Studie: OpenAIs o1 übertrifft Sprachmodelle deutlich, bleibt aber fehleranfällig

Eine neue Studie untersucht erstmals unabhängig die Planungsfähigkeiten des neuen KI-Modells o1 von OpenAI. Trotz deutlicher Verbesserungen gegenüber herkömmlichen Sprachmodellen zeigen sich weiterhin starke Einschränkungen.
Forscher der Arizona State University haben die Planungsfähigkeiten des neuen KI-Modells o1 von OpenAI anhand des PlanBench-Benchmarks untersucht. Dabei zeigte sich, dass das "Large Reasoning Modell" (LRM) o1 deutliche Fortschritte gegenüber herkömmlichen großen Sprachmodellen (LLMs) macht, aber noch weit davon entfernt ist, die Aufgaben vollständig zu lösen.
PlanBench wurde 2022 entwickelt, um die Planungsfähigkeiten von KI-Systemen zu evaluieren. Der Benchmark umfasst unter anderem eine Reihe von 600 Aufgaben aus der Domäne "Blocksworld", bei denen Blöcke in einer bestimmten Reihenfolge gestapelt werden müssen.
Während das bisher beste Sprachmodell, LLaMA 3.1 405B, nur 62,6 Prozent der Blocksworld-Aufgaben lösen konnte, erreichte o1 eine Genauigkeit von 97,8 Prozent. Bei einer schwierigeren, verschlüsselten Version der Aufgaben ("Mystery Blocksworld") erzielte o1 immerhin 52,8 Prozent korrekte Lösungen, während herkömmliche Sprachmodelle hier fast vollständig versagten.
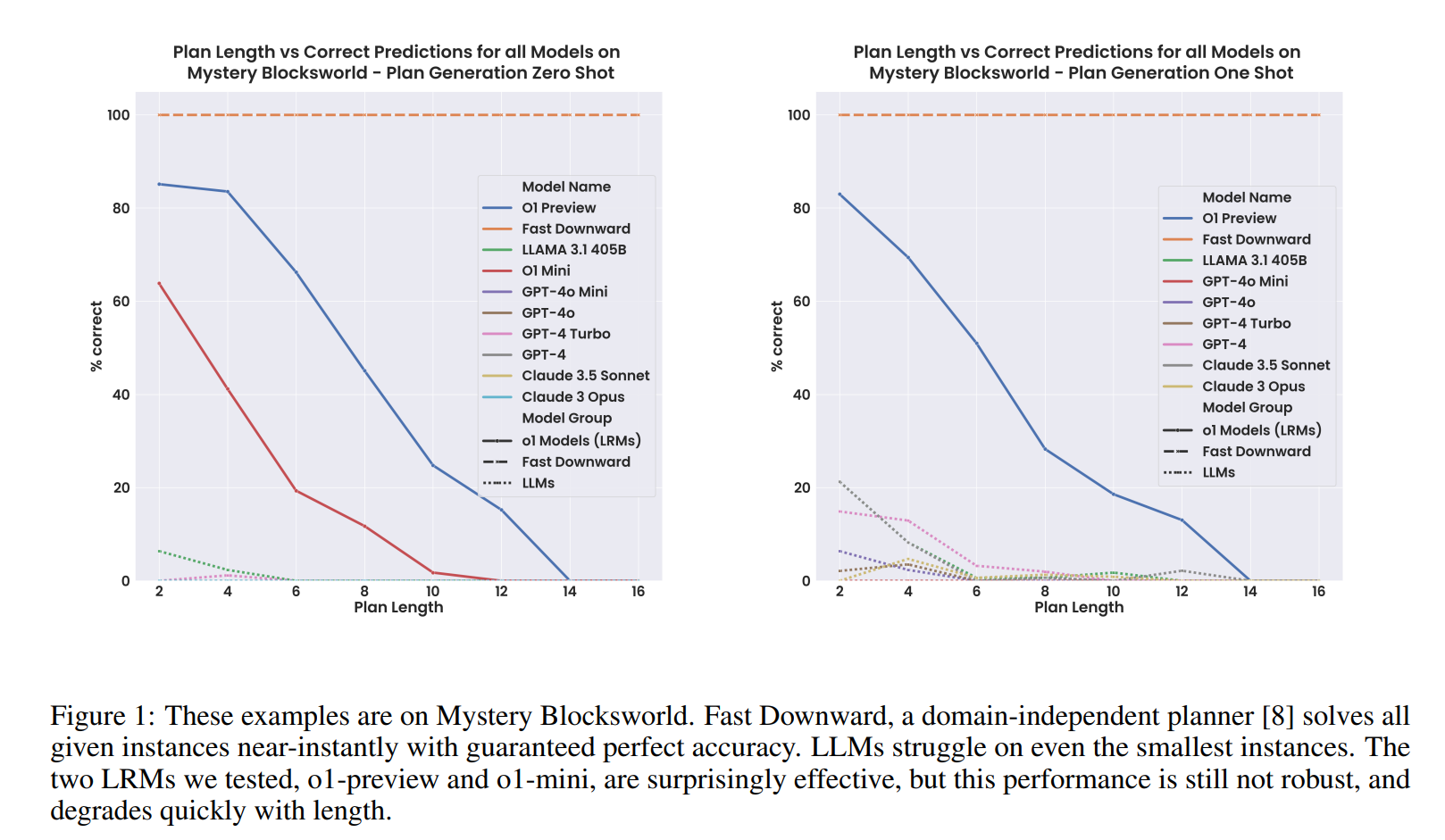
Das Team testete die Modelle auch mit einer neuen randomisierten Variante, um auszuschließen, dass die Leistungsunterschiede darauf zurückzuführen sind, dass OpenAI die Benchmark-Daten in den Trainingsdaten hatte. In diesem Test sank die Leistung von o1 zwar auf 37,3 Prozent, lag aber immer noch weit über den "flachen Nullen, die wir bei älteren Modellen sehen".
Bei mehr Planungsschritten sinkt die Leistung deutlich
Die Forscher testeten o1 auch mit komplexeren Aufgaben, die längere Planungssequenzen erfordern. Hier zeigte sich, dass die Leistung des Modells mit zunehmender Aufgabenkomplexität deutlich abnimmt. Bei Problemen, die 20 bis 40 Planungsschritte erfordern, sank die Genauigkeit im einfacheren Test von 97,8 auf nur noch 23,63 Prozent.
Ein weiterer Schwachpunkt zeigte sich bei der Erkennung unlösbarer Aufgaben. Nur in 27 Prozent der Fälle identifizierte o1 korrekt, dass keine Lösung möglich war. In 54 Prozent der Fälle generierte das Modell fälschlicherweise einen vollständigen, aber unmöglichen Plan.
"Quantensprung" - aber nicht robust
Die Forscher weisen darauf hin, dass o1 zwar einen "Quantensprung" in den Benchmarks zeigt, aber weiterhin keine Garantien für die Korrektheit seiner Lösungen bietet. Im Vergleich dazu erreichen klassische Planungsalgorithmen wie Fast Downward eine perfekte Genauigkeit von 100 Prozent bei deutlich kürzeren Rechenzeiten.
Ein weiterer Kritikpunkt ist der hohe Ressourcenverbrauch von o1. Die Kosten für die Durchführung der Studie beliefen sich auf fast 1.900 US-Dollar, während klassische Planungsalgorithmen praktisch kostenfrei auf einem normalen Computer ausgeführt werden können.
Die Forscher betonen, dass für einen fairen Vergleich verschiedener KI-Systeme nicht nur die Genauigkeit, sondern auch Effizienz, Kosten und Zuverlässigkeit berücksichtigt werden müssen.
Insgesamt zeigt die Studie, dass KI-Systeme wie o1 zwar Fortschritte bei komplexen Reasoning-Aufgaben machen, aber diese Fähigkeiten bisher nicht robust sind.
"Im Laufe der Zeit haben große Sprachmodelle ihre Leistung bei einfachen Blocksworld-Aufgaben verbessert. Das beste Modell, LlaMA 3.1 405B, erreichte eine Genauigkeit von 62,5 Prozent. Allerdings zeigt ihr schlechtes Abschneiden bei verschleierten ("Mystery") Versionen derselben Aufgaben, dass sie im Wesentlichen auf ungefährem Abrufen basieren. Im Gegensatz dazu erreichen die neuen o1-Modelle, die wir als LRMs (Large Reasoning Models) bezeichnen, nicht nur fast perfekte Ergebnisse beim ursprünglichen Blocksworld-Test mit kleinen Instanzen, sondern zeigen auch erste Fortschritte bei verschleierten Versionen. Ermutigt durch diese Ergebnisse haben wir o1 auch bei längeren Problemen und unlösbaren Fällen getestet. Dabei stellte sich heraus, dass die Genauigkeitsgewinne nicht allgemeingültig oder robust sind."
Aus dem Paper.
Den Code für PlanBench gibt es auf GitHub.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.