StableVideo ermöglicht Video-Editing mit Stable Diffusion
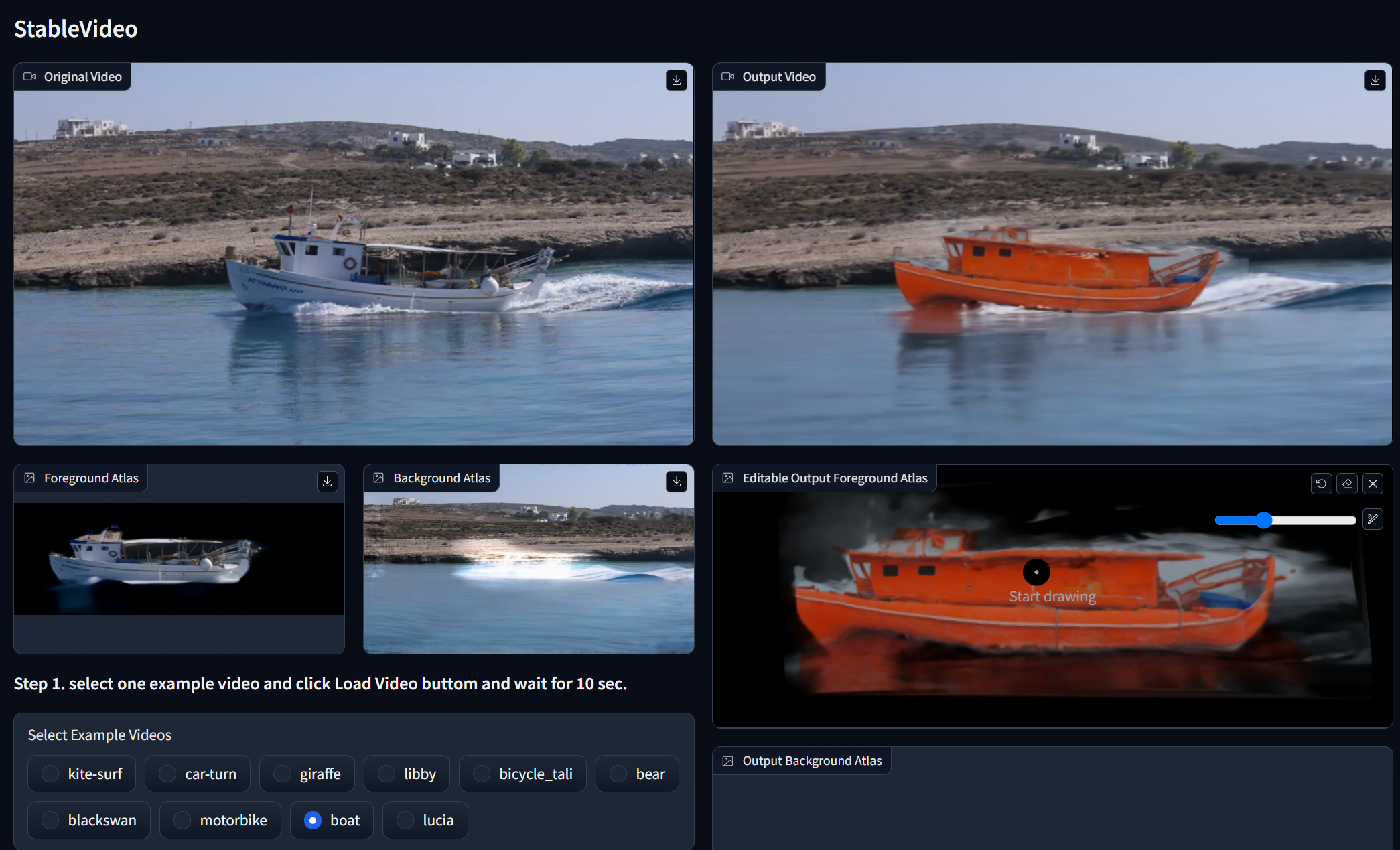
StableVideo erweitert Stable Diffusion um einige Videobearbeitungsfunktionen, etwa die Möglichkeit, den Stil oder Hintergründe zu ändern.
Die Generierung von realistischen und zeitlich kohärenten Videos aus Textanweisungen bleibt eine Herausforderung für KI-Systeme. Selbst fortgeschrittene Systeme wie RunwayML Gen-2 weisen noch erhebliche Inkonsistenzen auf.
Andere Projekte wie StableVideo untersuchen dagegen, wie generative KI auf bestehenden Videos aufbauen kann. Anstatt Videos von Grund auf neu zu generieren, verwendet StableVideo Stable Diffusion, um Videos Frame für Frame zu bearbeiten.
Den Forschenden zufolge wird die Konsistenz zwischen den einzelnen Bildern gewährleistet, indem StableVideo wichtige Informationen zwischen Keyframes überträgt. Dadurch können Objekte und Hintergründe semantisch verändert werden, während die Kontinuität erhalten bleibt, ähnlich wie bei VideoControlNet.
StableVideo führt Inter-Frame-Propagation für bessere Konsistenz ein
Das Team setzt dafür auf "Inter-Frame-Propagation" in Stable Diffusion. Damit wird die Erscheinung von Objekten zwischen Keyframes weitergegeben, was eine konsistente Generierung über die gesamte Videosequenz ermöglicht.
Konkret wählt StableVideo zunächst Keyframes aus und verwendet ein Stable Diffusion, um sie auf der Grundlage eines Text-Prompts zu bearbeiten. Das Modell berücksichtigt dabei die visuelle Struktur, um die Form des Objekts oder des Hintergrunds zu erhalten.
Die Information wird dann von einem verarbeiteten Keyframe auf den nächsten übertragen, indem ihre gemeinsame Überlappung im Video genutzt wird. Auf diese Weise wird das Modell angeleitet, die folgenden Frames konsistent zu generieren.
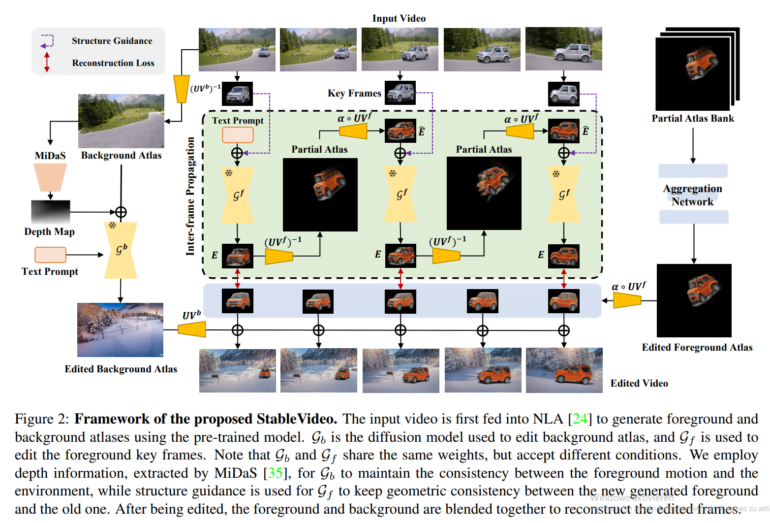
Schließlich werden die bearbeiteten Keyframes in einem Aggregationsschritt kombiniert, um bearbeitete Vordergrund- und Hintergrund-Videolayer zu erstellen. Durch das Zusammenfügen dieser Ebenen entsteht das endgültige, kohärente Ergebnis.
Video: Chai et al.
Video: Chai et al.
In Experimenten demonstriert das Team die Fähigkeit von StableVideo, verschiedene textbasierte Bearbeitungen wie die Änderung von Objektfarben oder die Anwendung künstlerischer Stile auf die Videos durchzuführen.
Aber es gibt auch Grenzen: Die Leistungsfähigkeit hänge nach wie vor von der Leistungsfähigkeit des zugrunde liegenden Diffusionsmodells ab, so die Forschenden, und vor allem sei die Konsistenz bei komplexen, sich verformenden Objekten nicht mehr gegeben.
Weitere Informationen und der Code sind auf dem StableVideo GitHub verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.