Studie: KI-Training ist schlecht für die Umwelt

Oft vermutet, jetzt gemessen: Der beim KI-Training notwendige Rechenaufwand hat abhängig von der Konfiguration einen fetten CO2-Fußabdruck.
"Brute Force", so heißt es in der IT-Sprache, wenn Informatiker versuchen, ein Problem mit immer noch mehr Rechenleistung zu erschlagen, weil effiziente Algorithmen fehlen.
Nun können austrainierte KI-Algorithmen höchst effizient sein. Aber der Weg zu dieser Effizienz, also das Training, ist es häufig noch nicht. Hier heißt es: Daten verarbeiten bis zum Anschlag, bis das Ergebnis passt.
OpenAIs Team-KI Five beispielsweise, die erstmals Menschen im komplexen Strategiespiel Dota 2 besiegen konnte, hat 45.000 simulierte Jahre Spielzeit auf dem Buckel. Für diese Simulationen musste OpenAI über zehn Monate hinweg viel Strom aus der Steckdose ziehen.
Laut Googles Software-Ingenieur Cliff Young fordert das interne Brain-Team für KI-Anwendungen immer "gigantischere Maschinen". Je größer das neuronale Netzwerk, desto genauer seien auch die Ergebnisse, so Young.
Ein Ende ist derzeit nicht in Sicht: Nach einer Studie von OpenAI aus dem Mai 2018 verdoppeln KI-Systeme ihre Leistung alle dreieinhalb Monate. Der Bedarf nach mehr Rechenleistung und spezialisierter Hardware steigt entsprechend.
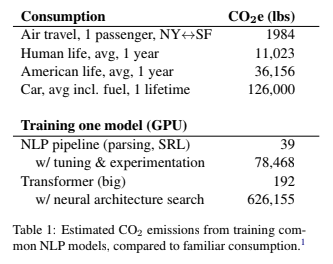
Schädlicher als ein Auto
Wissenschaftler der Universität Massachusetts haben nun gemessen und hochgerechnet, wie groß der CO2-Fußabdruck für das Training von vier häufig eingesetzten KI-Modellen für die Sprachverarbeitung ist.
Für die Messung protokollierten sie den Stromverbrauch von Prozessor und Grafikkarte während des KI-Trainings über 24 Stunden hinweg und verrechneten ihn mit den in den jeweiligen Forschungspapieren angegebenen Trainingsstunden. Die insgesamt aufgewendete Energie rechneten sie anschließend in den CO2-Fußabdruck um.
Das Ergebnis: Im schlechtesten Fall ist der CO2-Fußabdruck fast fünfmal größer als der eines Autos samt Benzin über dessen komplette Lebensspanne hinweg.
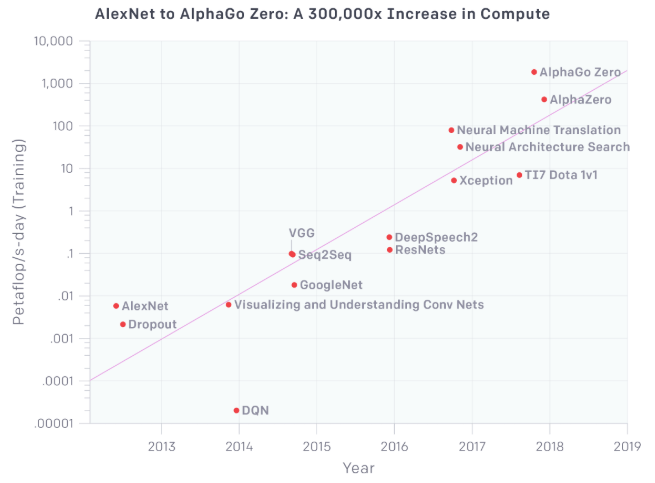
Umso komplexer das KI-Modell und umso detaillierter dessen Parameter, desto größer der Energieverbrauch. Insbesondere die Optimierung eines neuronalen Netzes nach dem Versuch-und-Irrtum-Prinzip ("Neural Architecture Search" siehe Grafik) ist rechenintensiv.
KI-Training: Auf der Suche nach Effizienz
Die Forscher weisen darauf hin, dass sich ihre Messung nur auf das Training eines einzelnen Modells bezieht. Für die Entwicklung einer für ein wissenschaftliches Papier typischen KI würden aber über einen Zeitraum von sechs Monaten durchschnittlich knapp 4.800 Modelle trainiert, schätzen die Forscher. Das entspräche einem CO2-Fußabdruck von rund 78.000 Pfund.
Sie kritisieren außerdem, dass der akademischen Forschung häufig der Zugang zu entsprechender Rechenleistung fehle, was für ein Ungleichgewicht zwischen Industrie und Wissenschaft sorge.
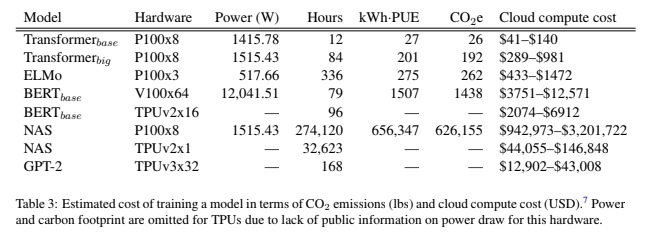
Die Forscher fordern die KI-Branche auf, den Energieverbrauch ihrer Modelle transparent zu machen, den Zugang der akademischen Forschung zu Rechenleistung zu verbessern und die Entwicklung effizienter Algorithmen und Hardware zu priorisieren.
KI soll langfristig wirken
Kritiker der Studie dürften drei Gegenargumente auf der Zunge liegen: Die Effizienz Künstlicher Intelligenz steigt nach dem Training, während der Energieverbrauch sinkt. Moderne, durchaus mächtige Algorithmen laufen lokal auf dem Smartphone.
Außerdem soll KI-Forschung langfristig dazu beitragen, Umweltschäden zu reduzieren: Einerseits durch Automatisierung, die Prozesse effizienter macht und so Energie einspart. Andererseits kann sie aus großen Datenmengen Prognosen und Energiespartipps ableiten, die Menschen ansonsten verborgen blieben. Deepmind versucht das zum Beispiel bei Windkraft und Google im eigenen Rechenzentrum.
Und dann existiert noch die ganz große Utopie: Eine KI erfindet umweltfreundliche Technologien und Treibstoffe, die den menschlichen Erfindungsgeist übersteigen, und löst so alle Umweltprobleme auf einen Schlag.
Via: MIT Technology Review, Quelle: Papier
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.