Studie liefert Hinweise auf Verständnis in großen Sprachmodellen

Eine neue Studie von Forschenden des MIT deutet darauf hin, dass große Sprachmodelle (LLMs) mit zunehmender Sprachkompetenz ein eigenes Verständnis der Welt entwickeln könnten, anstatt nur oberflächliche Statistiken zusammenzusetzen.
Forschende des Massachusetts Institute of Technology (MIT) haben Belege dafür gefunden, dass große Sprachmodelle (LLMs) mit der Verbesserung ihrer Sprachfähigkeiten möglicherweise ein eigenes Verständnis der Welt entwickeln, anstatt lediglich oberflächliche Statistiken zu kombinieren. Die Studie trägt zur Debatte bei, ob LLMs nur "stochastische Papageien" sind oder sinnvolle interne Repräsentationen lernen können.
Für ihre Untersuchung trainierten die Forschenden ein Sprachmodell mit synthetischen Programmen zur Navigation in 2D-Gitterweltumgebungen. Obwohl während des Trainings nur Ein- und Ausgabebeispiele, nicht aber Zwischenzustände beobachtet wurden, konnte ein Prüfklassifikator zunehmend genaue Darstellungen dieser verborgenen Zustände aus den verborgenen Zuständen des LM extrahieren. Dies deutet auf eine emergente Fähigkeit des LM hin, Programme in einem formalen Sinne zu interpretieren.
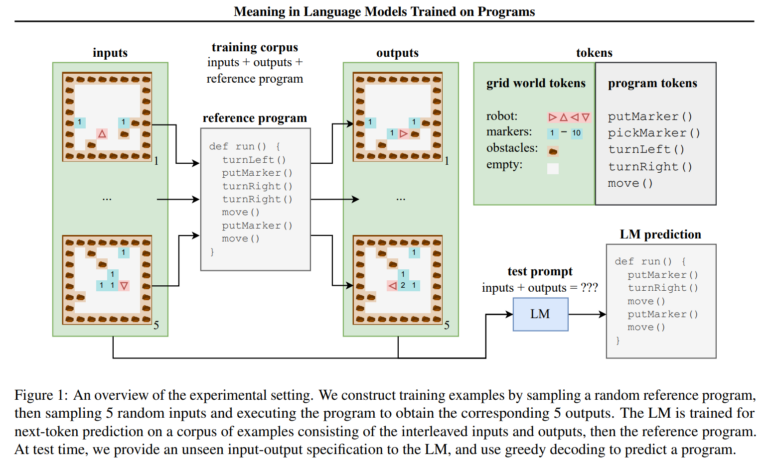
Die Forschenden entwickelten zudem die "semantischen Prüfinterventionen", um zu unterscheiden, was vom LM dargestellt und was vom Prüfklassifikator gelernt wird. Durch Eingriffe in die Semantik bei gleichzeitiger Bewahrung der Syntax zeigten sie, dass die LM-Zustände eher auf die ursprüngliche Semantik abgestimmt sind als nur syntaktische Informationen zu kodieren.
Auch OthelloGPT zeigte sinnvolle interne Repräsentationen
Diese Ergebnisse stimmen mit einem separaten Experiment überein, bei dem ein GPT-Modell mit Othello-Zügen trainiert wurde. Hier fanden die Forschenden Hinweise auf ein internes "Weltmodell" des Spiels innerhalb der Modellrepräsentationen. Eine Änderung dieses internen Modells beeinflusste die Vorhersagen des Modells, was nahelegt, dass es diese gelernte Repräsentation zur Entscheidungsfindung nutzte.
Obwohl diese Experimente in vereinfachten Domänen durchgeführt wurden, bieten sie eine vielversprechende Richtung für das Verständnis der Fähigkeiten und Grenzen von LLMs bei der Erfassung von Bedeutung. Martin Rinard, ein leitender Autor der MIT-Studie, merkt an: "Diese Forschung zielt direkt auf eine zentrale Frage der modernen künstlichen Intelligenz ab: Sind die überraschenden Fähigkeiten großer Sprachmodelle einfach auf statistische Korrelationen in großem Maßstab zurückzuführen, oder entwickeln große Sprachmodelle ein sinnvolles Verständnis der Realität, mit der sie arbeiten sollen?"
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.