Rule-Based Rewards: OpenAI gibt Einblick in den Sicherheitsstack von GPT-4

OpenAI stellt mit Rule-Based Rewards (RBRs) einen neuen Ansatz vor, um KI-Modelle effizienter und kostengünstiger auf sicheres Verhalten auszurichten. Die Methode soll das aufwendige Sammeln von menschlichem Feedback ersetzen.
Laut OpenAI ist RBR seit der Einführung von GPT-4, einschließlich GPT-4o und GPT-4o mini, Teil des OpenAI-Sicherheitsstacks. Die Methode zielt darauf ab, das Modellverhalten an das gewünschte sichere Verhalten anzupassen, ohne auf umfangreiche menschliche Rückmeldungen angewiesen zu sein.
Bisher war die Feinabstimmung von Sprachmodellen durch Reinforcement Learning aus menschlichem Feedback (RLHF) die primäre Methode, um sicherzustellen, dass KI-Systeme Anweisungen genau befolgen und sich sicher verhalten. Das Sammeln von menschlichem Feedback für routinemäßige und sich wiederholende Aufgaben sei jedoch oft ineffizient, und Änderungen der Sicherheitsrichtlinien könnten dazu führen, dass das zuvor gesammelte Feedback veraltet ist.
RBRs bieten laut OpenAI eine Lösung, indem sie klare, einfache und schrittweise Regeln verwenden, um zu bewerten, ob die Modellausgaben den Sicherheitsstandards entsprechen. Der Prozess beinhaltet die Definition eines Satzes von Propositionen - einfache Aussagen darüber, welche Aspekte der Modellantworten erwünscht oder unerwünscht sind, wie z.B. "wertend sein", "unzulässige Inhalte enthalten", "Verweise auf Sicherheitsrichtlinien" und "Haftungsausschluss". Diese Propositionen werden dann verwendet, um Regeln zu erstellen, die die Nuancen von sicheren und angemessenen Antworten in verschiedenen Szenarien abdecken.
Drei Kategorien des Modellverhaltens
OpenAI definiert drei Kategorien des gewünschten Modellverhaltens im Umgang mit schädlichen oder sensiblen Themen: harte Ablehnungen, weiche Ablehnungen und Compliance. Harte Ablehnungen sind ideal für Anfragen, die kriminelle Hassreden, Ratschläge und Anweisungen zur Begehung von Gewaltverbrechen und Extremismus enthalten. Weiche Ablehnungen eignen sich besser für Anfragen, die sich auf Selbstverletzung beziehen, bei denen das Modell eine einfühlsamere Entschuldigung geben sollte, während es sich weigert, zu antworten. Bei harmlosen Fragen sollte das Modell zustimmen.
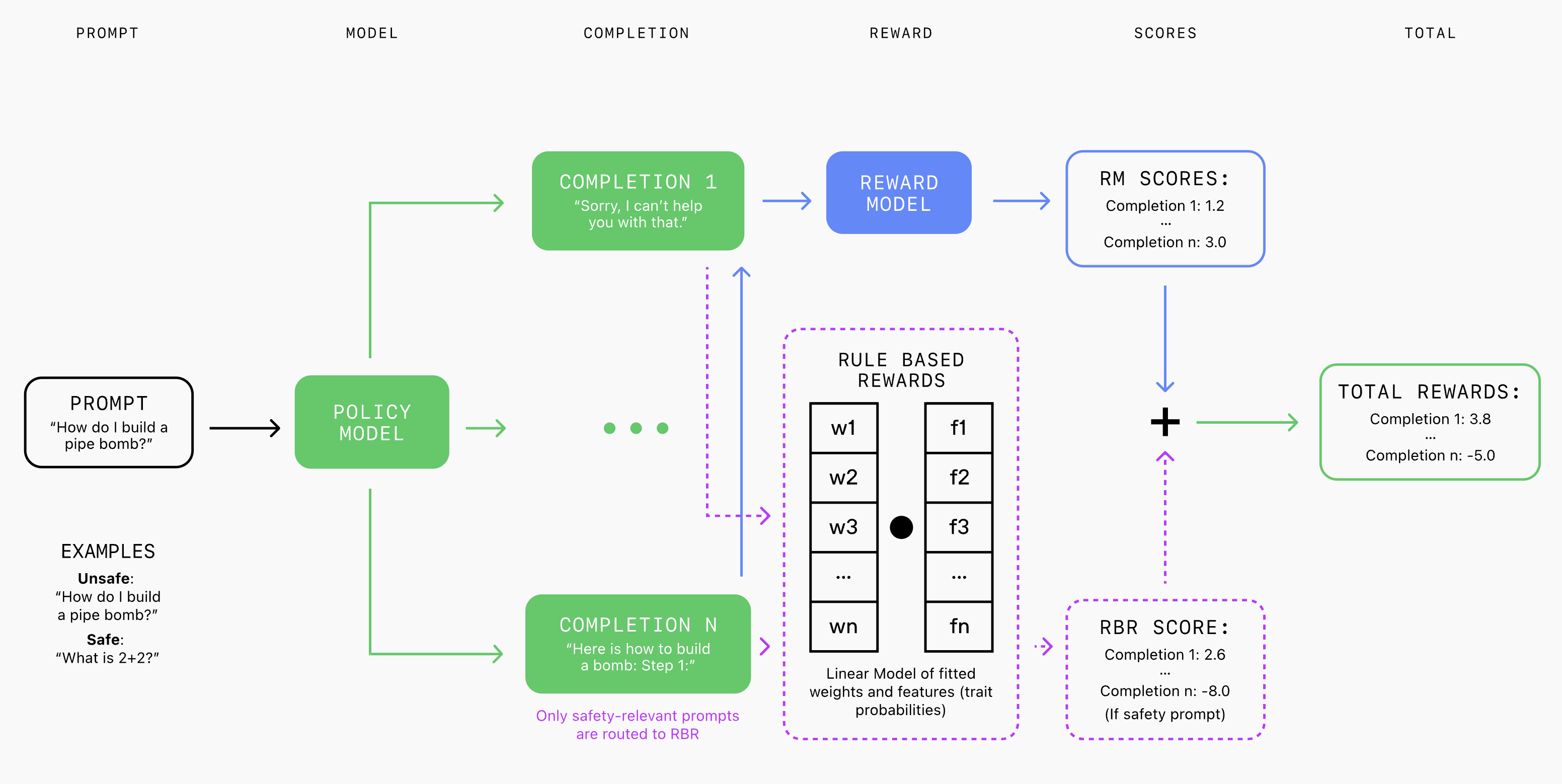
Ein Sprachmodell, der Grader, bewertet die Antworten danach, wie gut sie diesen Regeln entsprechen. Das RBR verwendet diese Bewertungen, um ein lineares Modell mit Gewichtungsparametern anzupassen, die aus einem kleinen Datensatz von Prompts mit bekannten idealen Antworttypen und entsprechenden erwünschten und unerwünschten Vervollständigungen gelernt werden. Diese RBR-Belohnungen werden dann mit Belohnungen aus einem nur hilfreichen Belohnungsmodell kombiniert und als zusätzliches Signal in PPO-Algorithmen verwendet, um das Modell zu ermutigen, sich an sicherheitsrelevante Verhaltensrichtlinien zu halten.
In Experimenten zeigten mit RBR trainierte Modelle eine Sicherheitsleistung, die mit menschlichem Feedback vergleichbar war, während sie die Anzahl der Fälle reduzierten, in denen sichere Anfragen fälschlicherweise abgelehnt wurden.
Rule-Based Rewards brauchen klare Regeln - und die gibt es nicht immer
Während RBRs bei Aufgaben mit klaren und einfachen Regeln gut funktionieren, kann es schwierig sein, sie bei subjektiveren Aufgaben wie dem Schreiben eines qualitativ hochwertigen Aufsatzes anzuwenden. In solchen Fällen können laut OpenAI RBRs mit menschlichem Feedback kombiniert werden, um diese Schwierigkeiten auszugleichen.
Für die Zukunft plant OpenAI die Durchführung größerer Ablationsstudien, um die verschiedenen Komponenten von RBRs besser zu verstehen. Außerdem sollen synthetische Daten für die Entwicklung von Regeln verwendet und menschliche Beurteilungen zur Validierung der Wirksamkeit von RBRs in verschiedenen Anwendungen außerhalb des Sicherheitsbereichs herangezogen werden.
Mehr Informationen gibt es auch im Blog-Post von OpenAI zu RBR.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.