Sprachmodell Intellect-1 wurde auf mehreren Kontinenten gleichzeitig trainiert

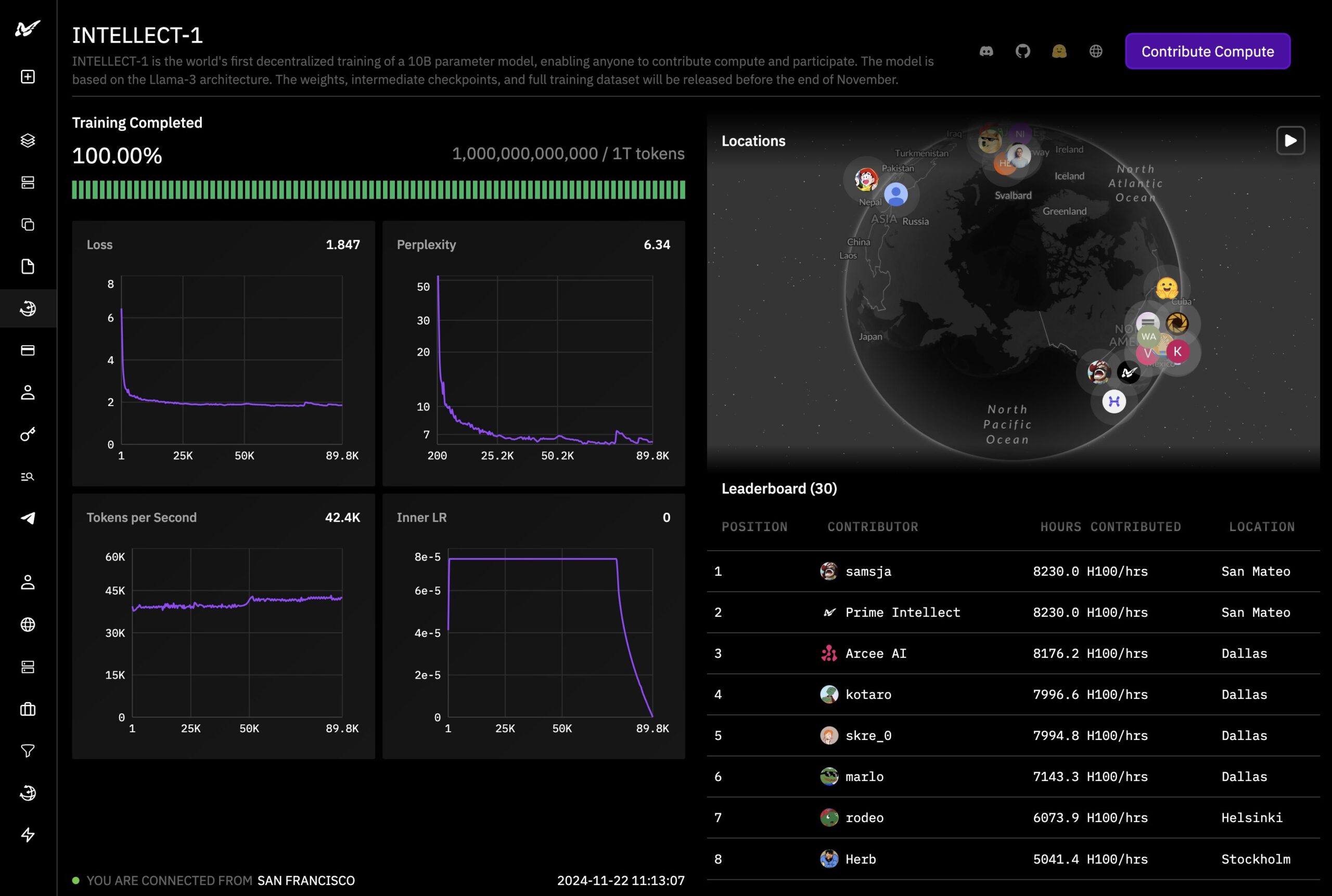
Das KI-Start-up Prime Intellect hat nach eigenen Angaben einen Meilenstein erreicht: Nach elf Tagen Training auf Rechnern in den USA, Europa und Asien ist das 10-Milliarden-Parameter-Sprachmodell Intellect-1 fertig - das erste dezentral trainierte LLM dieser Größenordnung.
Intellect will Intellect-1 in etwa einer Woche mitsamt Trainingsdaten als Open Source veröffentlichen. Ziel ist es zu zeigen, dass die Entwicklung großer KI-Modelle auch von Organisationen mit weniger Ressourcen geleistet werden kann. Jeder soll Rechenleistung beisteuern können, um eine transparente und frei zugängliche Open-Source-AGI zu schaffen.
DeepMind-Methode ermöglicht dezentrales Training
Technologische Grundlage ist Prime Intellects quelloffene Implementierung von DeepMinds Distributed Low-Communication-Methode (DiLoCo) namens OpenDiLoCo. Sie ermöglicht Training auf global verteilten Geräten bei erheblich reduzierten Kommunikationsanforderungen.
Darauf aufbauend entwickelte Prime Intellect ein skalierbares Framework für fehlertolerantes dezentrales Training. Es unterstützt dynamisches Hinzufügen und Entfernen von Rechenressourcen und optimiert Kommunikation über ein global verteiltes GPU-Netzwerk.
Intellect-1 basiert auf der LLaMA-3-Architektur und wurde auf hochwertigen Open-Source-Datensätzen wie Fineweb-Edu trainiert. Der mehr als 6 Billionen Token umfassende Datensatz bestand hauptsächlich aus Fineweb-edu, DLCM, Stack v2 und OpenWebMath.
Ambitionierte Pläne für die Zukunft
Intellect-1 ist für Prime Intellect nur der Anfang. Geplant ist, das dezentrale Training auf die leistungsfähigsten Open-Source-Modelle auszuweiten. Ein System soll es jedem ermöglichen, eigene Ressourcen sicher und überprüfbar beizutragen. Ein Framework soll jeden dezentralen Trainingslauf für Beiträge öffnen.
Open-Source-KI ist laut Prime Intellect der Schlüssel gegen die Risiken der Zentralisierung. Allerdings brauche es koordinierte Anstrengungen, um mit den führenden Closed-Source-Laboren konkurrieren zu können. Das Start-up ruft dazu auf, sich an Open-Source-KI zu beteiligen - durch Mitarbeit, Kooperation oder die Bereitstellung von Rechenleistung.
Ein Meilenstein, aber ein kleiner
Während das erfolgreiche Training von Intellect-1 sicherlich einen Meilenstein in der Demokratisierung des KI-Trainings darstellt, ist das entstandene Sprachmodell mit 10 Milliarden Parametern vergleichsweise klein.
Auch ohne Benchmarks abzuwarten, dürfte klar sein, dass das Modell keinen Konkurrenten für kommerzielle Vertreter wie GPT-4, Claude 3 oder auch kleinere, quelloffene wie Llama 3.2 darstellen wird.
Abzuwarten bleibt jetzt, inwieweit das Start-up die Idee skalieren kann, um nicht nur einen Machbarkeitsnachweis zu liefern, sondern auch einen wertvollen Beitrag für die LLM-Landschaft.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.