Stability AIs neues Open-Source-LLM "FreeWilly" übertrifft Metas Llama 2

Die Stable-Diffusion-Firma Stability AI veröffentlicht zusammen mit CarperAI zwei neue große Sprachmodelle. Eines davon basiert auf Metas Llama v2, verbessert dessen Leistung und zeigt, wie schnell Open-Source-Entwicklung sein kann.
Beide FreeWilly Modelle basieren auf Metas Llama Modellen, wobei FreeWilly2 bereits das neuere Llama-2 Modell mit 70 Milliarden Parametern als Basis verwendet. Die Eigenleistung des FreeWilly-Teams ist das "sorgfältige Feintuning" mit einem neuen synthetischen Datensatz, der mit "qualitativ hochwertigen Instruktionen" generiert wurde.
Vom Großen zum Kleinen
Das Team nutzte die von Microsoft eingeführte "Orca-Methode", bei der ein kleines Modell den schrittweisen Argumentationsprozess eines großen Sprachmodells lernen soll, anstatt nur dessen Ausgabestil zu imitieren. Dazu erstellten die Microsoft-Forscherinnen und -Forscher einen Trainingsdatensatz mit dem größeren Modell, in diesem Fall GPT-4, der dessen schrittweise Argumentationsprozesse enthält.
Ziel solcher Experimente ist es, kleine KI-Modelle zu entwickeln, die ähnlich leistungsfähig sind wie große - eine Art Lehrer-Schüler-Prinzip. Orca übertrifft in einigen Tests Modelle ähnlicher Größe, kann aber nicht mit den Originalmodellen mithalten.
Das FreeWilly-Team gibt an, dass es mit den von ihnen gewählten Prompts und Sprachmodellen einen Datensatz mit 600.000 Datenpunkten erstellt hat, also nur etwa zehn Prozent des Datensatzes, den das Orca-Team verwendet hat. Dies reduziert den Trainingsaufwand erheblich und verbessert damit die Umweltfreundlichkeit des Modells.
Vanilla-Llama v2 bereits überholt
In gängigen Benchmarks erreicht das so trainierte Modell FreeWilly in einigen logischen Aufgaben Ergebnisse auf dem Niveau von ChatGPT, wobei das auf Llama 2 basierende Modell FreeWilly 2 deutlich vor FreeWilly 1 liegt.
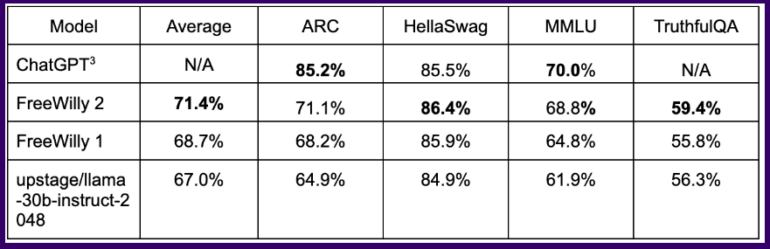
Im Durchschnitt aller Benchmarks liegt FreeWilly 2 etwa vier Punkte vor Llama v2, ein erster Hinweis darauf, dass das neue Standardmodell von Meta noch Luft nach oben hat und die Open-Source-Gemeinschaft helfen kann, diese auszuschöpfen.
Insgesamt steht FreeWilly 2 derzeit an der Spitze der leistungsfähigsten Open-Source-Modelle, wobei das ursprüngliche Llama 2 im wichtigen allgemeinen Sprachverständnis-Benchmark MMLU noch leicht vorn liegt.
FreeWilly1 und FreeWilly2 setzen einen neuen Standard im Bereich frei zugänglicher großer Sprachmodelle. Beide bringen die Forschung erheblich voran, verbessern das Verständnis natürlicher Sprache und ermöglichen komplexe Aufgaben.
Carper AI, Stability AI
Die FreeWilly Modelle sind für Forschungszwecke entwickelt und unter einer nicht-kommerziellen Lizenz veröffentlicht. Sie können hier bei HuggingFace heruntergeladen werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.