SenseNova 5o: Chinas Sensetime gibt erste Antwort auf OpenAIs GPT-4o

Das chinesische KI-Unternehmen SenseTime hat auf der World Artificial Intelligence Conference sein neues multimodales KI-Modell SenseNova 5o und das verbesserte LLM SenseNova 5.5 vorgestellt.
SenseNova 5o ist laut SenseTime das erste multimodale Echtzeitmodell Chinas, das multimodale KI-Interaktion auf dem Niveau von GPT-4o bietet. Es verarbeitet Audio-, Text-, Bild- und Videodaten, und Benutzer können mit dem Modell wie in einem Gespräch interagieren.
Laut Sensetime ist es besonders für Echtzeitgespräche und Spracherkennung geeignet. Die von SenseTime gezeigte Demo erinnerte an die GPT-4o-Demo von OpenAI Anfang Mai, inklusive der Vision-Fähigkeiten. So kann das Modell etwa einzelne Objekte erkennen und beschreiben.
Video: via Sensetime
Allerdings zeigte OpenAI neben Sprache viele weitere multimodale Fähigkeiten, insbesondere bei der Bilderzeugung, die Sensetime für SenseNova nicht erwähnt.
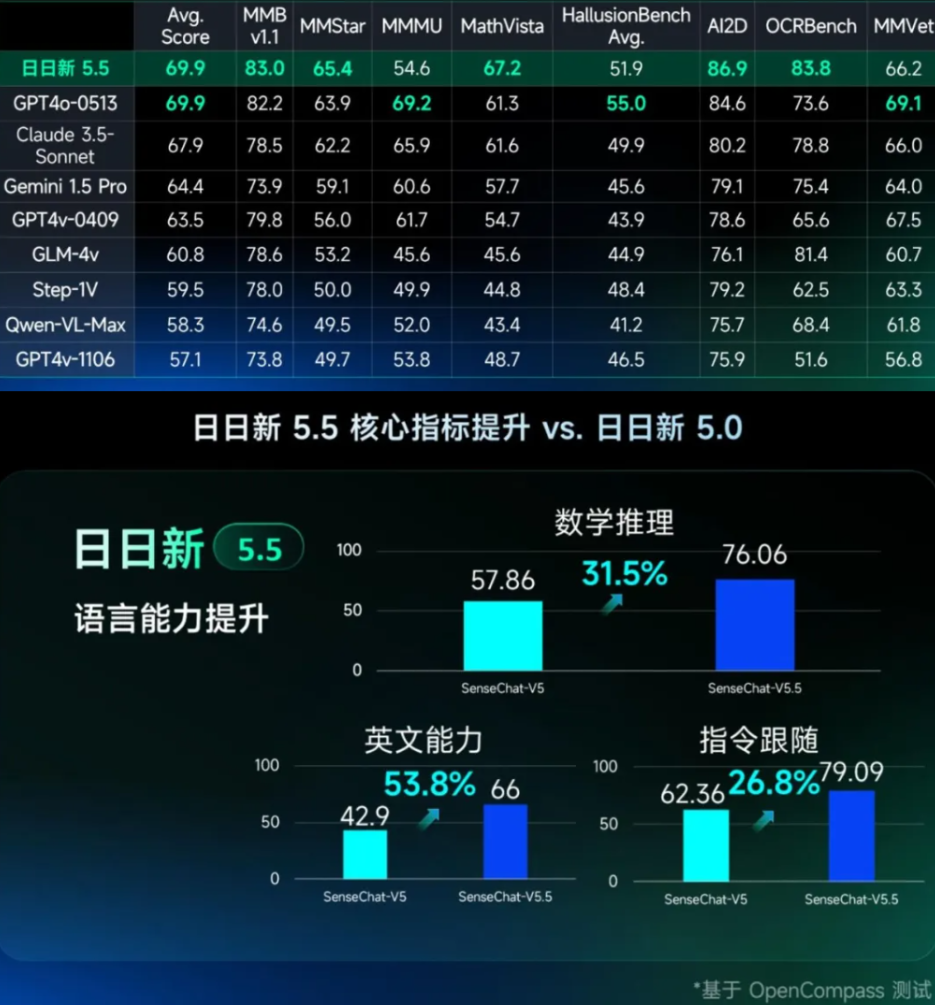
SenseTime aktualisiert auch sein großes Sprachmodell SenseNova. Die neue Version 5.5 erreicht laut SenseTime zwei Monate nach ihrer Einführung eine Leistungssteigerung von 30 Prozent gegenüber der Version 5.0.
Für das Training nutzte SenseTime nach eigenen Angaben mehr als zehn Terabyte hochwertiger Daten, darunter viele synthetisch generierte Argumentationsketten zur Verbesserung der Denkfähigkeiten.
Mit deutlich verbesserten Fähigkeiten im mathematischen Denken (+31,5 %), in Englisch (+53,8 %) und im Prompt-Following (+26,8 %) liegen die Interaktivität und viele Kernindikatoren laut Sensetime auf dem Niveau von GPT-4o.
Derzeit kommt das SenseNova Large Model laut SenseTime bei mehr als 3.000 Regierungs- und Unternehmenskunden in Branchen wie Technologie, Gesundheitswesen, Finanzen und Programmierung zum Einsatz.
SenseTime investiert auch in die Entwicklung von Edge-basierten LLMs, die schnell und kostengünstig sind. Mit SenseChat Lite-5.5 wurde die Inferenzzeit auf 0,19 Sekunden reduziert, 40 Prozent schneller als Version 5.0, und die Inferenzgeschwindigkeit wurde um 15 Prozent auf 90,2 Wörter pro Sekunde erhöht.
Der KI-Avatar-Videogenerator Vimi, der Teil von SenseNova 5.5 ist, soll aus einem einzigen Foto bis zu einminütige Clips mit präziser Steuerung von Mimik, Beleuchtung und Hintergrund erzeugen.
Video: via Sensetime
SenseTime CEO Dr. Xu Li sieht 2024 als entscheidendes Jahr für Large Models, die sich von unimodalen zu multimodalen Modellen entwickeln würden. SenseTime konzentriere sich auf die Steigerung der Interaktivität von KI-Modellen. Der CEO verspricht beispiellose Veränderungen in der Mensch-KI-Interaktion.
SenseTime aus Hongkong gehört zu den am besten finanzierten KI-Unternehmen. Das 2014 gegründete Unternehmen hat in den letzten Jahren vor allem mit visueller Überwachungssoftware via Gesichtserkennung für Schlagzeilen gesorgt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.