So will OpenAI katastrophalen KI-Risiken vorbeugen

OpenAI stellt ein neues Framework vor, das helfen soll, katastrophale Risiken durch KI zu verhindern. Insgesamt beschäftigt das Start-up nun drei Teams, die sich ausschließlich mit KI-Risiken befassen.
Das "Preparedness Framework" ist ein lebendiges Dokument, das Strategien zur Überwachung, Bewertung, Vorhersage und Absicherung gegen KI-Katastrophenrisiken beschreibt.
Es basiert auf fünf strategischen Pfeilern. Die erste ist die Überwachung des Katastrophenrisikos durch genaue Bewertungen. OpenAI hat sich zum Ziel gesetzt, Bewertungsverfahren und andere Überwachungsmethoden zu entwickeln und zu verfeinern, um das Risikoniveau genau zu messen.
Gleichzeitig will die Organisation zukünftige Risikoentwicklungen prognostizieren, um die rechtzeitige Vorbereitung von Sicherheitsmaßnahmen zu ermöglichen.
OpenAI verpflichtet sich zudem, aufkommende Risiken ("unbekannte Unbekannte") zu identifizieren und zu untersuchen. Auf diese Weise sollen potenzielle Bedrohungen angegangen werden, bevor sie eskalieren.
Cybersicherheit, Biowaffen, Überzeugungskraft und Autonomie
Das Preparedness Framework identifiziert vier Hauptrisikokategorien:
- Cyber-Sicherheit,
- chemische, biologische, nukleare und radiologische Bedrohungen (CBRN),
- Persuasion
- und Modellautonomie.
Persuasion konzentriert sich auf die Risiken, die damit verbunden sind, Menschen zu überzeugen, ihre Überzeugungen zu ändern oder entsprechend zu handeln.
OpenAI-CEO Sam Altman schrieb dazu vor Kurzem vorausschauend auf Twitter: "Ich erwarte, dass KI übermenschliche Persuasion beherrschen wird, lange bevor wir übermenschliche allgemeine Intelligenz haben, was wahrscheinlich zu sehr seltsamen Ergebnissen führen wird."
Von gering bis kritisch
Das Rahmenwerk definiert Sicherheitsschwellen. Jede Kategorie wird auf einer Skala von "gering" bis "kritisch" bewertet, die den Grad des Risikos widerspiegelt.
Modelle mit einer Risikobewertung nach Schadensbegrenzung von "mittel" oder niedriger sind für den Betrieb geeignet.
Nur Modelle mit einer Risikobewertung nach Schadensbegrenzung von maximal "hoch" oder niedriger können weiterentwickelt werden. Modelle, die als "kritisch" eingestuft werden, dürfen nicht weiterentwickelt werden.
Ein spezielles Preparedness-Team innerhalb von OpenAI wird die Risikoforschung, -bewertung, -überwachung und -prognose vorantreiben. Dieses Team wird regelmäßig der Safety Advisory Group (SAG) Bericht erstatten, einem Beratungsgremium, das das Management und den Vorstand von OpenAI dabei unterstützt, fundierte Sicherheitsentscheidungen zu treffen.
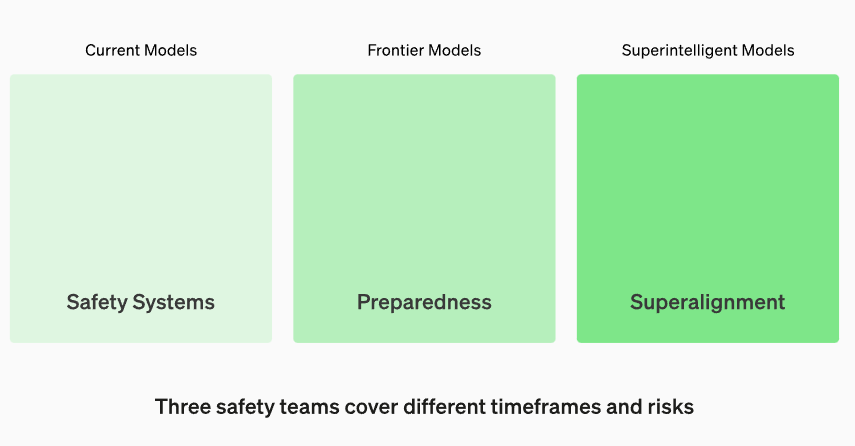
Das Preparedness-Team ist eines von drei OpenAI-Sicherheitsteams. Neben dem Preparedness-Team gibt es das Safety Systems-Team, das sich mit aktuellen Modellen befasst, und das Superalignment-Team, das mögliche Bedrohungen durch Super-KI antizipieren soll. Das Prepardness-Team bewertet grundlegende KI-Modelle.
Scorecard und Governance-System
Das Preparedness Framework stellt eine dynamische Scorecard zur Verfügung, die das aktuelle Modellrisiko vor und nach der Risikominderung für jede Risikokategorie misst. Dazu definiert OpenAI Sicherheitsgrundsätze und Verfahrensanforderungen.
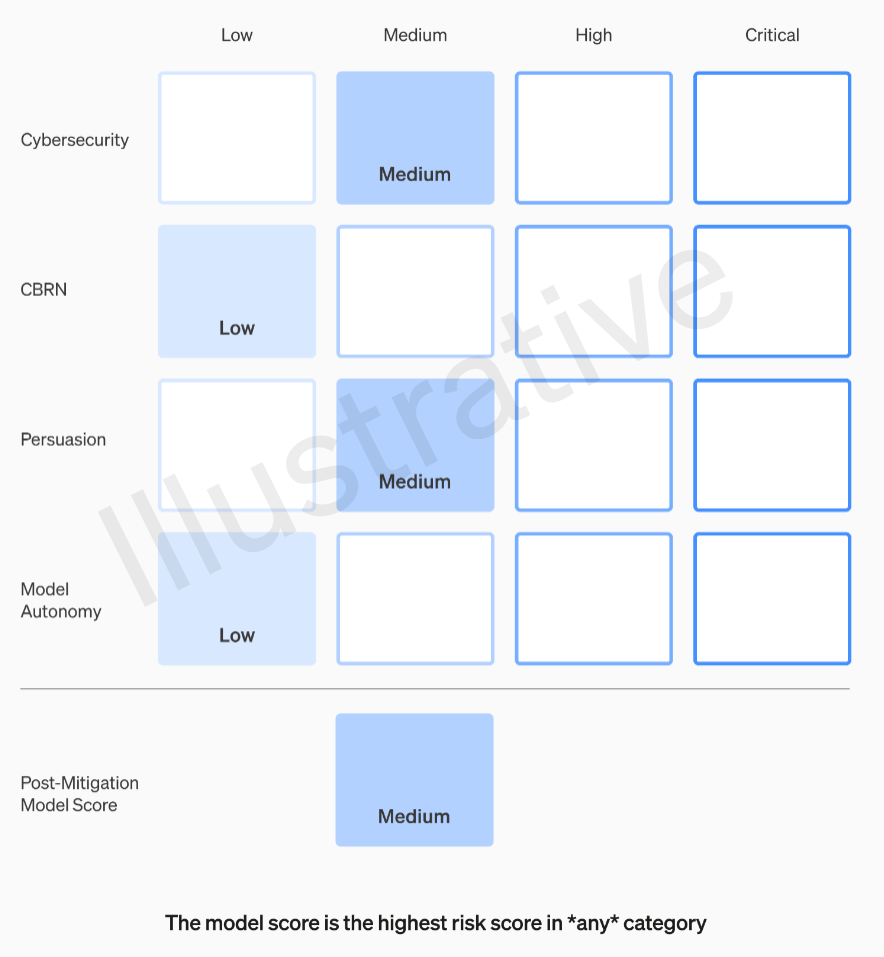
Zur Veranschaulichung der praktischen Anwendung beschreibt OpenAI zwei mögliche Szenarien (verkürzte Wiedergabe, vollständige Beschreibung im Paper).
Überzeugungsrisiko-Szenario: Wird für ein neu trainiertes Modell vor der Risikominderung ein "hohes" Überzeugungsrisiko festgestellt, werden die Sicherheitsfunktionen aktiviert und die Risikominderungsmaßnahmen durchgeführt. Nach diesen Schritten wird das Risiko nach der Risikominderung als "mittel" eingestuft.
Cyber-Sicherheitsrisiko-Szenario: Nach der Entdeckung einer neuen, mächtigen Prompt-Technik wird innerhalb von sechs Monaten ein "kritisches" Cyber-Sicherheitsrisiko vorhergesagt. Das löst die Ausarbeitung von Sicherheitsplänen und die Umsetzung von Sicherheitsmaßnahmen aus, um sicherzustellen, dass das Risiko nach Abhilfemaßnahmen auf einem "hohen" Niveau gehalten wird.
OpenAI fordert zum Schutz der Menschheit vor potenziellen KI-Bedrohungen andere Akteure der Branche auf, ähnliche Strategien zu verfolgen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.