Selective Language Modeling: Neue Methode macht bessere Modelle mit weniger Daten möglich
Forscher stellen die neue Methode "Selective Language Modeling" vor, die Sprachmodelle effizienter trainiert, indem sie sich auf die relevantesten Tokens konzentriert. Die Methode führt zu deutlichen Leistungssteigerungen bei mathematischen Aufgaben.
Forscher von Microsoft, der Xiamen University und der Tsinghua University haben eine neue Methode entwickelt, um Sprachmodelle effizienter zu trainieren. Statt wie bisher alle Tokens in einem Textkorpus gleichermaßen beim Training zu berücksichtigen, konzentriert sich die Methode "Selective Language Modeling" (SLM) gezielt auf die relevantesten Tokens.
Zunächst analysierten die Wissenschaftler die Trainingsdynamik auf Token-Ebene. Dabei stellten sie fest, dass sich der Verlust für verschiedene Token-Typen im Training sehr unterschiedlich entwickelt. Einige Tokens werden schnell gelernt, andere kaum.
Basierend auf diesen Erkenntnissen entwickelten die Forscher ein dreistufiges Verfahren: Zunächst wird ein Referenzmodell auf einem hochwertigen, manuell gefilterten Datensatz trainiert, etwa für Mathematik. Mit dem Referenzmodell wird dann der Verlust für jedes Token im gesamten Trainingskorpus berechnet, das auch viele irrelevante Token enthält. Das eigentliche Sprachmodell wird dann selektiv auf die Token trainiert, die eine hohe Differenz zwischen dem Verlust des Referenzmodells und dem aktuellen Modell aufweisen.
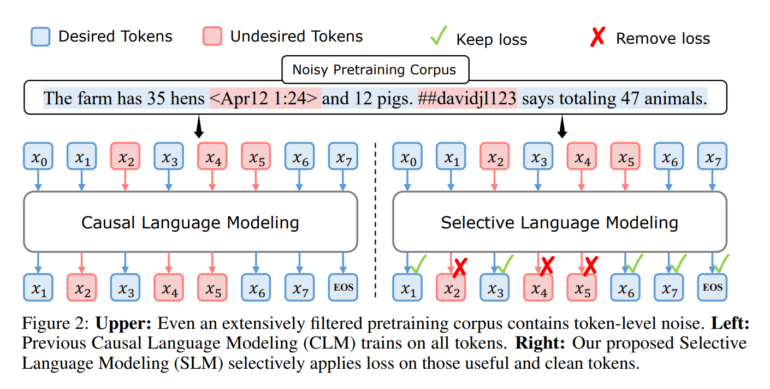
Im mathematischen Beispiel erhalten Tokens in Sätzen wie "2 + 2 = 4" oder "Die Ableitung von sin(x) ist cos(x)" eine niedrige Perplexität, da sie gut zum gelernten Wissen des Referenzmodells passen. Tokens in Sätzen wie "Klicken Sie hier für eine tolle Versicherung" erhalten eine hohe Perplexität, da sie nichts mit Mathematik zu tun haben. Während solche Fälle mit klassischen Filterverfahren noch relativ zuverlässig aus dem Trainingsdatensatz entfernt werden können, wird dies bei Sätzen wie "The farm has 35 hens <Apr12 1:24> and 12 pigs. ##davidjl123 says totaling 47 animals." schwieriger. Dieser Satz enthält sowohl nützliche Informationen (die Anzahl der Tiere auf dem Bauernhof) als auch irrelevante bzw. fehlerhafte Informationen (das Datum, den Benutzernamen, den Rechtschreibfehler "totaling"). Da das Verfahren auf Token-Ebene arbeitet, kann es auch hier die für das Training relevanten Token priorisieren.
Auf diese Weise lernt das System gezielt die Token, die für die Zielaufgabe am relevantesten sind.
Selective Language Modeling trainiert schneller und erhöht die Genauigkeit
In der Mathematik hat SLM in verschiedenen Benchmarks wie GSM8K und MATH zu einer Genauigkeitssteigerung von über 16 % im vom Team vorgestellten RHO-1-Modell mit 1 Milliarde Parametern geführt. Außerdem wurde die Genauigkeit der Baseline bis zu 10 Mal schneller erreicht. Die 7-Milliarden-Parameter Variante von RHO-1 erreichte mit nur 15 Milliarden Trainingstoken eine vergleichbare Performance wie ein DeepSeekMath-Modell, das mit 500 Milliarden Token trainiert wurde. Nach dem Feintuning erreichten die SLM-Modelle neue Bestwerte auf dem MATH-Datensatz.
Auch außerhalb der Mathematik verbesserte SLM die Leistung des Tinyllama-1B-Modells nach dem Training mit 80 Milliarden Tokens um durchschnittlich 6,8% über 15 Benchmarks. Besonders ausgeprägt waren die Zugewinne bei Code- und Mathematikaufgaben mit über 10 %.
Die Forscher führen den Erfolg von SLM darauf zurück, dass die Methode Tokens identifiziert, die für die gewünschte Verteilung relevant sind. Sie hoffen, dass der Ansatz dazu beitragen kann, maßgeschneiderte KI-Modelle schneller und kostengünstiger zu entwickeln. Die Methode könnte zudem Open-Source-Modelle wie Metas Llama 3 durch auf SLM basierendes Fine-Tuning weiter verbessern.
Mehr Informationen, den Code und das RHO-1-Modell gibt es auf GitHub.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.