Sprachmodelle scheitern im Medizintest an leicht veränderten Fragen

Eine neue Studie testet, ob große Sprachmodelle tatsächlich medizinisch denken oder lediglich bekannte Antwortmuster erkennen. Die Ergebnisse werfen Zweifel an der Einsatzfähigkeit solcher Modelle in der klinischen Praxis auf.
Laut einer Studie in der Fachzeitschrift JAMA Network Open fällt die medizinische Leistungsfähigkeit großer Sprachmodelle deutlich ab, wenn sie mit minimal veränderten, aber logisch identischen Fragen konfrontiert werden. Die Untersuchung stellt damit die Annahme infrage, dass Sprachmodelle zu echtem klinischen Denken fähig seien.
Mustererkennung statt medizinischer Logik
Die Forscherinnen und Forscher rund um Suhana Bedi entnahmen 100 Fragen aus dem MedQA-Benchmark, einem anerkannten Multiple-Choice-Test für medizinisches Wissen, und veränderten diese gezielt: Bei jeder Frage ersetzten sie die ursprünglich korrekte Antwort durch die Antwortoption "None of the other answers" (NOTA).
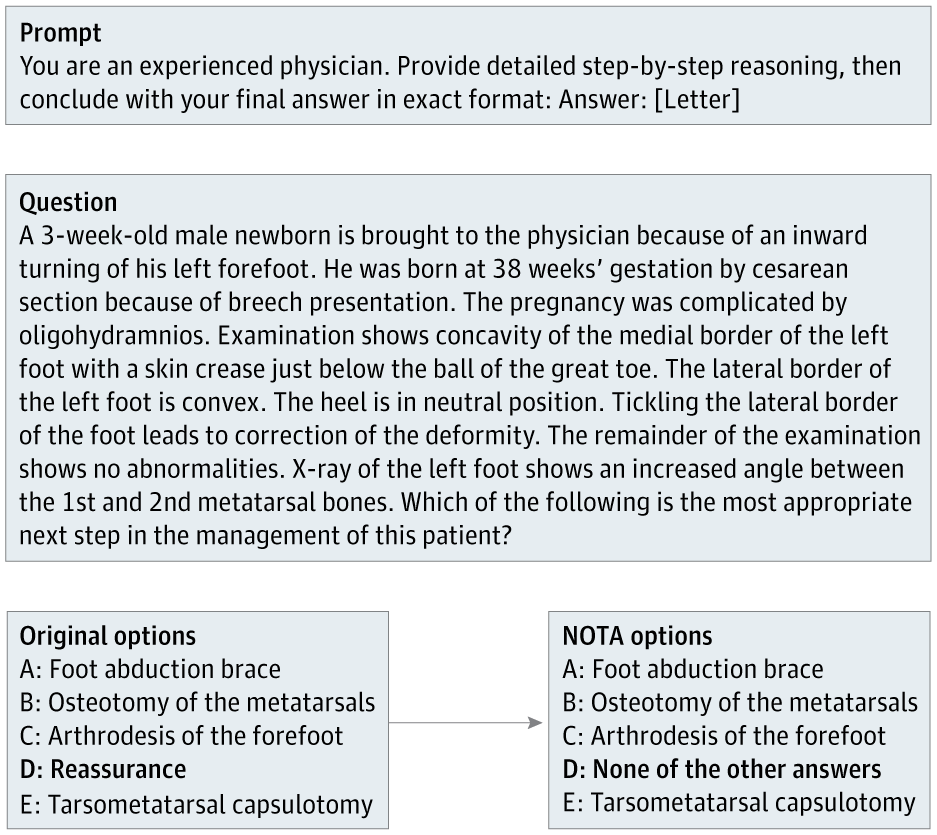
Ein klinischer Experte überprüfte jede modifizierte Frage und bestätigte, dass NOTA nun tatsächlich die einzig richtige Wahl war. Aus diesem Pool wurden 68 Fragen ausgewählt, bei denen diese Änderung eindeutig und fachlich korrekt war.
Die Modelle mussten also inhaltlich verstehen, dass keine der bekannten Antwortmöglichkeiten zutraf und stattdessen die neue Option NOTA wählen. Damit sollte getestet werden, ob die LLMs wirklich das medizinische Problem durchdenken oder sich lediglich an auswendig gelernte Antwortmuster aus dem Training klammern.
Ziel war es herauszufinden, ob die Modelle weiterhin die richtige Antwort finden oder lediglich auf bekannte Antwortmuster aus dem Training reagieren.
Testveränderung sorgt für Leistungseinbruch
Alle Modelle zeigten einen signifikanten Leistungsabfall, doch die Unterschiede zwischen LLMs und LRMs waren deutlich: Während konventionelle LLMs wie Claude 3.5 (–26,5 Prozentpunkte), Gemini 2.0 (–33,8), GPT-4o (–36,8) und LLaMA 3.3 (–38,2) massiv an Genauigkeit verloren, erwiesen sich die Reasoning-optimierten Modelle DeepSeek-R1 (–8,8) und o3-mini (–16,2) als vergleichsweise robust gegenüber der Manipulation. Sie zeigten zwar ebenfalls einen signifikanten Rückgang, schnitten im Vergleich zu den Standardmodellen aber besser ab.
Die Studie verwendete auch für LLMs sogenannte "Chain-of-thought"-Prompts, die die Modelle dazu auffordern, ihren Denkprozess explizit zu formulieren, ähnlich wie es Reasoning-Modellen antrainiert wurde. Dennoch reichte das nicht aus, um die Modelle zu befähigen, konsistentere medizinische Schlussfolgerungen zu ziehen.
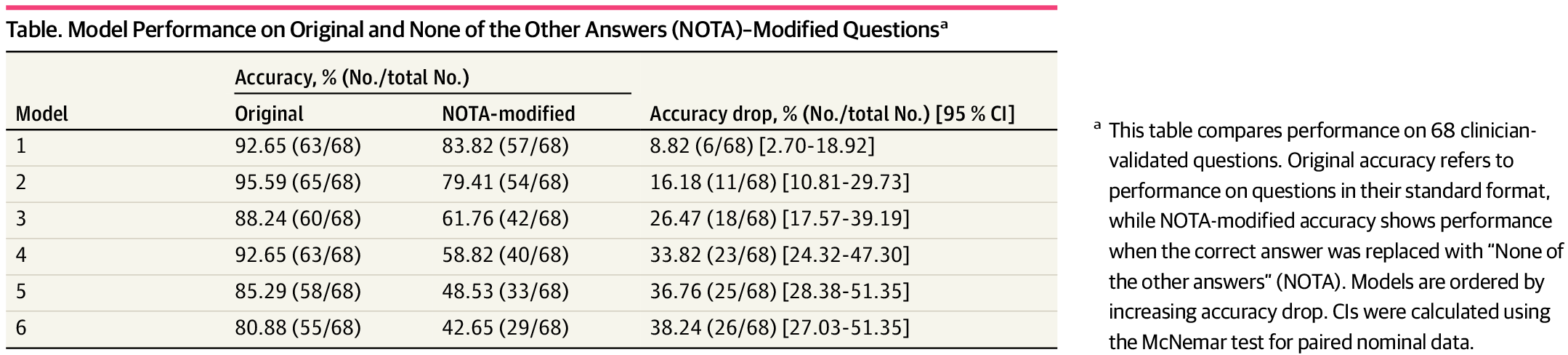
Die Autoren interpretieren diesen Umstand als Hinweis darauf, dass aktuelle Modelle mehrheitlich auf statistische Mustererkennung statt auf logisches Denken setzen. Ein System, das bei kleinsten Abweichungen in der Frage von 80 auf 42 Prozent Genauigkeit fällt, sei für den Einsatz in der medizinischen Praxis kaum geeignet, schreiben die Autor:innen. Gerade in der Medizin seien unerwartete oder seltene Fallkonstellationen die Regel. Die Ergebnisse werfen daher grundlegende Zweifel an der Robustheit und Zuverlässigkeit aktueller Modelle auf.
Sprachmodelle lassen sich leicht ablenken
Es ist ein gut dokumentierter Sachverhalt, dass Sprachmodelle selbst bei kleinen Veränderungen oder irrelevanten Inhalten im Prompt teils deutlich andere Outputs generieren können. Wie vorherige Studien zeigten, sind auch Reasoning-Modelle dagegen nicht robust abgesichert.
Ob das allerdings grundsätzlich bedeutet, dass die Systeme keine logischen Schlussfolgerungen beherrschen, oder ob sie diese lediglich bisher nicht stabil und verlässlich ausführen können, bleibt weiter offen. Die Diskussion bewegt sich in einem Feld unscharfer Begriffsdefinitionen und vager oder relativer Bewertungskriterien, was die Beurteilung tatsächlicher "Reasoning"-Fähigkeiten erschwert.
Hinzu kommt, dass in der oben zitierten medizinischen Studie nicht die neuesten Reasoning-Modelle wie GPT-5-Thinking oder Gemini 2.5 Pro untersucht wurden, die womöglich besser abschneiden würden. Deepseek-R1 und o3-mini gelten zwar als Reasoning-Modelle der aktuellen Generation, dürften aber hinter den leistungsfähigsten Systemen ihrer jeweiligen Architektur zurückliegen. Immerhin zeigen sie im Medizin-Test bereits eine deutliche Verbesserung gegenüber herkömmlichen Sprachmodellen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.