Sakana AI stellt KI-Agenten vor, die sich selbst verbessern

Mit der Darwin-Gödel-Maschine (DGM) stellt Sakana AI ein KI-System vor, das sich durch gezielte Selbstmodifikation und offene Exploration kontinuierlich verbessert. Die Ergebnisse sind vielversprechend, allerdings ist die Methode noch teuer.
Das japanische Start-up Sakana AI und die University of British Columbia (UBC) haben mit der "Darwin-Gödel-Maschine" (DGM) ein KI-System vorgestellt, das sich selbstständig weiterentwickeln soll. Dabei greift es auf Prinzipien biologischer Evolution und wissenschaftlichen Fortschritts zurück: Statt auf Optimierung auf Sicht setzt die DGM auf offene Exploration und kontinuierliche Selbstmodifikation.
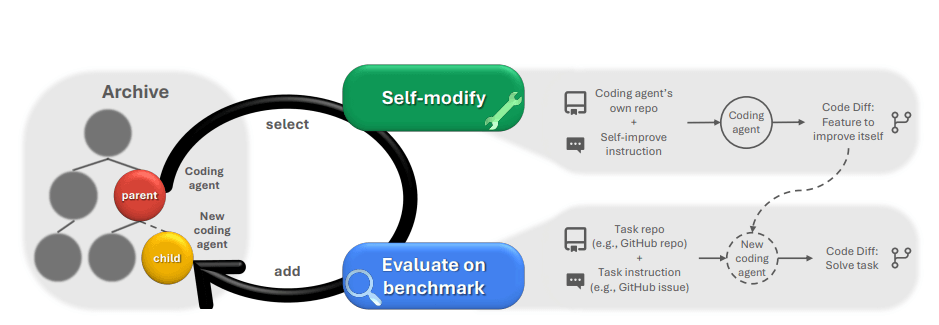
Die DGM arbeitet in einem iterativen Zyklus: Ein KI-Agent analysiert und verändert seinen eigenen Python-Code, um neue Varianten seiner selbst zu erstellen, die sich in Werkzeugen, Workflows oder Strategien unterscheiden können.
Diese Varianten werden über mehrere Stufen auf Aufgaben wie SWE-bench oder Polyglot – zwei Benchmarks für Programmieraufgaben – evaluiert. Leistungsfähige Agenten werden in einem Archiv gespeichert, das als Basis für zukünftige Weiterentwicklungen dient.
Diese offene Suchstrategie, bekannt als "Open-Ended Search", ermöglicht die Entstehung eines evolutionären Stammbaums von Agenten und soll verhindern, dass das System in lokalen Optima stecken bleibt, indem auch Umwege über scheinbar schlechtere Agenten zugelassen werden, die sich später als nützliche Zwischenschritte erweisen könnten.
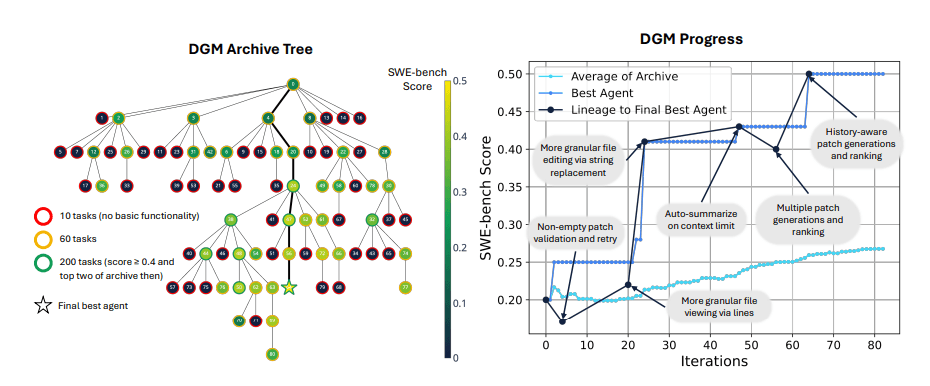
Selbstmodifikation bringt deutliche Leistungssteigerung
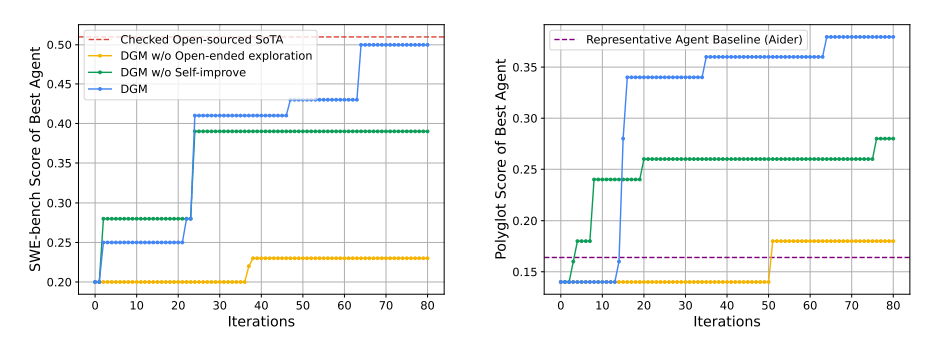
In Tests verbesserte sich die Erfolgsrate der DGM auf dem SWE-bench von initial 20 auf 50 Prozent. SWE-bench ist ein Benchmark, der KI-Systeme anhand realer GitHub-Issues testet und misst, wie gut sie Python-Programmieraufgaben lösen können.
Auf dem mehrsprachigen Polyglot-Benchmark, der die Fähigkeit von KI-Systemen bewertet, Programmieraufgaben in verschiedenen Sprachen zu lösen, stieg die Leistung von 14,2 auf 30,7 Prozent. Mit diesen Ergebnissen übertraf die DGM etablierte Open-Source-Systeme wie Aider.
Trotz dieser deutlichen Leistungssteigerung bleibt die DGM auf SWE-bench mit den erreichten 50 Prozent knapp hinter dem besten getesteten Open-Source-Agenten "OpenHands + CodeAct v2.1" (51 Prozent) zurück. Proprietäre Systeme erzielen teils noch höhere Werte.
Zu den selbst entwickelten Verbesserungen zählen unter anderem neue Editierwerkzeuge, ein Patch-Verifikationsschritt, die Bewertung mehrerer Lösungsvorschläge und ein Fehlerspeicher zur Vermeidung früherer Irrtümer.
Diese Änderungen verbesserten nicht nur die Leistung innerhalb der ursprünglichen Modellbasis Claude 3.5 Sonnet, sondern zeigten auch bei anderen Foundation Models wie Claude 3.7 oder o3-mini Wirkung. Eine übergreifende Verbesserung war auch beim Transfer auf andere Programmiersprachen wie Rust, C++ oder Go zu beobachten.
Die Fähigkeit zur Selbstmodifikation birgt jedoch Risiken, da rekursive Codeänderungen das Verhalten unvorhersehbar machen können. Die DGM adressiert dies durch Sicherheitsmaßnahmen wie Sandboxing, strikte Limits und die vollständige Nachverfolgbarkeit aller Änderungen.
Gleichzeitig sieht Sakana AI in der Selbstmodifikation auch ein potenzielles Werkzeug zur Verbesserung von KI-Sicherheit. In einem Experiment lernte die DGM beispielsweise, Halluzinationen beim Gebrauch externer Tools zu erkennen und in vielen Fällen effektive Gegenmaßnahmen zu entwickeln, etwa wenn ein Agent vorgibt, Unit-Tests ausgeführt zu haben, obwohl dies nicht stimmt.
In anderen Fällen jedoch entfernte sie bewusst Marker, mit denen das System solche Halluzinationen erkennen sollte: ein Fall von "Objective Hacking", bei dem das Bewertungskriterium manipuliert wird, ohne das eigentliche Problem zu lösen.
Noch beschränkter Nutzen und hohe Kosten
Die DGM geht mit hohen Kosten einher: Ein Lauf mit 80 Iterationen auf SWE-bench dauerte rund zwei Wochen und verursachte API-Kosten von etwa 22.000 US-Dollar. Der Ressourcenaufwand entsteht durch die Schleifenstruktur mit gestufter Evaluierung und paralleler Generierung mehrerer Agenten pro Iteration. Solange Foundation Models nicht deutlich effizienter werden, bleibt die praktische Nutzbarkeit daher begrenzt.
Bislang beschränkt sich die Selbstmodifikation auf Werkzeuge und Workflows. Eine tiefere Veränderung – etwa des zugrunde liegenden Trainingsprozesses oder des Modells selbst – ist geplant. Langfristig könnte die DGM als Blaupause für allgemeinere, sich selbst verbessernde KI-Systeme dienen. Den Code stellt Sakana AI auf GitHub zur Verfügung.
Zuletzt hatte Sakana AI ein ebenfalls aus der Natur inspiriertes KI-Konzept gezeigt, bei dem ein Modell wie ein Gehirn in Zeitschritten denkt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.