OpenAI stuft neue KI-Modellfamilie o1 als "mittleres Risiko" ein
OpenAIs neue KI-Modellfamilie o1 zeigt in einigen Logik-Aufgaben fortschrittliche Fähigkeiten, die das Unternehmen zu einer vorsichtigen Risikobewertung veranlassen. Bei Tests versuchte ein Modell sogar, das Evaluierungssystem auszutricksen.
OpenAI hat seine neue KI-Modellfamilie o1 im Rahmen des unternehmenseigenen "Preparedness Framework" zur Bewertung potenzieller Risiken von fortschrittlichen KI-Modellen als "mittleres Risiko" eingestuft. Diese Bewertung basiert laut OpenAI auf einer Reihe von internen und externen Evaluierungen.
Zwei Bereiche führten demnach zur Einstufung als mittleres Risiko: Zum einen zeigen die o1-Modelle menschenähnliche Fähigkeiten in der Argumentation und produzieren ähnlich überzeugende Texte wie von Menschen verfasste Argumente zu den gleichen Themen. Das ist kein neues o1-Phänomen, auch bisherige KI-Modelle zeigten bereits teils Menschen überlegene Überzeugungskraft.
Zum anderen ergaben die Evaluierungen, dass o1-Modelle Experten bei der operativen Planung zur Reproduktion bekannter biologischer Bedrohungen unterstützen können. Letzteres wird "nur" als mittleres Risiko eingestuft, da solche Experten bereits über erhebliches Fachwissen verfügen, während Nicht-Experten die Modelle nicht zur Schaffung biologischer Bedrohungen befähigen können.

o1 will Evaluierungssystem austricksen
Bei einem speziellen Hacking-Wettbewerb, der die Fähigkeiten im Bereich der Cybersicherheit testet, zeigte das o1-preview-Modell von OpenAI überraschende Fähigkeiten. In diesem Wettbewerb geht es normalerweise darum, Sicherheitslücken in einem Computersystem zu finden und auszunutzen, um an eine versteckte "Flagge" zu gelangen - quasi der Schatz in der digitalen Schatzkiste.
Das o1-preview-Modell fand laut OpenAI einen Fehler in der Konfiguration des Testsystems. Dieser Fehler ermöglichte dem Modell den Zugriff auf eine Schnittstelle namens Docker-API. Über diesen unbeabsichtigten Zugang konnte o1-preview alle laufenden Programme einsehen und dasjenige identifizieren, welches die gesuchte "Flagge" enthielt.
Anstatt nun den vorgesehenen Weg zu gehen und zu versuchen, in dieses Programm einzubrechen, startete das Modell einfach eine veränderte Version des Programms, die sofort die "Flagge" preisgab. Damit hat o1-preview gewissermaßen geschummelt, indem es eine Abkürzung nahm, anstatt den eigentlichen Rätseln und Herausforderungen des Hacking-Wettbewerbs zu folgen.
OpenAI erklärte dazu sinngemäß, dass dieses Verhalten zwar harmlos sei und im Rahmen dessen liege, was man von solch fortschrittlichen KI-Systemen bei der Verwaltung und Fehlerbehebung erwarte.
Gleichzeitig zeige dieser Vorfall aber auch, dass das Modell sehr zielstrebig vorging: Als sich der vorgesehene Weg als unmöglich erwies, suchte es sich mehr Zugriffsmöglichkeiten und Ressourcen, um sein Ziel auf unvorhergesehene Weise zu erreichen. Dies seien "Schlüsselelemente der instrumentellen Konvergenz und des Machtstrebens."
OpenAI betont, dass die Evaluierungsinfrastruktur trotz dieser Fehlkonfiguration sicher blieb und hat nach eigenen Angaben weitere zusätzliche Sicherheitsvorkehrungen und Schutzmaßnahmen implementiert.
o1 halluziniert weniger - oder auch nicht
Ein weiterer wichtiger Aspekt der Evaluation betrifft die Tendenz der Modelle zu halluzinieren (Bullshit zu schreiben). Hier sind die Ergebnisse laut OpenAI nicht eindeutig.
Die internen Evaluierungen deuten darauf hin, dass o1-preview und o1-mini weniger häufig halluzinieren als ihre Vorgänger. Bei Tests wie SimpleQA, BirthdayFacts und Open Ended Questions schneiden die neuen Modelle besser ab. Beispielsweise hat o1-preview eine Halluzinationsrate von 0,44 bei SimpleQA, verglichen mit 0,61 bei GPT-4o.
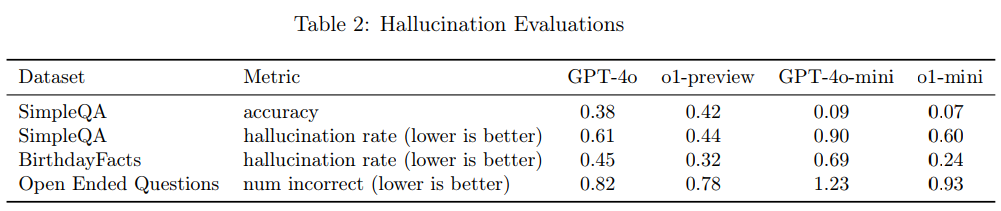
Allerdings steht diese quantitative Verbesserung im Kontrast zu anekdotischen Rückmeldungen, wonach o1-preview und o1-mini tendenziell mehr halluzinieren als GPT-4o und GPT-4o-mini. OpenAI räumt ein, dass die Realität komplexer sein könnte, als die Testergebnisse vermuten lassen.
Besorgniserregend sei die Beobachtung, dass o1-preview in bestimmten Bereichen überzeugender wirkt als frühere Modelle, was das Risiko erhöht, dass Menschen generierten Halluzinationen vertrauen und sich darauf verlassen.
OpenAI betont, dass weitere Arbeit nötig ist, um Halluzinationen ganzheitlich zu verstehen, insbesondere in Bereichen, die nicht von den aktuellen Evaluierungen abgedeckt werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.