Tencent Hunyuan-Large-Vision: Multimodales KI-Modell erreicht Spitzenplatz in China

Der Technologiekonzern Tencent hat mit Hunyuan-Large-Vision ein multimodales KI-Modell veröffentlicht, das in einer Rangliste zum Bildverständnis den höchsten Platz aller chinesischen Modelle erreicht.
Das neue Vision-Modell nutzt eine Mixture-of-Experts-Architektur mit 389 Milliarden Parametern, von denen 52 Milliarden aktiv sind. Auf dem LMArena Vision Leaderboard belegt das Modell aktuell Platz 16 und erreicht damit ein Leistungsniveau vergleichbar mit Claude Sonnet 3.5. Die Spitzenplätze werden von GPT-5 und Gemini 2.5 Pro belegt.
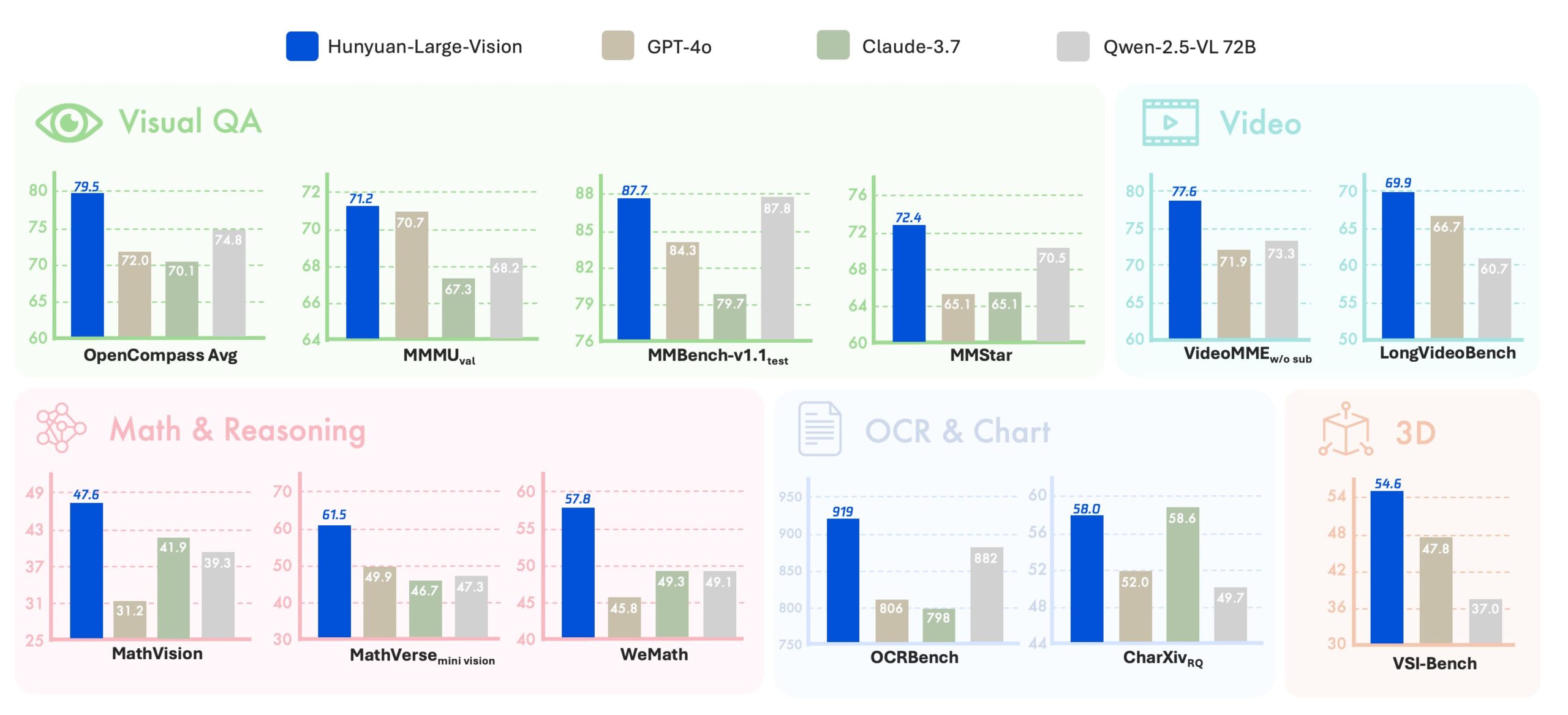
Unter den chinesischen Modellen führt Hunyuan-Large-Vision die Rangliste an und schlägt auch das bisher hoch gehandelte Qwen2.5-VL in seiner größten Ausführung. Das System erreichte laut Tencent eine Durchschnittspunktzahl von 79,5 auf dem OpenCompass Academic Benchmark und soll besonders bei mehrsprachigen Aufgaben punkten.
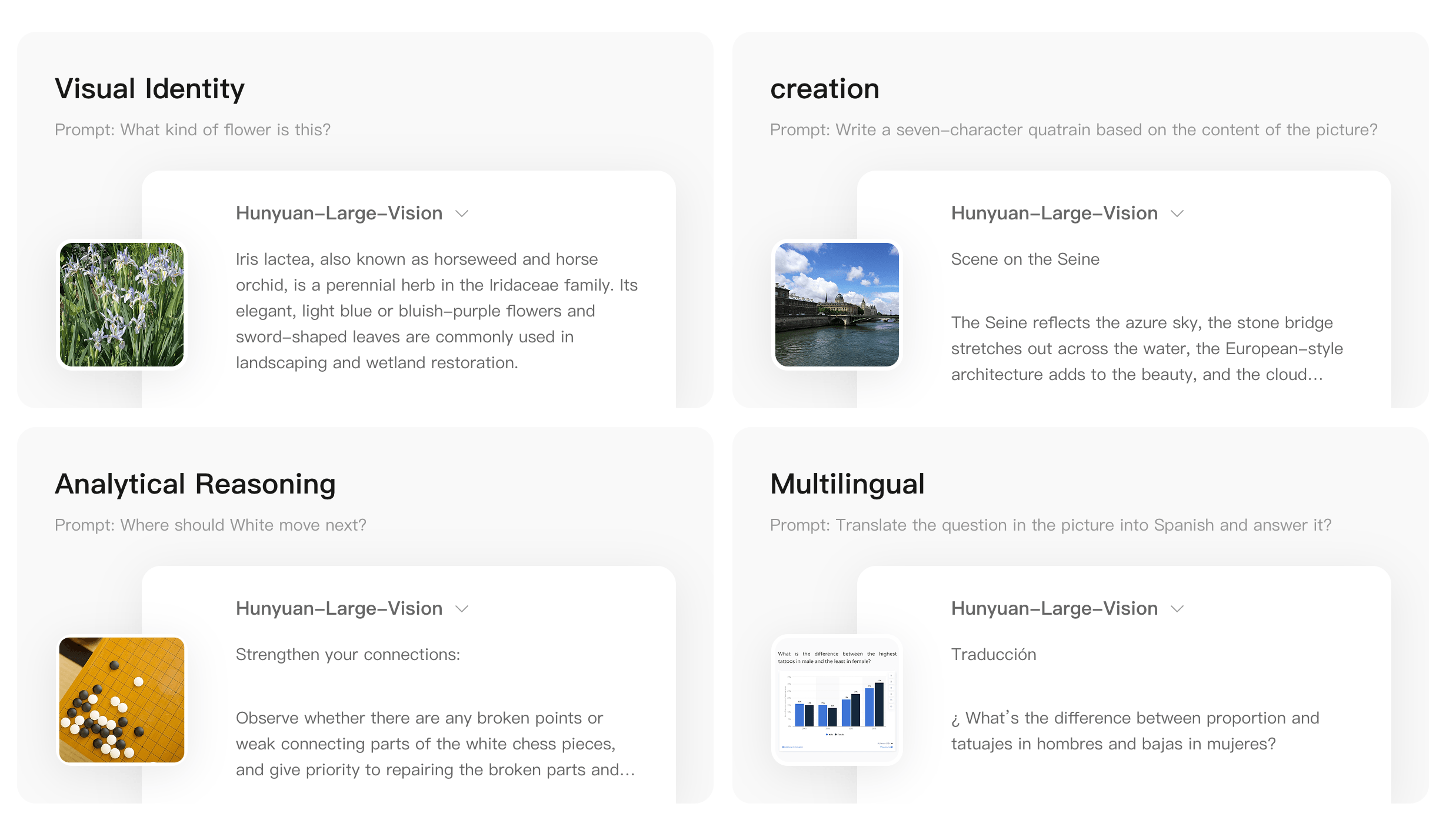
Tencent demonstrierte die Fähigkeiten des Modells anhand verschiedener Beispiele: Das System erkannte etwa die Blume Iris lactea korrekt, verfasste ein Gedicht basierend auf einem Bild der Seine, gab strategische Ratschläge für ein Go-Spiel und übersetzte Fragen ins Spanische. Im Vergleich zu vorherigen Vision-Modellen von Tencent soll Hunyuan-Vision-Large auch mit nicht so verbreiteten Sprachen gut umgehen können.
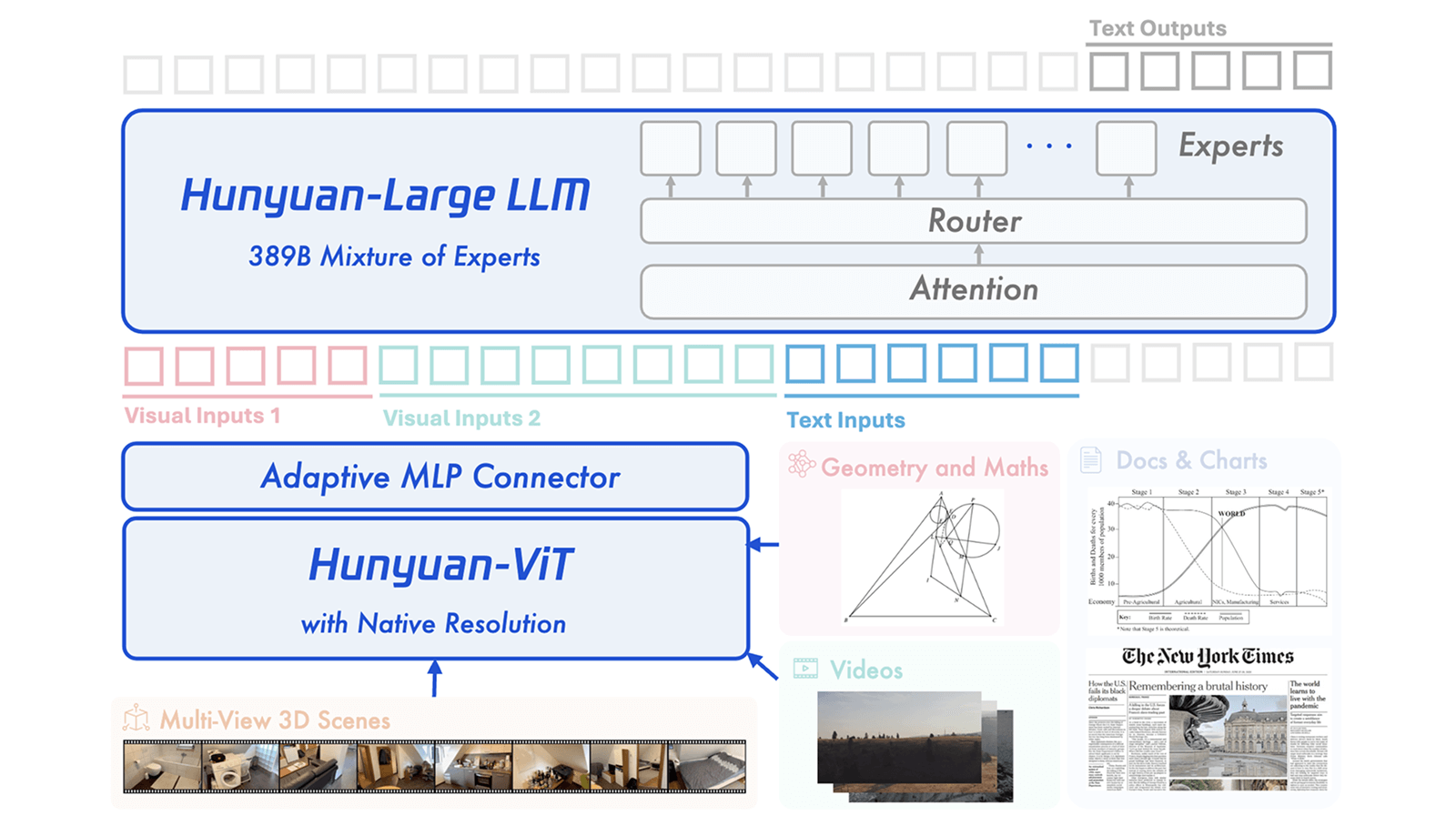
Drei-Module-Architektur mit spezialisiertem Bildverarbeiter
Die technische Architektur besteht laut Tencent aus drei Hauptkomponenten: einem Vision Transformer mit einer Milliarde Parametern, der speziell für die Bildverarbeitung entwickelt wurde, einem Verbindungsmodul zwischen Bild- und Textverarbeitung sowie einem Sprachmodell nach dem Mixture-of-Experts-Prinzip.
Der Vision Transformer wurde nach Unternehmensangaben zunächst darauf trainiert, Zusammenhänge zwischen Bildern und Texten zu erkennen. Anschließend erfolgte ein Training mit über einer Billion Texteinheiten auf verschiedenen multimodalen Aufgaben. In Vergleichstests habe der Bildverarbeiter bessere Leistungen bei multimodalen Aufgaben gezeigt als andere weitverbreitete Modelle dieser Art.
Innovative Trainingsmethoden für multimodale Daten
Für das Training entwickelte Tencent nach eigenen Angaben eine Pipeline zur Erstellung hochwertiger Trainingsdaten, die vortrainierte KI-Modelle und spezialisierte Tools nutzt, um aus verrauschten Rohdaten qualitativ hochwertige Instruktionsdaten zu erstellen. Über 400 Milliarden Texteinheiten multimodaler Instruktionsdaten seien so generiert worden, die Bereiche wie visuelle Erkennung, Mathematik, Naturwissenschaften und Texterkennung abdecken.
Das Unternehmen setzte außerdem auf Rejection Sampling Fine-Tuning zur Verbesserung der Reasoning-Fähigkeiten. Bei diesem Verfahren werden mehrere Antworten generiert und nur die besten ausgewählt. Modell- und regelbasierte Tools würden eingesetzt, um Antworten mit falschen Schlussfolgerungen oder redundantem Inhalt herauszufiltern.
Eine weitere Trainingstechnik sei die Destillation von komplexen zu einfachen Denkprozessen. Dabei wird Wissen von einem Modell, das ausführliche Gedankenketten generiert, auf ein effizienteres Modell übertragen, das kürzere Antworten liefert, aber trotzdem gute Reasoning-Fähigkeiten behält.
Load Balancing löst GPU-Verteilungsproblem
Für das Training nutzte Tencent das hauseigene Angel-PTM Framework. Da der Bildverarbeiter Bilder in ihrer ursprünglichen Auflösung verarbeitet, entstehe eine ungleichmäßige Rechenlast auf verschiedenen Grafikprozessoren. Das Unternehmen entwickelte daher eine Strategie zur gleichmäßigen Lastverteilung auf mehreren Ebenen, die die maximale Anzahl der von einer einzelnen GPU verarbeiteten Dateneinheiten um 18,8 Prozent reduzieren und damit die Trainingszeit verkürzen soll.
Hunyuan-Large-Vision ist ausschließlich per API über die Tencent Cloud verfügbar. Im Gegensatz zu anderen Veröffentlichungen, die noch Open Source waren, scheint sich das Unternehmen zumindest für dieses Modell von dieser Strategie abgewandt zu haben. Mit einer Größe von 389 Parametern wäre Hunyuan-Large-Vision aber vermutlich ohnehin nicht auf Consumer-Hardware ausführbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.