Sakana AIs KI-Agent schafft es unter die besten 21 von 1000 Code-Experten

Das japanische Unternehmen Sakana AI hat einen KI-Agenten entwickelt, der komplexe Optimierungsprobleme aus der Industrie lösen kann. In einem Live-Test trat die KI gegen mehr als 1000 menschliche Expert:innen an.
Der ALE-Agent von Sakana AI belegte bei der 47. Ausgabe des AtCoder Heuristic Contest den 21. Platz und bewies damit, dass KI-Systeme bei anspruchsvollen Programmieraufgaben mit menschlichen Expert:innen konkurrieren können.
AtCoder ist eine japanische Plattform für Programmierwettbewerbe, bei denen Teilnehmer:innen komplexe mathematische Probleme durch Code lösen müssen. Die Probleme sind sogenannte "NP-harte" Aufgaben, für die es keine bekannten effizienten Lösungsverfahren gibt.
Die Aufgaben spiegeln reale industrielle Herausforderungen wider: Routenplanung für Lieferfahrzeuge, optimale Arbeitsschichtaufteilung, Produktionsorganisation in Fabriken und Stromnetze-Balancing. Menschliche Teilnehmer:innen investieren normalerweise erhebliche Anstrengungen über Wochen, um ihre Lösungen zu verbessern.
Der Erfolg basiert auf ALE-Bench, dem laut Sakana AI ersten Benchmark für Score-basierte algorithmische Programmierung. Der Benchmark umfasst 40 schwere Optimierungsprobleme aus vergangenen AtCoder Heuristic Contests. Anders als bisherige Tests, die nur richtig oder falsch bewerten, erfordert ALE-Bench kontinuierliche Lösungsverbesserung über längere Zeiträume.
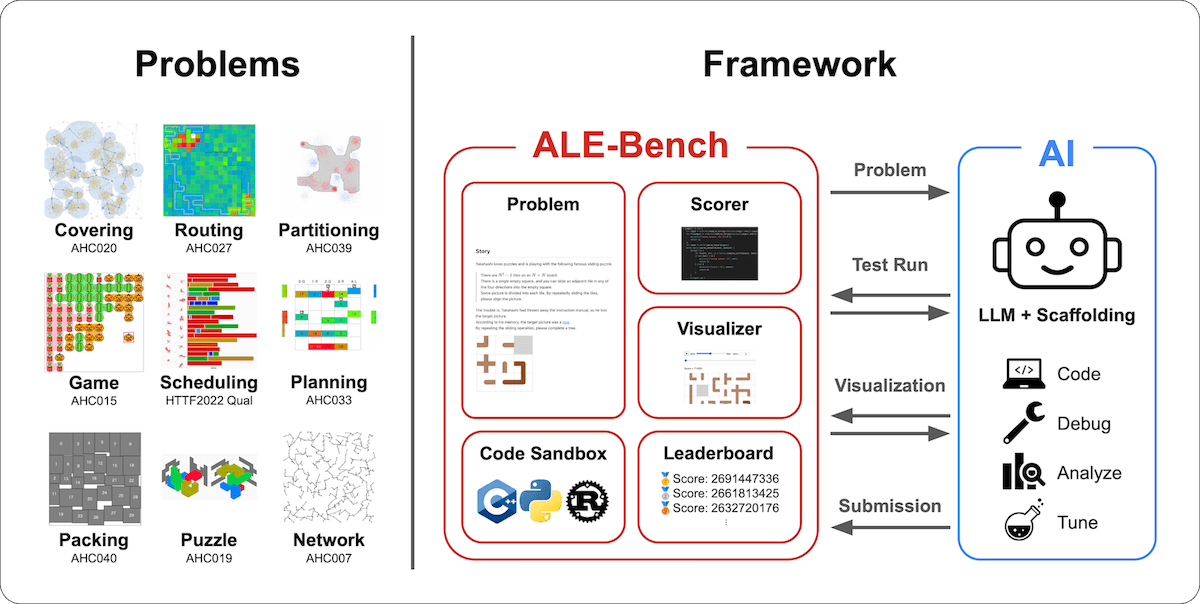
KI-Agent kombiniert Fachwissen mit systematischer Suche
Der ALE-Agent basiert auf Googles Sprachmodell Gemini 2.5 Pro und kombiniert zwei Hauptansätze. Die erste Methode fügt Expertenwissen über bewährte Lösungsverfahren direkt in die Anweisungen an die KI ein. Dazu gehören Techniken wie "Simulated Annealing" (simulierte Abkühlung), ein Verfahren, das zufällige Änderungen an einer Lösung testet und schlechtere Lösungen manchmal akzeptiert, um aus lokalen Sackgassen herauszufinden.
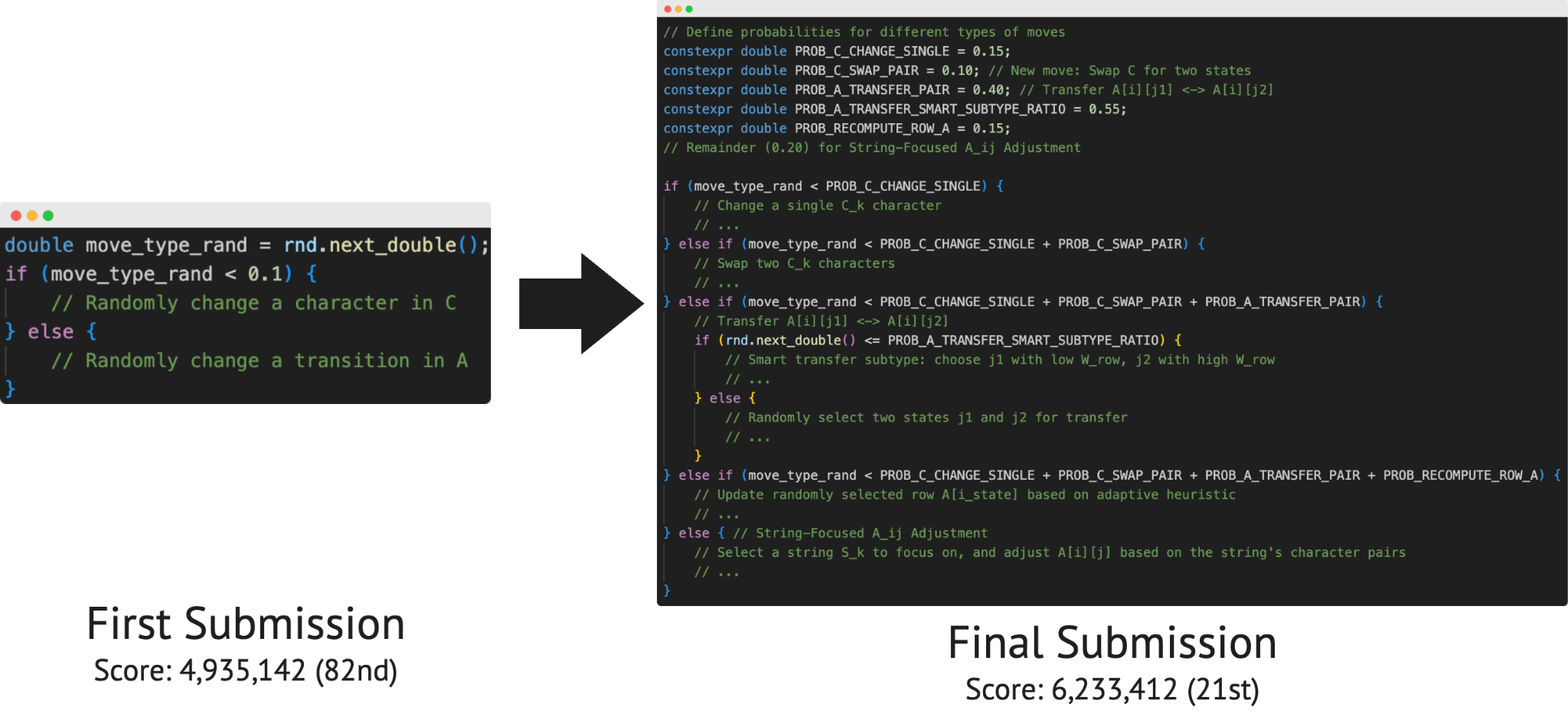
Die zweite Methode verwendet einen systematischen Suchalgorithmus namens "Best-First-Search". Dieser wählt immer die vielversprechendste Teillösung aus und entwickelt sie weiter. Der Agent erweitert diesen Ansatz um eine "Beam-Search"-ähnliche Expansion und verfolgt gleichzeitig 30 verschiedene Lösungsansätze parallel. Zusätzlich verwendet der Agent einen "Tabu-Search"-Mechanismus, der bereits getestete Lösungswege speichert und deren Wiederholung verhindert.
KI übertrifft Menschen durch hohe Anzahl an Versuchen
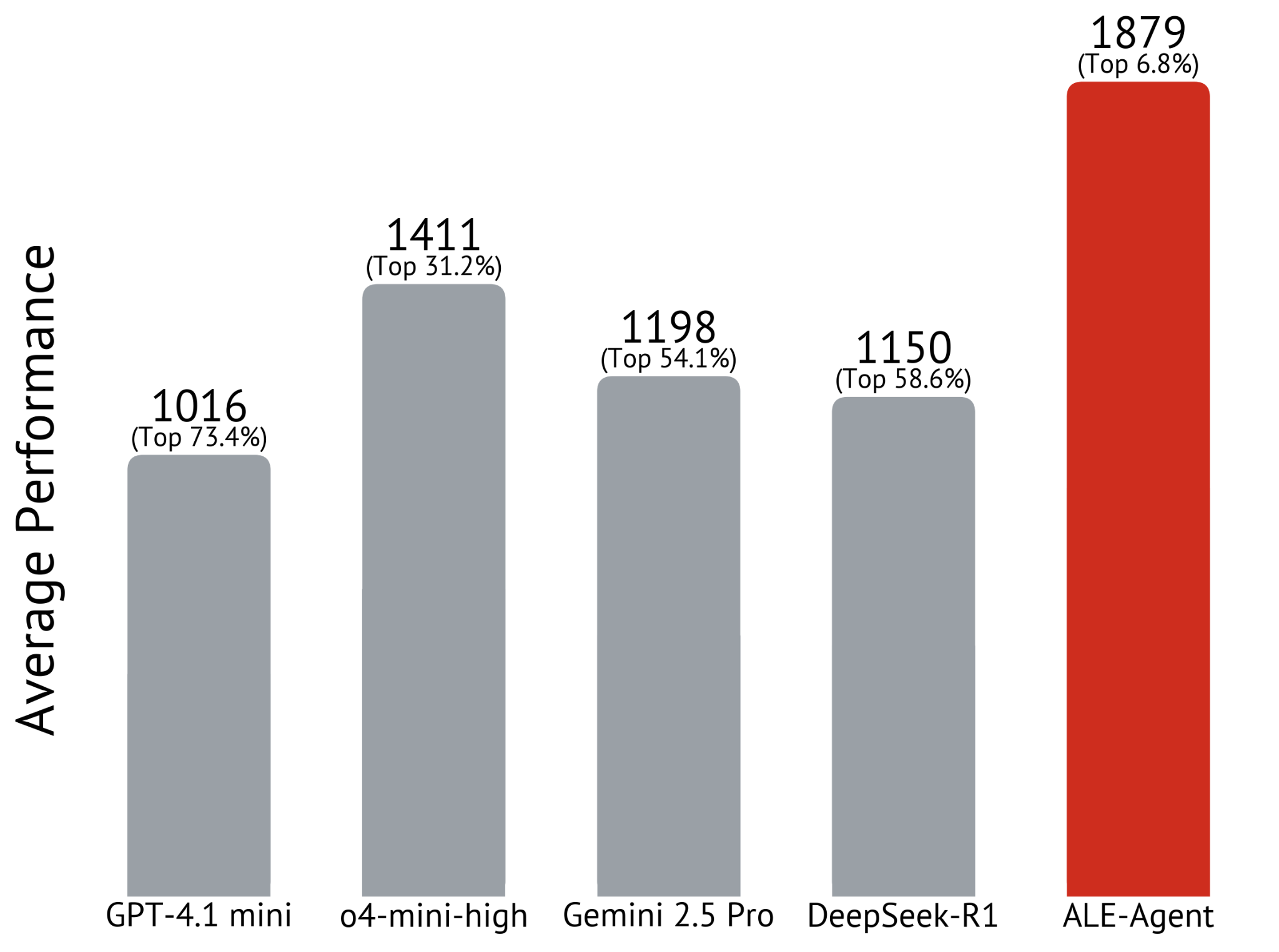
In Experimenten erreichte das beste getestete Modell o4-mini-high mit sequenziellen Verbesserungen 1.411 Punkte. GPT-4.1 mini brachte es unter den gleichen Voraussetzungen auf 1.016 Punkte, Deepseek-R1 auf 1.150 Punkte und Gemini 2.5 Pro auf 1.198 Punkte.
Der vollständige ALE-Agent übertraf diese Ergebnisse mit 1.879 Punkten, was wiederum den besten 6,8 Prozent entspricht. Bei einem spezifischen Problem erzielte der Agent 2.880 Punkte, was dem 5. Platz im ursprünglichen Wettbewerb entsprochen hätte.
Die Analyse zeigt einen weiteren wichtigen Unterschied zwischen KI und menschlichen Problemlösern: die Geschwindigkeit. Während Menschen in einem vierstündigen Wettbewerb höchstens etwa zwölf verschiedene Code-Versionen ausprobieren können, schafft die KI von Sakana AI etwa 100 Überarbeitungen. Der ALE-Agent generierte sogar Hunderte oder Tausende potenzielle Lösungen.
Benchmark als Grundlage für weitere KI-Entwicklung
ALE-Bench ist als Python-Bibliothek verfügbar und bietet eine "Code-Sandbox", eine isolierte Umgebung zur sicheren Code-Ausführung. Das Framework unterstützt die Programmiersprachen C++, Python und Rust und läuft auf standardisierten Amazon-Cloud-Servern.
Sakana AI entwickelte den Benchmark in Zusammenarbeit mit AtCoder Inc. Die Daten von 40 Wettbewerbsproblemen sind auf Hugging Face und der nötige Code auf GitHub öffentlich verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.