Paella ist ein kompaktes und performantes Text-zu-Bild-KI-Modell

Ein internationales Forschungsteam stellt Paella vor, ein Text-zu-Bild-KI-Modell, dessen Architektur auf Performance optimiert ist.
Die derzeit bekanntesten Text-zu-Bild-KI-Systeme Stable Diffusion und DALL-E 2 setzen auf Diffusionsmodelle für die Bildgenerierung und Transformer für das Sprachverständnis. Damit gelingen hochwertige Bildkreationen entlang von Texteingaben.
Doch die Systeme benötigen zahlreiche Inferenzschritte für gute Ergebnisse - und damit auch starke Hardware. Das kann laut des Paella-Forschungsteams Anwendungsszenarien für Endnutzer:innen behindern.
Zurück zum GAN
Das Team stellt mit Paella ein Text-zu-Bild-Modell mit 573 Millionen Parametern vor. Es verwendet eine laut der Forschenden auf Geschwindigkeit optimierte f8 VQGAN-Architektur (Convolutional Neural Network, siehe Erklärvideo am Artikelende) mit einer mittleren Kompressionsrate in Kombination mit CLIP-Embeddings.
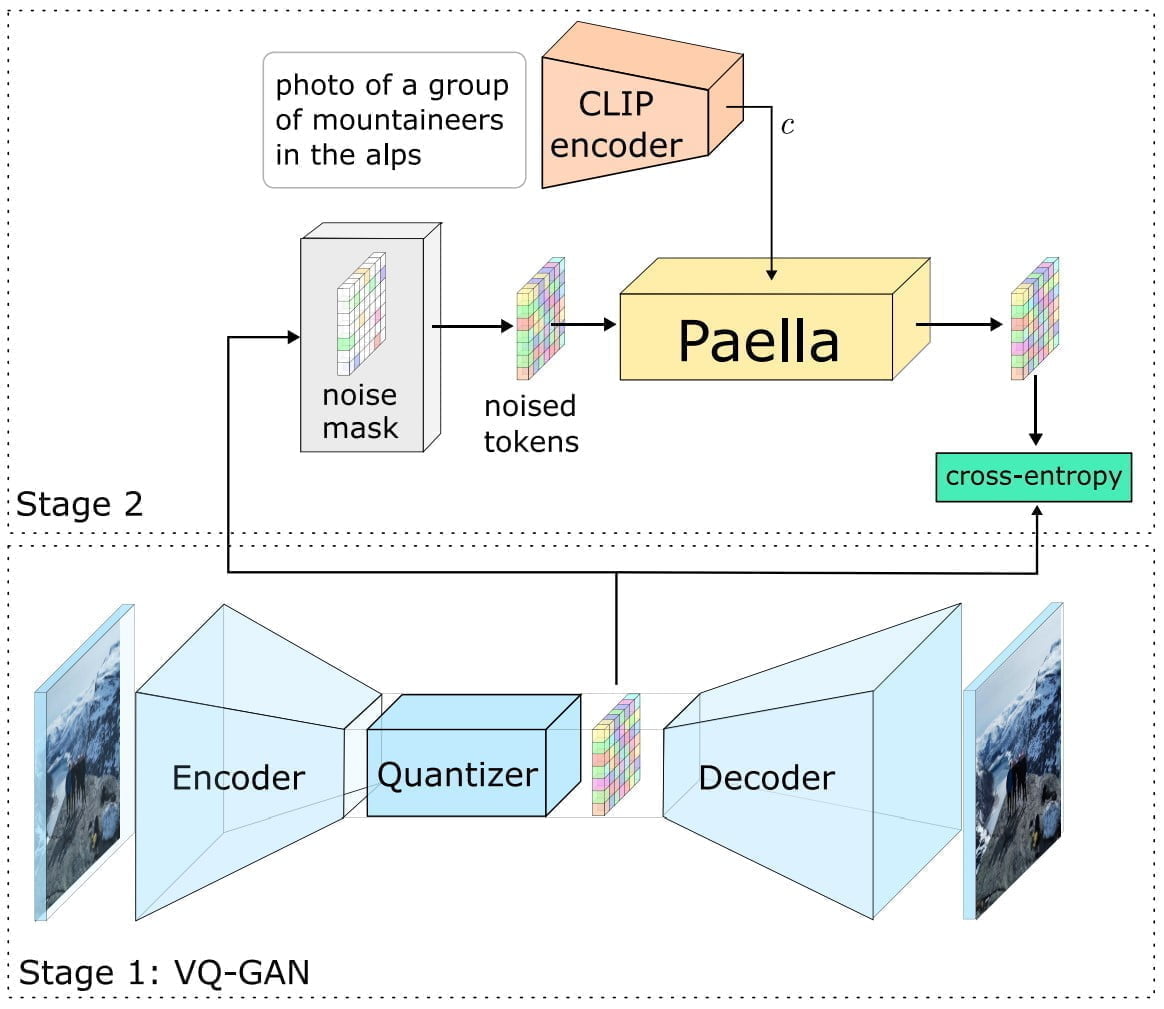
GA-Netze verbreiteten sich im Kontext der Deepfake-Thematik für die Bildgenerierung, bevor sie durch die Diffusion-Technik in den vergangenen Monaten in den Hintergrundgrund gedrängt wurden. Das Forschungsteam sieht in der Paella-Architektur jedoch eine performante Alternative zu Diffusion und Transformer: Paella kann auf einer Nvidia A100 GPU in nur acht Schritten und unter 500 Millisekunden ein 256 x 256 Pixel großes Bild erzeugen. Trainiert wurde Paella mit 600 Millionen Bildern aus dem LAION-5B Ästhetik-Datensatz zwei Wochen lang auf 64 Nvidia A100 GPUs.

Mit unserem Modell können wir Bilder in nur 8 Schritten abtasten und dabei dennoch sehr realitätsnahe Ergebnisse erzielen. Ergebnisse, die das Modell für Anwendungsfälle attraktiv machen, die durch Anforderungen an Latenz, Speicher oder Rechenkomplexität begrenzt sind.
Aus dem Paper
Neben der Bildgenerierung kann Paella eingegebene Bilder durch Techniken wie Inpainting (Inhalte im Bild anhand von Text verändern), Outpainting (das Motiv anhand von Text erweitern) und strukturelle Bearbeitung verändern. Paella unterstützt zudem Prompt-Variationen wie bestimmte Malstile (bspw. Wasserfarbe).

Das Forschungsteam hebt insbesondere die geringe Menge an Code hervor – 400 Zeilen – mit der Paella trainiert und ausgeführt wird. Diese Einfachheit im Vergleich zu Transformer- und Diffusionsmodellen könne generative KI-Techniken für mehr Menschen leichter handhabbar machen, auch außerhalb von Forschungskreisen.
Das Team stellt den eigenen Code und das Modell bei Github zur Verfügung. Eine Demo von Paella ist bei Huggingface verfügbar. Die Bildgenerierung ist schnell und passend zum Text, die Bildqualität kann jedoch noch nicht mit Diffusionsmodellen mithalten.
Die Forschenden weisen allerdings auf das im Vergleich geringe Datentraining hin, das einen fairen Vergleich mit anderen Modellen erschwere, "insbesondere wenn viele dieser Modelle privat gehalten werden", heißt es im Papier. In diesem Sinne sei Paella samt der Veröffentlichung ein Beitrag zur "reproduzierbaren und transparenten Wissenschaft". Hauptautor des Paella-Papers ist Dominic Rampas von der technischen Hochschule Ingolstadt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.