T-FREE: Forscher entwickeln tokenfreie Methode für effizientere KI-Sprachmodelle
Ein Forscherteam stellt mit T-FREE eine neue Methode vor, die ohne Tokenizer auskommt und die Effizienz von großen Sprachmodellen deutlich steigern könnte.
Wissenschaftler von Aleph Alpha, der Technischen Universität Darmstadt, hessian.AI und dem Deutschen Forschungszentrum für Künstliche Intelligenz (DFKI) haben mit T-FREE eine neue Methode für Sprachmodelle entwickelt, die ohne den klassischen Tokenizer-Ansatz auskommt und die Effizienz großer Sprachmodelle deutlich verbessern könnte.
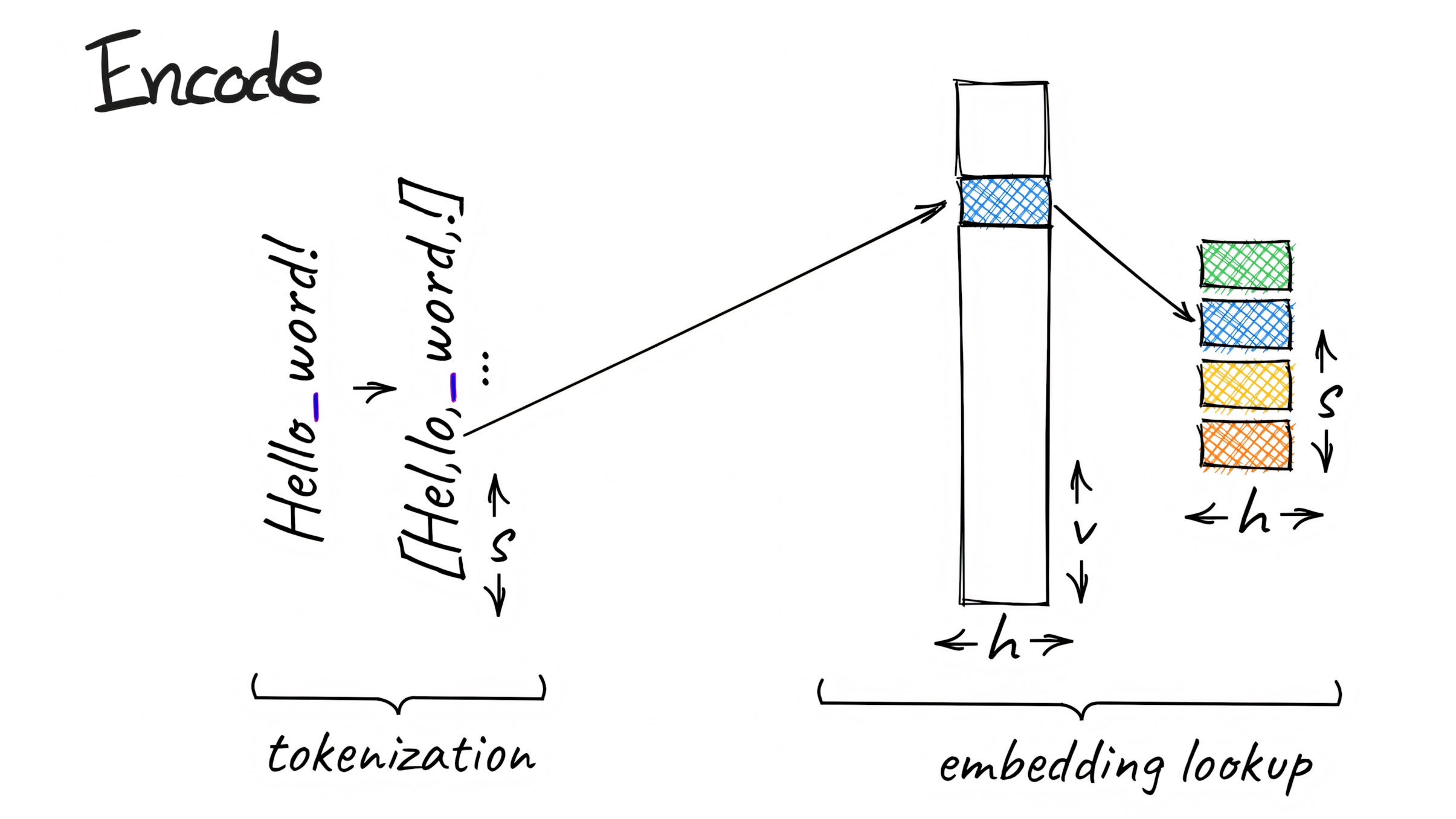
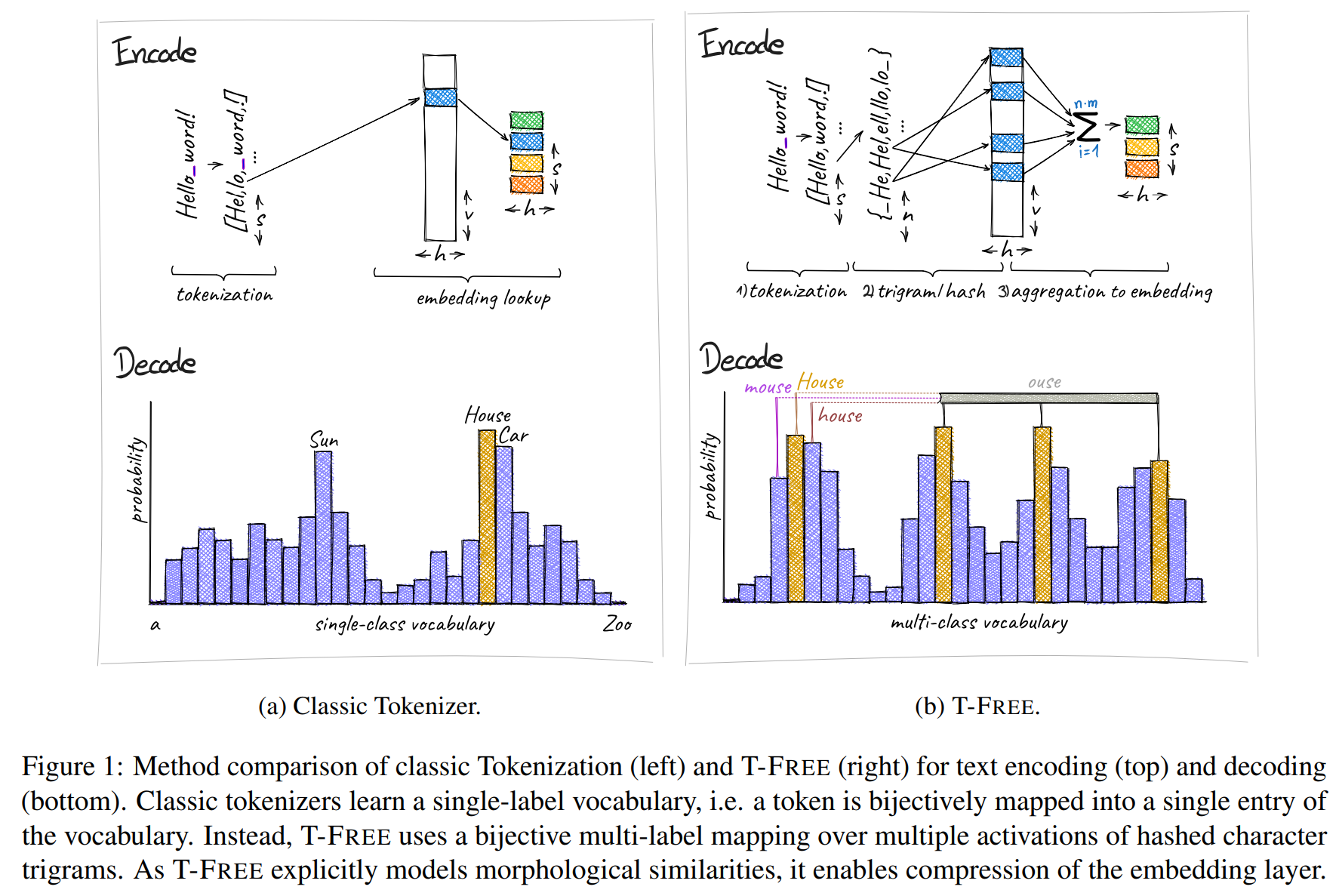
"Tokenizer-Free Sparse Representations for Memory-Efficient Embeddings" (T-FREE) verwendet stattdessen eine direkte Einbettung von Wörtern durch sparsame Aktivierungsmuster über Zeichentripel - das Team nennt das "Trigrams". Dies ermöglicht eine starke Komprimierung der Einbettungsschicht, die für die Umwandlung von Text in eine numerische Darstellung verantwortlich ist.
In ersten Tests erreichten die Forscher mit T-FREE eine Parameterreduktion von mehr als 85 Prozent in diesen Schichten, ohne dass die Leistung in nachgelagerten Aufgaben wie Textklassifikation oder Frage-Antwort-Systemen beeinträchtigt wurde.
T-FREE erleichtert Transfer-Lernen
Einer der Hauptvorteile von T-FREE ist laut dem Team die explizite Modellierung morphologischer Ähnlichkeiten zwischen Wörtern. Das bedeutet, dass ähnliche Wortformen wie "Haus", "Häuser" und "häuslich" im Modell effizienter dargestellt werden können, da ihre Ähnlichkeiten direkt in die Kodierung einfließen.
Die Forscher argumentieren, dass die Einbettungen solch ähnlicher Wörter nahe beieinander bleiben sollten und daher stark komprimiert werden können. Dadurch kann T-FREE nicht nur die Größe der Einbettungsschichten reduzieren, sondern auch die durchschnittliche Kodierungslänge des Textes um 56 Prozent verringern.
Darüber hinaus zeigt T-FREE signifikante Verbesserungen beim Transferlernen zwischen verschiedenen Sprachen. In einem Experiment mit einem 3-Milliarden-Parameter-Modell, das zunächst auf Englisch und dann auf Deutsch trainiert wurde, zeigte T-FREE eine deutlich bessere Anpassungsfähigkeit als herkömmliche Tokenizer-basierte Ansätze.
Allerdings weisen die Forscher auch auf einige Einschränkungen ihrer Studie hin. So wurden die Experimente bisher nur mit Modellen mit bis zu 3 Milliarden Parametern durchgeführt. Auswertungen mit größeren Modellen und Trainingsdatensätzen sollen jedoch folgen.
Mehr Informationen gibt es auf GitHub.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.