RATIONALYST: Wie unausgesprochene Begründungen KI-Denken verbessern

Forscher der Johns Hopkins University haben ein KI-Modell namens RATIONALYST entwickelt, das die Reasoning-Fähigkeiten von Large Language Models durch implizite Begründungen verbessert.
Wissenschaftler der Johns Hopkins University haben ein neues KI-Modell mit dem Namen RATIONALYST vorgestellt, das die Schlussfolgerungsfähigkeiten von großen Sprachmodellen (Large Language Models, LLMs) verbessern soll. Laut der Forscher nutzt RATIONALYST implizite Begründungen, die aus unmarkierten Textdaten extrahiert werden, um den Reasoning-Prozess von LLMs zu überwachen und zu verbessern.
Sie verwendeten dazu ein vortrainiertes Sprachmodell, um implizite Begründungen aus unmarkierten Textdaten zu generieren. Dazu geben sie dem Modell Prompts mit Beispielen, die zeigen, wie implizite Begründungen aussehen können. Das Modell generiert dann ähnliche Begründungen für neue Texte.

Um die Qualität der generierten Begründungen zu verbessern, filtern die Forscher diese anschließend. Dazu prüfen sie, ob eine generierte Begründung die Vorhersage des nachfolgenden Textes erleichtert. Nur Begründungen, die dieses Kriterium erfüllen, werden behalten.
Für den Text "Harry used magic outside of the school of Hogwarts to inflate Aunt Marge... He is punished to attend a disciplinary hearing at the Ministry of Magic..." generiert das Modell die implizite Begründung "When someone breaks the rule, he will be punished!". Diese Begründung wird als nützlich bewertet, da sie die kausale Verbindung zwischen Harrys Regelverstoß und seiner Bestrafung herstellt und so die Vorhersage des nachfolgenden Textes erleichtert.
Die Forscher extrahieren auf diese Weise insgesamt etwa 79.000 implizite Begründungen aus verschiedenen Datenquellen. Diese dienen dann als Trainingsdaten für RATIONALYST.
RATIONALYST wird dann während des Inferenzprozesses eingesetzt, um schrittweise Problemlösungen anderer Modelle zu überwachen. Das Modell generiert dabei implizite Begründungen für jeden Reasoning-Schritt und nutzt diese, um die wahrscheinlichsten nächsten Schritte auszuwählen.
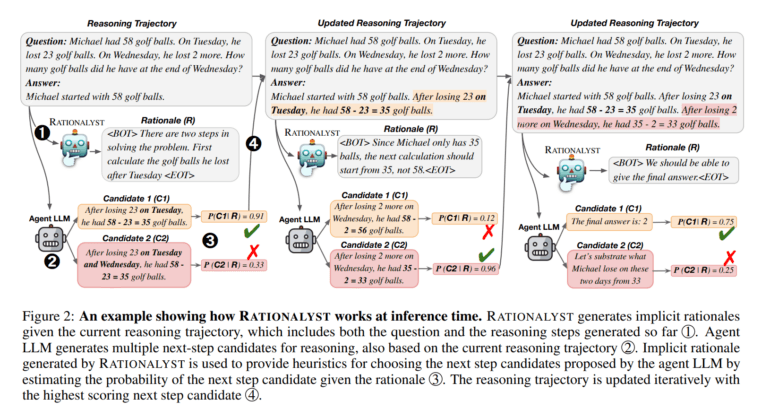
Die Forscher testeten RATIONALYST auf verschiedenen Reasoning-Aufgaben, darunter mathematisches, logisches und wissenschaftliches Schlussfolgern. Laut der Studie verbesserte der Einsatz von RATIONALYST die Genauigkeit des Reasonings im Durchschnitt um 3,9 Prozent auf sieben repräsentativen Benchmarks.
RATIONALYST übertrifft andere Verifier-Modelle
Besonders bemerkenswert ist, dass RATIONALYST in den Tests besser abschnitt als deutlich größere Verifier-Modelle wie GPT-4. Aktueller Modelle wie GPT-4o oder das auf Reasoning spezialisierte o1 wurden nicht getestet.
"Wir glauben, dass unser datenzentrischer Ansatz es RATIONALYST ermöglicht, Prozess-Supervision über verschiedene Reasoning-Aufgaben hinweg zu generalisieren, ohne dass dafür menschliche Annotation nötig ist", so das Team.
Die Forscher sehen in RATIONALYST daher einen vielversprechenden Ansatz, um die Interpretierbarkeit und Leistung von LLMs beim Reasoning zu verbessern. Durch die Generierung von menschenverständlichen Begründungen könnte das System besonders nützlich sein, wenn es um komplexe Domänen wie Mathematik oder Programmierung geht.
Zukünftige Forschung könne darauf abzielen, RATIONALYST mit noch stärkeren Modellen und größeren Datensätzen zu skalieren. Den Code gibt es auf GitHub.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.