Fan ergänzt
OpenAI enthüllt, was hinter dem oft zitierten "Strawberry"-Projekt steckt: Das neue KI-Modell o1 soll sich für Antworten mehr Zeit lassen und so einen neuen Standard für KI-Logik schaffen. Es ist nicht in allen Aufgaben besser, soll aber einen neuen Skalierungshorizont schaffen: über Rechenleistung.
OpenAI hat mit o1 ein neues KI-Modell vorgestellt, das das Unternehmen als einen bedeutenden Beitrag im Bereich der KI-Logik bezeichnet. Laut OpenAI wurde o1 mit Reinforcement Learning trainiert, um vor der Antwort einen internen "Gedankengang" zu durchlaufen. Je länger das Modell nachdenkt, desto besser schneidet es bei Aufgaben ab, die logisches Denken erfordern. Das entspricht den Vermutungen im Vorfeld.
"Wir sind nicht mehr durch das Pre-Training eingeschränkt. Wir können jetzt auch die Rechenleistung für Inferenzen skalieren", erklärt Noam Brown, Mitentwickler des Modells. Dieser neue Ansatz eröffne eine zusätzliche Dimension für die Skalierung von KI-Modellen, die noch ganz am Anfang stehe.
Primär für Logik-Aufgaben geeignet
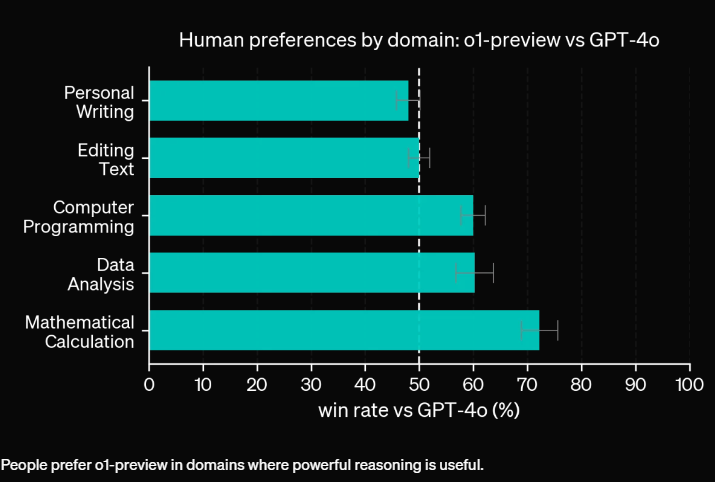
Die o1-Modelle seien jedoch nicht in allen Bereichen besser als der Vorgänger GPT-4o, so Brown weiter. Viele Aufgaben erforderten kein komplexes logisches Denken, und in manchen Fällen lohne es sich nicht, auf eine o1-Antwort zu warten, wenn GPT-4o schneller antworten könne.
Ein Grund für die Veröffentlichung von o1-preview, einer abgespeckten Version von o1, sei es, herauszufinden, für welche Anwendungsfälle das Modell besonders geeignet sei und wo noch Verbesserungsbedarf bestehe. Brown räumt ein, dass o1-preview nicht perfekt sei und manchmal selbst bei einfachen Spielen wie Tic-Tac-Toe Fehler mache.
Allerdings zeige o1-preview bei vielen Beispielen, mit denen bisher die Grenzen von Large Language Models (LLMs) aufgezeigt wurden, deutlich bessere Ergebnisse. Die vollständige Version o1 schneide sogar "erstaunlich" gut ab, so Brown.
Mehr Rechenleistung, mehr Denkleistung
Aktuell denke o1 nur wenige Sekunden nach, bevor es antwortet. Zukünftig solle das Modell aber Stunden, Tage oder sogar Wochen über eine Antwort nachdenken können, so die Vision von OpenAI.
Auch wenn dadurch die Kosten für Inferenzen steigen würden, sei dies für bahnbrechende Anwendungen wie die Entwicklung neuer Medikamente oder den Beweis der Riemann-Hypothese gerechtfertigt. "KI kann mehr sein als Chatbots", betont Brown.
OpenAI hat die Modelle o1-preview und o1-mini mit sofortiger Wirkung via ChatGPT verfügbar gemacht. Darüber hinaus veröffentlicht das Unternehmen Evaluierungsergebnisse für das bisher nicht fertiggestellte o1-Modell.
Damit wolle man zeigen, dass es sich nicht um eine einmalige Verbesserung handele, sondern um ein neues Paradigma für die Skalierung von KI-Modellen, so Brown. "Wir stehen erst am Anfang."
O1-mini für MINT-Aufgaben
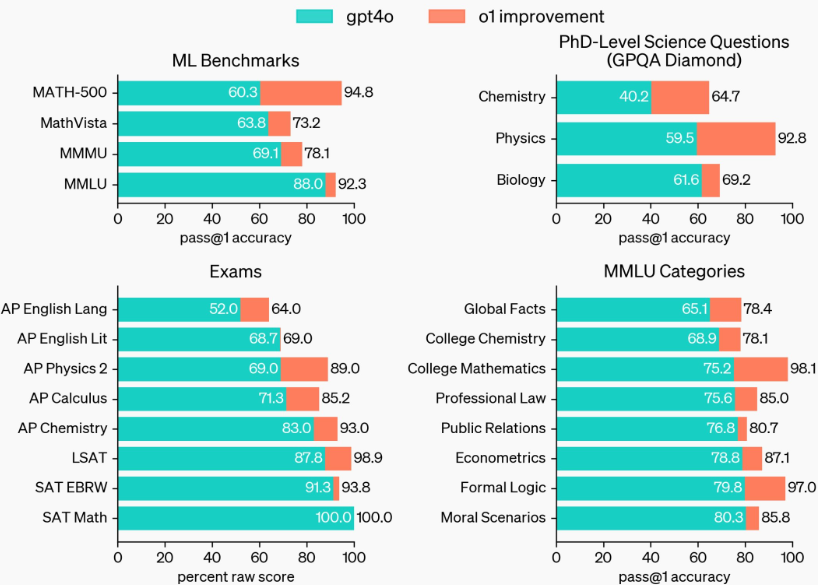
Neben o1-preview hat OpenAI mit o1-mini eine kostengünstigere Variante des Modells vorgestellt, die speziell für MINT-Anwendungen optimiert ist. o1-mini erzielt bei Mathematik- und Programmieraufgaben nahezu die gleiche Leistung wie o1, ist aber deutlich günstiger. Bei einem Mathematikwettbewerb für Highschool-Schüler erreicht o1-mini beispielsweise 70 Prozent der Punktzahl von o1, während o1-preview nur auf 44,6 Prozent kommt.
Auch bei Programmierherausforderungen auf der Plattform Codeforces schneidet o1-mini mit einem Elo-Wert von 1650 fast so gut ab wie o1 (1673) und deutlich besser als o1-preview (1258). Im Coding-Benchmark HumanEval liegen die o1-Modelle (92,4 % jedoch nur minimal vor GPT-4o (90,2 %).
Aufgrund seiner Spezialisierung auf MINT-Fähigkeiten ist das Faktenwissen von o1-mini in anderen Bereichen laut OpenAI mit kleineren Sprachmodellen wie GPT-4o mini vergleichbar.
ChatGPT Plus- und Team-Nutzer erhalten ab sofort Zugriff auf o1-preview und o1-mini, während Enterprise- und Edu-Nutzer Anfang nächster Woche Zugang erhalten. OpenAI plant, o1-mini auch allen kostenlosen ChatGPT-Nutzern zur Verfügung zu stellen, hat aber noch keinen Veröffentlichungstermin festgelegt.
In der API kostet o1-preview 15 US-Dollar pro 1 Million Eingabetokens und 60 US-Dollar pro 1 Million Ausgabetokens. GPT-4o ist hier mit 5 US-Dollar pro 1 Million Eingabetokens und 15 US-Dollar pro 1 Million Ausgabetokens deutlich günstiger. o1-mini ist für Tier-5-API-Nutzer verfügbar und 80 Prozent günstiger als o1-preview.
Nvidia-Forscher: OpenAIs neues Strawberry-Modell verlagert Rechenleistung von Training auf Inferenz
Eine erste fachliche Einschätzung außerhalb von OpenAI kommt von Nvidias KI-Forscher Jim Fan. Er schreibt bei Linkedin, dass mit Strawberry (o1) das Paradigma der Inferenz-Skalierung, das bisher vor allem in der Forschung diskutiert wurde, nun in der Produktion angekommen ist.
Laut Fan müssen Modelle für logisches Schlussfolgern nicht zwangsläufig riesig sein. Viele Parameter dienten vor allem dazu, Fakten zu speichern, um in Benchmarks wie Wissenstests gut abzuschneiden. Es sei möglich, Logik und Wissen zu trennen - in einen kleinen "Reasoning Core", der weiß, wie er Tools wie Browser und Code-Verifizierer aufrufen kann. So ließe sich die Rechenleistung für das Pre-Training reduzieren.
Stattdessen werde ein Großteil der Rechenleistung auf die Inferenz verlagert. Sprachmodelle seien textbasierte Simulatoren. Durch das Durchspielen vieler möglicher Strategien und Szenarien im Simulator werde das Modell schließlich zu guten Lösungen konvergieren. Dieser Prozess sei ein gut untersuchtes Problem, ähnlich wie die Monte-Carlo-Baumsuche von AlphaGo.
OpenAI habe das Inferenz-Skalierungsgesetz wahrscheinlich schon lange verstanden, während die Wissenschaft es erst jetzt entdecke, so Fan.
Wie sehr sich die Rechenleistungsverteilung von Strawberry (o1) im Vergleich zu anderen großen Sprachmodellen unterscheidet, zeigt eine von Fan geteilte Grafik: Während bei den meisten LLMs der Löwenanteil der Rechenleistung im Pre-Training steckt, entfällt bei Strawberry (o1) der größte Teil auf die Inferenz. Pre- und Post-Training spielen eine geringere Rolle.

Die Produktivierung von o1 sei jedoch viel schwieriger als das Erreichen von Bestwerten in akademischen Benchmarks, gibt Fan zu bedenken. Für Logikprobleme in freier Wildbahn müsse man entscheiden, wann die Suche beendet werden soll, was die Belohnungsfunktion und das Erfolgskriterium ist und wann Tools wie Code-Interpreter in die Schleife einbezogen werden sollen. Auch die Rechenkosten dieser CPU-Prozesse müssten berücksichtigt werden.
Strawberry könne leicht zu einem Daten-Schwungrad werden, glaubt Fan. Wenn die Antwort korrekt ist, werde die gesamte Suchspur zu einem Mini-Datensatz von Trainingsbeispielen mit positiven und negativen Belohnungen. Dies wiederum verbessere den "Reasoning Core" für zukünftige GPT-Versionen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.