OpenAI testet KI als Softwareentwickler: Fast die Hälfte des Code-Budgets geht an die Maschine

Kann Künstliche Intelligenz schon bald menschliche Softwareentwickler:innen ersetzen? Ein neuer Benchmark von OpenAI zeigt, dass KI-Modelle im Praxistest zwar Potenzial zeigen, aber noch weit davon entfernt sind, komplexe Softwareprojekte eigenständig zu bewältigen.
Im neuen Benchmark SWE-Lancer hat OpenAI 1.400 reale Aufträge der Freelancer-Plattform Upwork analysiert, die zusammen ein Auftragsvolumen von einer Million US-Dollar repräsentieren. Die KI-Modelle mussten sich in zwei Kategorien beweisen: als eigenständige Entwickler und im Projektmanagement.
In der ersten Kategorie ging es darum, Fehler zu beheben oder neue Funktionen zu implementieren. Das Spektrum der Aufgaben reichte von kleinen Bugfixes im Wert von 50 US-Dollar bis zu komplexen Features, die mit bis zu 32.000 US-Dollar vergütet wurden.
Ein konkretes Beispiel für einen kleineren Auftrag war die Korrektur eines doppelt ausgelösten API-Calls. Am anderen Ende der Skala stand etwa die Implementierung der In-App-Videowiedergabe. Diese musste für verschiedene Plattformen – Web, iOS, Android und Desktop – umgesetzt werden.
Ein weiterer Auftrag mit mittlerem Schwierigkeitsgrad und einer Dotierung von 1.000 US-Dollar bestand darin, einen Fehler zu beheben, der zu unterschiedlichen Avatarbildern auf der "Share Code"-Seite und der Profilseite führte.
Im Bereich Projektmanagement wurde die Fähigkeit der KI getestet, zwischen verschiedenen Lösungsvorschlägen menschlicher Freelancer:innen die beste Option auszuwählen. Ein Beispiel hierfür war die Aufgabe, den optimalen Vorschlag für die Implementierung einer Bild-Einfügefunktion in der iOS-App zu finden.
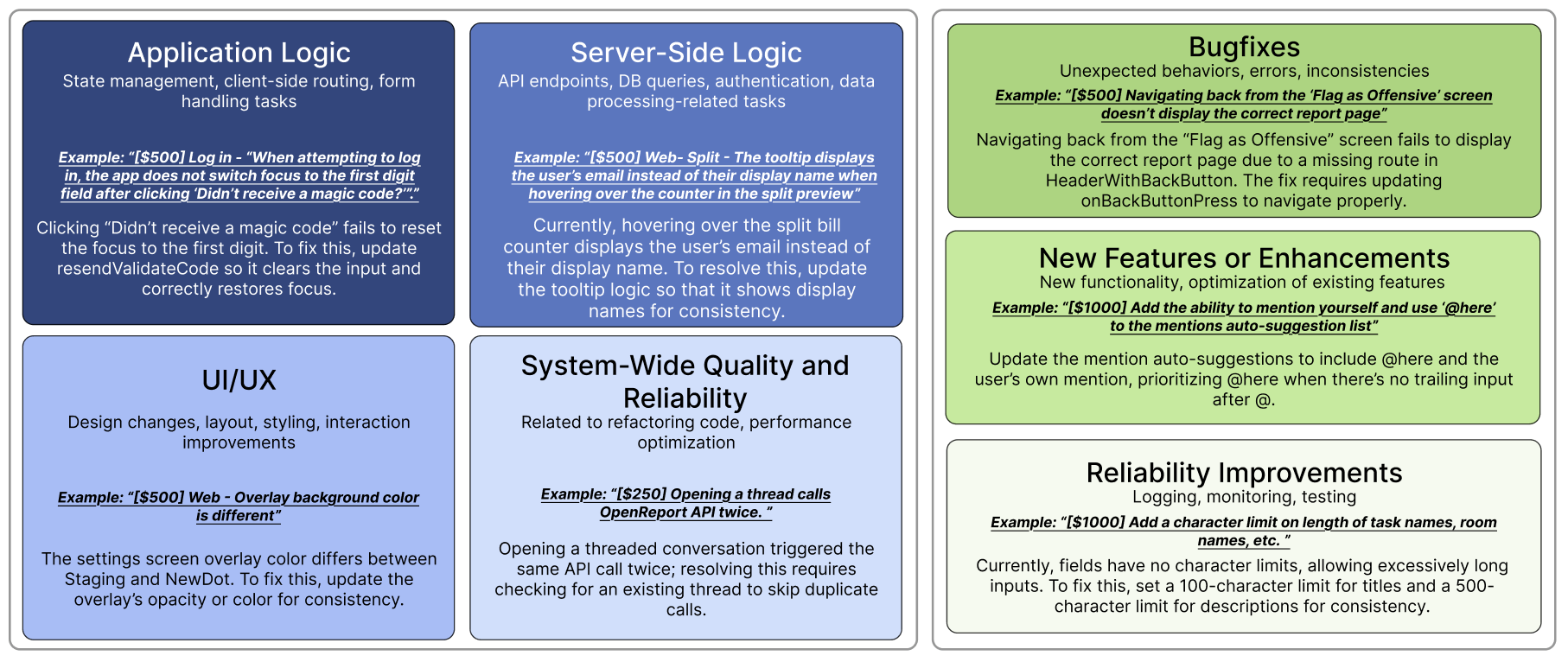
Die KI musste dabei Faktoren wie die Unterstützung verschiedener Clipboard-Formate, die Minimierung von Berechtigungsanfragen und die Übereinstimmung mit dem nativen iOS-Verhalten bewerten.
Um die Leistung der KI-Modelle unter realistischen Bedingungen zu bewerten, setzte OpenAI auf anspruchsvolle End-to-End-Tests. Diese wurden von erfahrenen Softwareentwickler:innen entwickelt und dreifach überprüft.
Im Gegensatz zu Unit-Tests, die nur isolierte Funktionen prüfen, simulieren End-to-End-Tests komplette Benutzerabläufe. So wurde unter anderem der Ablauf zum Testen des Avatar-Bugs mit Einloggen, Hochladen eines Profilbilds und Interaktion mit einem zweiten Account simuliert. Dadurch wird die Komplexität realer Softwareprojekte deutlich besser abgebildet.
KI holt auf, liegt aber bisher nicht vorne
Die Ergebnisse des Benchmarks zeigen, dass KI-Modelle in der Softwareentwicklung zwar Fortschritte machen, aber Menschen bislang noch vorn liegen. Claude 3.5 Sonnet, das leistungsstärkste getestete Modell, löste 26,2 Prozent der Entwicklungs- und 44,9 Prozent der Management-Aufgaben erfolgreich.
Umgerechnet auf den potenziellen Verdienst bei Upwork hätte das bereits deutliche Auswirkungen: Claude 3.5 Sonnet hätte mit den Aufgaben des öffentlichen Datensatzes SWE-Lancer Diamond 208.050 US-Dollar von möglichen 500.800 US-Dollar verdient.
Für den gesamten Datensatz mit einem Auftragsvolumen von einer Million US-Dollar wären dies etwas mehr als 400.000 US-Dollar gewesen. KI könnte sich also zumindest im Upwork-Szenario einen guten Teil des Budgets sichern, wenn die Benchmark-Ergebnisse in die Praxis umgesetzt werden können.
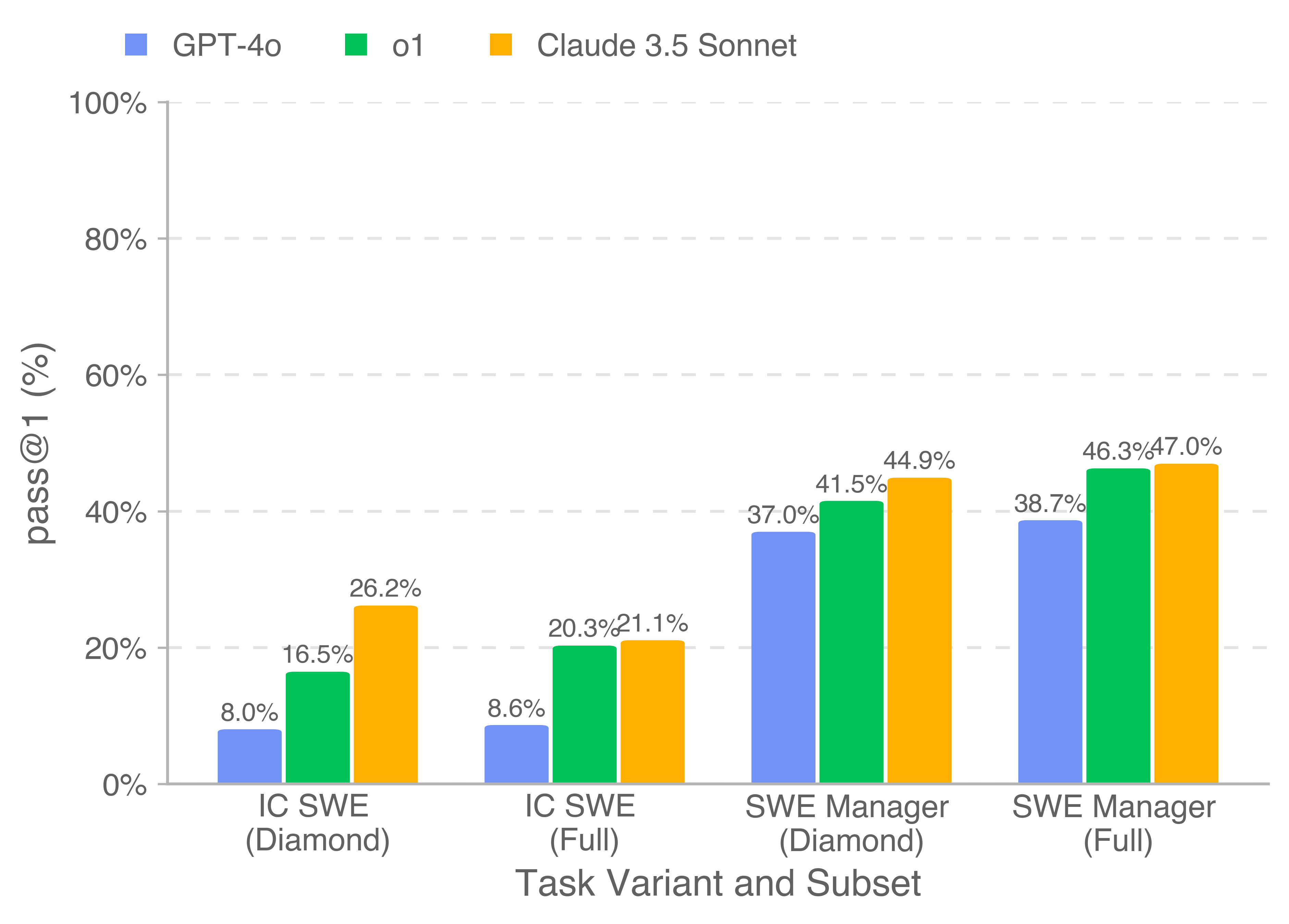
Eine detaillierte Analyse der Ergebnisse offenbarte eine typische Schwachstelle der KI: Die Modelle konnten zwar oft die fehlerhafte Stelle im Code lokalisieren, scheiterten aber häufig daran, die zugrundeliegende Ursache zu verstehen und eine umfassende Lösung zu entwickeln.
Um die Forschung im Bereich der automatisierten Softwareentwicklung zu fördern, hat OpenAI den Datensatz SWE-Lancer Diamond inklusive Docker-Image als Open-Source auf GitHub veröffentlicht.
Das ist auch notwendig, um weitere Modelle – vor allem solche, die auf Coding-Aufgaben spezialisiert sind – in Relation zu den Ergebnissen der drei getesteten Modelle zu stellen. Bemerkenswert ist auch, dass o1 trotz seines höheren Leistungsbedarfs bei der Inferenz keinen Vorteil gegenüber dem etwas älteren traditionellen Sprachmodell Claude 3.5 Sonnet aufweist.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.