"Platonische Repräsentation": Konvergiert KI zu einem Modell der Realität?

Eine neue Studie argumentiert, dass unterschiedliche KI-Modelle bei wachsender Leistung und Größe zu gemeinsamen Darstellungen konvergieren. Die konvergente Repräsentation könnte ein statistisches Modell der zugrunde liegenden Realität sein.
Verschiedene KI-Modelle bilden bei zunehmender Leistungsfähigkeit und Größe immer ähnlichere Datenrepräsentationen aus. Zu diesem Ergebnis kommt eine Studie von Forschenden des MIT. Sie stellen die Hypothese auf, dass diese Konvergenz auf eine allgemeingültige Darstellung der Realität hinausläuft.
In ihrer Arbeit "The Platonic Representation Hypothesis" zeigt das Team anhand verschiedener experimenteller Beobachtungen, dass künstliche neuronale Netze, die mit unterschiedlichen Zielen auf verschiedenen Daten und Modalitäten wie Bildern und Text trainiert werden, zu einem gemeinsamen statistischen Modell der Realität in ihren Repräsentationsräumen konvergieren.
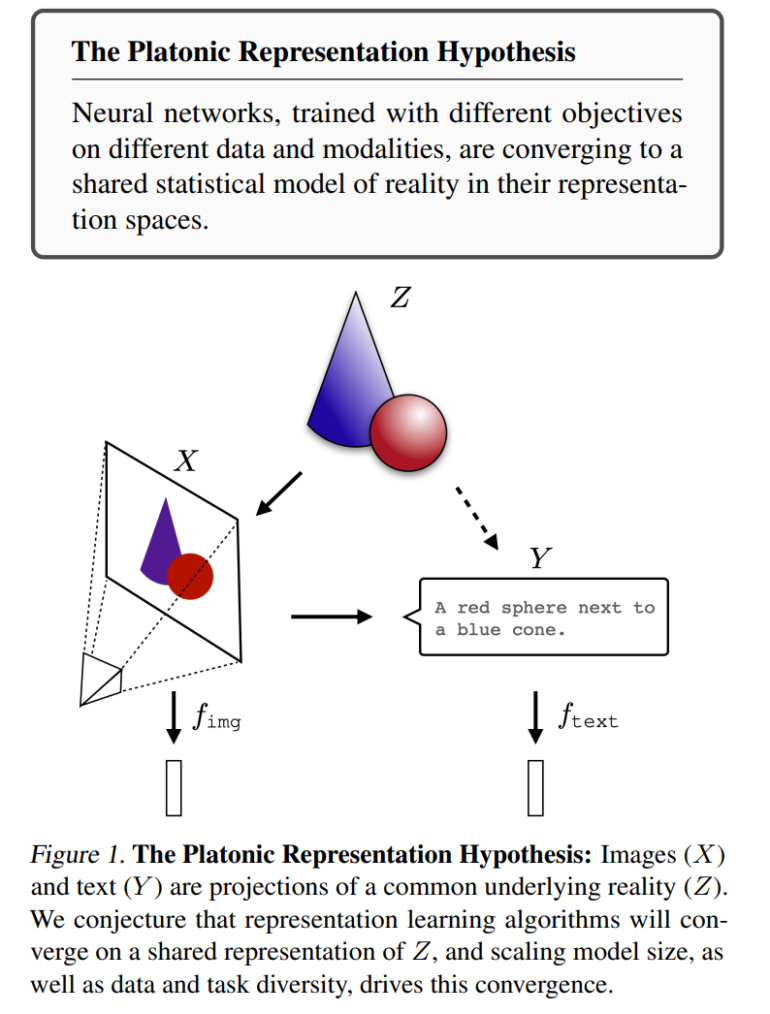
Demnach versuchen unterschiedliche Modelle alle, eine Repräsentation der Realität zu finden - also eine Repräsentation der gemeinsamen Verteilung von Ereignissen in der Welt, die die beobachteten Daten erzeugen. Je größer die Modelle werden und je mehr Daten und Aufgaben sie abdecken, desto mehr nähern sich ihre internen Repräsentationen an.
Die Forscher nennen diese hypothetische konvergierte Repräsentation "platonische Repräsentation" in Anlehnung an Platons Höhlengleichnis und seine Idee einer idealen Realität, die unseren Sinneseindrücken zugrunde liegt.
Evidenz für die Konvergenz kommt aus Beobachtungen, dass Modelle mit unterschiedlichen Architekturen und Trainingsdaten zu ähnlichen Repräsentationen gelangen. Beispielsweise können Schichten zwischen Modellen mit ähnlichen Leistungen ausgetauscht werden, ohne die Leistung stark zu beeinträchtigen. Außerdem scheint die Konvergenz mit zunehmender Modellgröße und Leistung zuzunehmen.
Interessanterweise scheint die Konvergenz sogar modalitätsübergreifend stattzufinden: Repräsentationen visueller Modelle und Sprachmodelle gleichen sich zunehmend an. Auch zu Repräsentationen im menschlichen Gehirn gibt es wachsende Ähnlichkeiten.
Skalierung könnte Halluzinationen verringern
Die Forscher vermuten, dass der Konvergenzprozess durch mehrere Faktoren begünstigt wird: Zum einen führt die Skalierung auf mehr Daten und Aufgaben zu einem immer kleineren Lösungsraum. Zum anderen sind größere Modelle eher in der Lage, ein gemeinsames Optimum zu finden. Schließlich bevorzugen tiefe Netze von Natur aus einfache Lösungen, was die Konvergenz weiter vorantreibt.
Aus ihrer Hypothese leiten sie mehrere Implikationen ab:
- Trainingsdaten können modalitätsübergreifend geteilt werden. Um das beste Sprachmodell zu trainieren, sollte man auch Bilddaten verwenden - und umgekehrt.
- Die Übersetzung und Anpassung zwischen Modalitäten wird erleichtert. Sprachmodelle würden auch ohne modalitätsübergreifende Daten ein gewisses Maß an Verankerung in der visuellen Domäne erreichen.
- Skalierung könnte Halluzinationen und Voreingenommenheit verringern. Mit zunehmender Skalierung sollten die Modelle die Voreingenommenheit der Daten weniger verstärken.
Allerdings diskutieren die Forscher auch Grenzen ihrer Hypothese. Zum Beispiel können verschiedene Modalitäten unterschiedliche Informationen enthalten, sodass eine vollständige Konvergenz nicht möglich ist. Auch gebe es in manchen Domänen wie der Robotik noch keine standardisierten Repräsentationen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.