
Eine neue Studie zeigt, dass große Sprachmodelle von längeren Chain-of-Thoughts profitieren – selbst wenn sie falsche Informationen enthalten.
Chain of Thought-Prompting verbessert nachweislich die Schlussfolgerungsfähigkeiten großer Sprachmodelle. Eine Studie von Forschern der Northwestern University, der University of Liverpool, des New Jersey Institute of Technology und der Rutgers University zeigt nun, dass die Länge der Argumentationsschritte in CoT-Prompts in direktem Zusammenhang mit der Leistung von Sprachmodellen bei komplexen Problemlösungsaufgaben steht.
Die Studie zeigt, dass die bloße Verlängerung der Argumentationsschritte innerhalb der Prompts ohne Hinzufügen neuer Informationen die Argumentationsfähigkeit von Sprachmodellen signifikant verbessert. Umgekehrt führt eine Verkürzung der Argumentationsschritte, selbst wenn die Kerninformation erhalten bleibt, zu einer signifikanten Verschlechterung der Argumentationsleistung.
Sie testeten ein breites Spektrum an Aufgabentypen, darunter Arithmetik, Commonsense-Fragen, symbolische Probleme, sowie spezifischere Sets wie MultiArith, GSM8K, AQuA, SingleEq, SVAMP, StrategyQA, und Letter- sowie Coin-Aufgaben.
Eines der überraschendsten Ergebnisse der Studie: Auch fehlerhafte Argumentationen können zu positiven Ergebnissen führen, wenn sie lang genug sind. Dies deute darauf hin, dass die Länge der Argumentationskette einen größeren Einfluss hat als die sachliche Richtigkeit der einzelnen Schritte, schlussfolgern die Forscher.
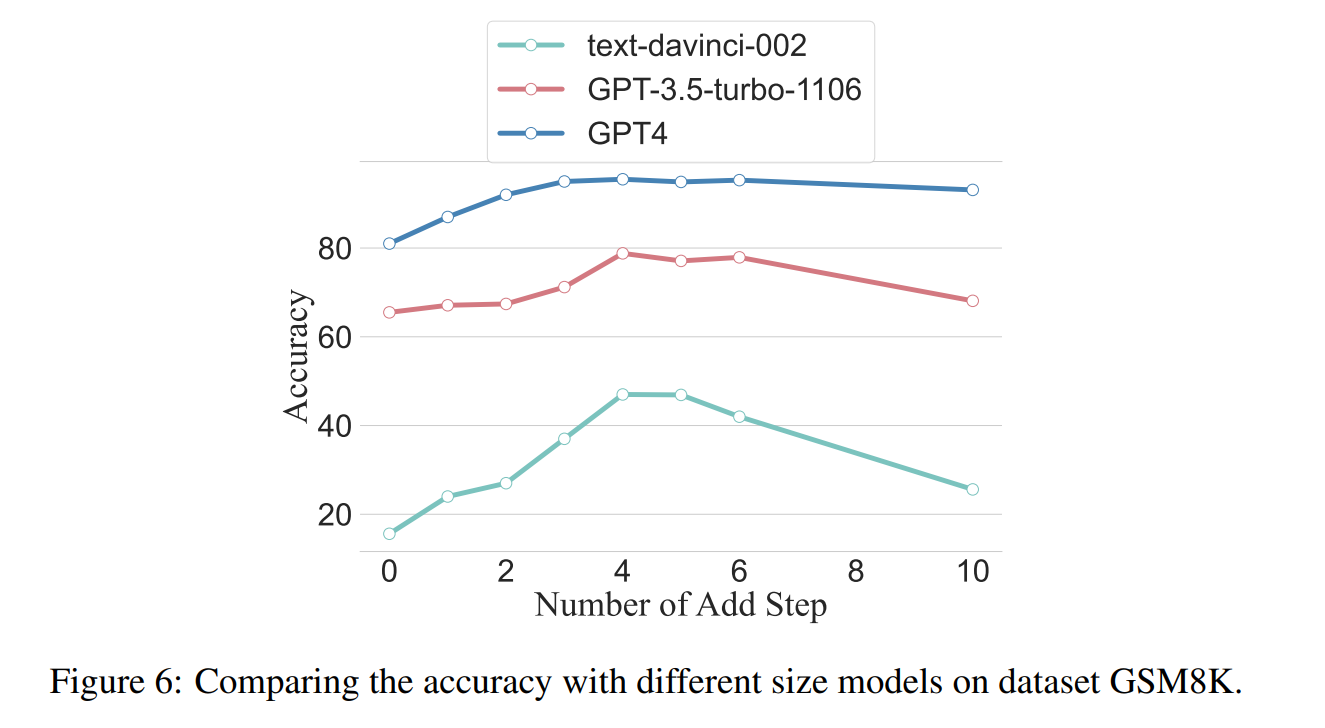
Auch GPT-4 profitiert von längeren Chain-of-Thoughts
Längere Argumentationsschritte helfen aber nicht immer - sie sind aufgabenabhängig. Die Studie ergab, dass einfachere Aufgaben weniger von zusätzlichen Schritten profitieren, während komplexere Aufgaben durch längere Argumentationsketten signifikant verbessert werden. Größere Modelle wie GPT-4 zeigten zudem eine höhere Toleranz gegenüber der Länge oder Kürze der Schritte – kleinere Modelle profitierten in den Tests am meisten von der Strategie. Allerdings können zu lange Ketten die Leistung wieder verschlechtern – gerade bei kleineren Modellen.
Das Team plant nun, seine Untersuchungen fortzusetzen und die neuronalen Aktivierungsmuster zwischen langen und kurzen Argumentationsschritten zu analysieren, um besser zu verstehen, wie die Länge der Argumentationsschritte die Sprachmodelle beeinflusst.


