Salesforce-Benchmark zeigt: KI-Agenten scheitern an komplexen Geschäftsdialogen

Salesforce hat mit CRMArena-Pro einen neuen Benchmark für KI-Agenten vorgestellt. Selbst Top-Modelle wie Gemini 2.5 Pro erreichen in einfachen Aufgaben nur 58 Prozent Erfolgsquote. Bei längeren Dialogen fällt die Leistung auf 35 Prozent.
CRMArena-Pro soll die Fähigkeiten großer Sprachmodelle (LLMs) in realitätsnahen Unternehmensszenarien testen. Das System wurde speziell für den Einsatz in CRM-Umgebungen (Customer Relationship Management) entwickelt und erweitert das bisherige CRMArena-Framework um zusätzliche Geschäftsfunktionen, Multi-Turn-Dialoge und Datenschutztests.
Das Ziel: herausfinden, wie gut sich LLMs als Agenten in operativen Geschäftsprozessen schlagen – etwa im Vertrieb, Kundenservice oder Preisgestaltung. Die Testumgebung basiert auf synthetisch generierten Daten, die in ein Salesforce-Org integriert wurden. Insgesamt wurden 4.280 Aufgabeninstanzen erstellt, verteilt auf 19 Geschäftstätigkeiten und drei Datenschutzkategorien.
Erfolgsquote bricht bei längeren Dialogen massiv ein
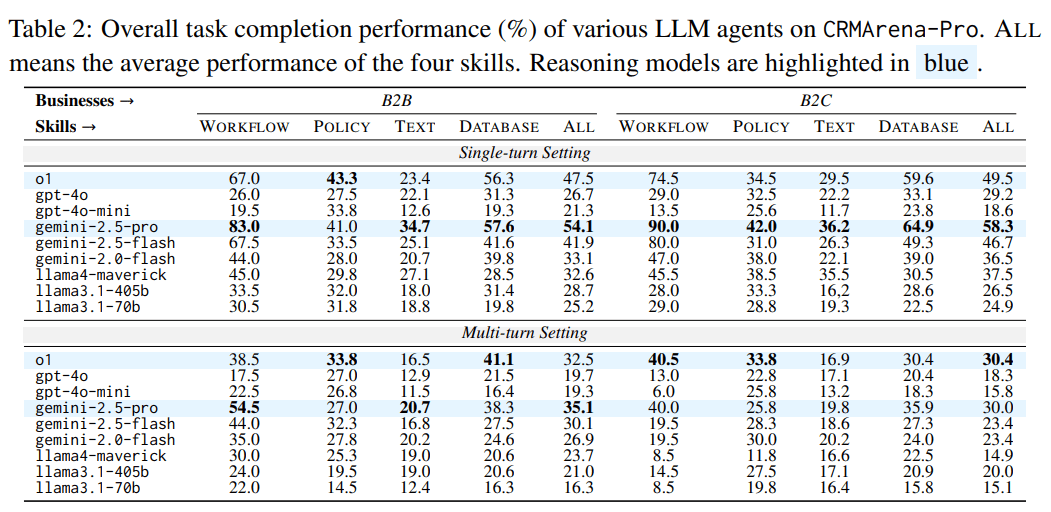
Die Ergebnisse zeigen klare Grenzen aktueller LLM-Technologie: In einfachen, einstufigen Aufgaben (Single-Turn) erreichen selbst fortschrittliche Modelle wie Gemini 2.5 Pro nur etwa 58 Prozent Erfolgsquote.
Sobald jedoch mehrere Gesprächsrunden (Multi-Turn) nötig sind – etwa um fehlende Informationen durch Rückfragen zu ermitteln – sinkt die Leistung auf rund 35 Prozent. Das geht aus umfangreichen Tests hervor, die Salesforce mit neun LLMs durchgeführt hat.
Insbesondere die Fähigkeit, gezielt nachzufragen, fehlt vielen Modellen. In einer Stichprobe von 20 fehlgeschlagenen Multi-Turn-Aufgaben mit Gemini 2.5 Pro zeigte sich, dass in fast der Hälfte der Fälle entscheidende Informationen nicht korrekt erfragt wurden. Modelle, die häufiger Rückfragen stellen, schneiden in Multi-Turn-Aufgaben besser ab. Gute Dialogführung bleibt also ein entscheidender Faktor für den praktischen Einsatz von KI-Agenten.
Am besten schnitten die Modelle bei Workflows ab – etwa bei der automatisierten Fallzuweisung im Kundenservice. Gemini 2.5 Pro erreichte in diesem Bereich Erfolgsraten von über 83 Prozent. Deutlich schlechter war die Leistung bei Aufgaben, die Textverständnis oder Regelkonformität erfordere, etwa das Erkennen ungültiger Produktkonfigurationen oder das Ableiten von Informationen aus Gesprächsprotokollen.
Schon zuvor zeigte eine Studie von Salesforce und Microsoft, dass KI-Modelle in dialogischen Kontexten Schwierigkeiten haben, gezielt nach fehlenden Informationen zu fragen, selbst wenn diese für die erfolgreiche Bearbeitung einer Aufgabe erforderlich sind. Die Leistung der Systeme brach dabei im Durchschnitt um 39 Prozent ein.
Datenschutzbewusstsein kaum vorhanden
Ein weiteres Ergebnis: LLMs erkennen sensible Daten wie personenbezogene Informationen oder interne Unternehmenskennzahlen praktisch nicht. In der Standardkonfiguration verweigerten sie entsprechende Anfragen fast nie.
Erst durch gezielte Anpassung des Systemprompts, der auf Datenschutzrichtlinien hinweist, stieg die Ablehnungsquote bei heiklen Fragen, allerdings auf Kosten der Aufgabenleistung. GPT-4o etwa verbesserte seine Vertraulichkeitserkennung von 0 auf 34,2 Prozent, verlor dabei jedoch 2,7 Prozentpunkte bei der Zielerreichung.
Autor Kung-Hsiang Steeve Huang weist darauf hin, dass Datenschutztests bisher kaum in Benchmarks integriert wurden. CRMArena-Pro ist laut ihm der erste systematische Versuch, diese Dimension zu messen
Open-Source-Modelle wie LLaMA-3.1 reagierten deutlich schwächer auf solche Promptanpassungen. Laut Salesforce könnten diese Modelle von besserem Training im Umgang mit priorisierten Instruktionen profitieren.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.