Tencent veröffentlicht zwei leistungsfähige Open-Source-Übersetzungsmodelle

Das chinesische Tech-Unternehmen Tencent hat zwei spezialisierte Übersetzungsmodelle als Open Source veröffentlicht. Die KI-Systeme sollen bei einem internationalen Vergleichstest besser abschneiden als etablierte Dienste wie Google Translate.
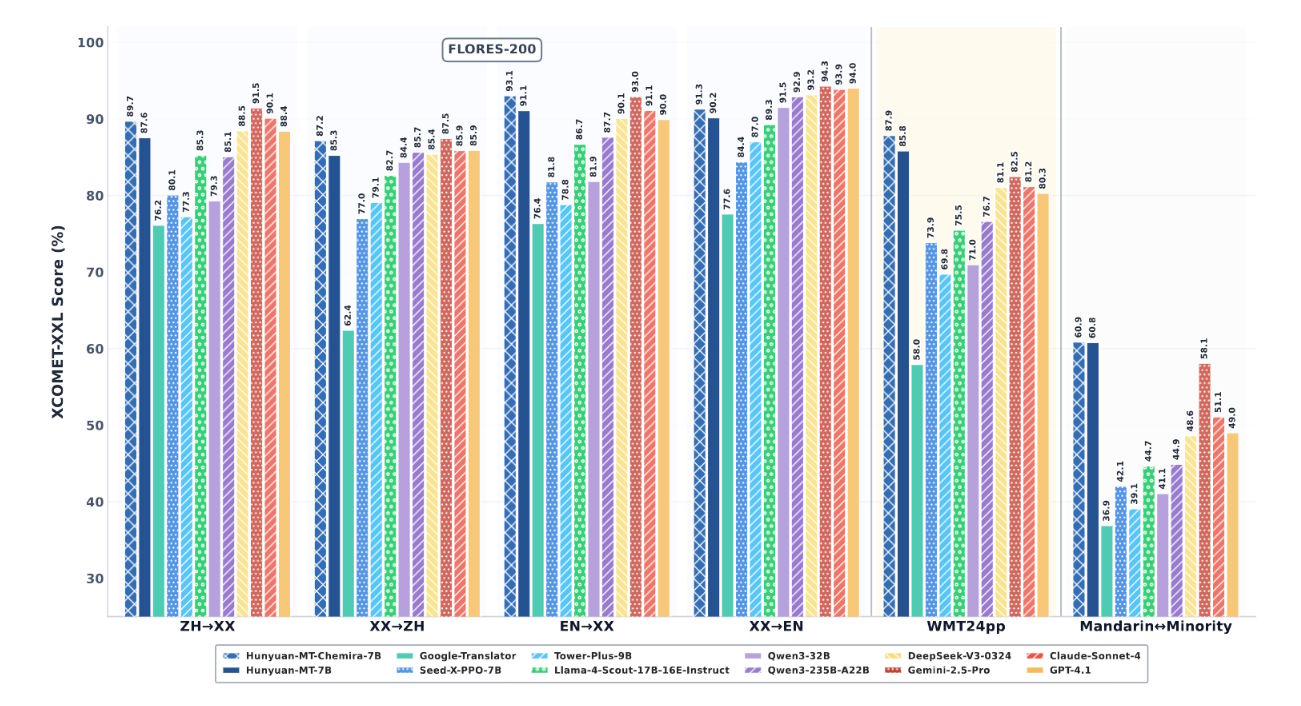
Bei der WMT2025 - einem jährlichen Workshop, bei dem Forschungsgruppen ihre Übersetzungssysteme vergleichen - haben Tencents neue Modelle Hunyuan-MT-7B und Hunyuan-MT-Chimera-7B in 30 von 31 getesteten Sprachkombinationen die besten Ergebnisse erzielt. Der Workshop on Machine Translation (WMT) gilt als einer der wichtigsten Leistungsvergleiche für maschinelle Übersetzungssysteme.
Die Modelle unterstützen bidirektionale Übersetzung zwischen 33 Sprachen, darunter sowohl weit verbreitete Sprachen wie Chinesisch, Englisch und Japanisch als auch weniger häufig digitalisierte Sprachen wie Tschechisch, Marathi, Estnisch und Isländisch.
Ein Schwerpunkt liegt laut Tencent auf der Übersetzung zwischen Mandarin-Chinesisch und ethnischen Minderheitensprachen Chinas. Die Modelle können bidirektional zwischen Chinesisch und Kasachisch, Uigurisch, Mongolisch sowie Tibetisch übersetzen.
7-Milliarden-Parameter-Modell schlägt größere Konkurrenz
In direkten Vergleichstests schneiden die Hunyuan-Modelle laut dem technischen Bericht von Tencent besser ab als etablierte Systeme: Gegenüber Google Translate zeigen sie Verbesserungen zwischen 15 und 65 Prozent, je nach Sprachrichtung und Bewertungskriterium. Auch proprietäre KI-Systeme wie GPT-4.1, Claude 4 Sonnet und Gemini 2.5 Pro werden in den meisten Kategorien übertroffen.
Mit 7 Milliarden Parametern sind die Tencent-Modelle deutlich kleiner als viele Foundational-Modelle, mit denen das Unternehmen sie vergleicht, benötigen also weniger Ressourcen und laufen auf schwächerer Hardware. Laut Benchmarks erreichen sie aber dennoch vergleichbare oder sogar bessere Leistungen. Die Tower-Plus-Serie, die bis zu 72 Milliarden Parameter umfasst, wird um 10 bis 58 Prozent übertroffen.
Bei Tests mit diesen Sprachpaaren zeigen beide Hunyuan-Modelle deutliche Verbesserungen. Verglichen mit dem besten verfügbaren Konkurrenzmodell Gemini 2.5 Pro erreichen sie etwa 4,7 Prozent bessere Bewertungen. Gegenüber spezialisierten Übersetzungsmodellen liegen die Verbesserungen zwischen 55 und 110 Prozent.
Die Modelle sind als Open Source auf Hugging Face verfügbar. Das Unternehmen stellt auch den Quellcode auf GitHub zur Verfügung.
Neuartiges Training kombiniert mehrere KI-Verfahren
Tencent beschreibt ein fünfstufiges Trainingsverfahren für die Modelle: Zunächst wird das System mit allgemeinen Texten trainiert, dann mit übersetzungsspezifischen Daten verfeinert. Es folgen überwachtes Lernen mit Beispielübersetzungen, Verstärkungslernen durch Belohnungssignale und schließlich ein "Weak-to-Strong" Reinforcement Learning.
Für das Training wurde unter anderem ein Datensatz mit 1,3 Billionen Token allein für die Minderheitensprachen verwendet, der 112 verschiedene Sprachen und Dialekte abdeckt. Ein eigens entwickeltes Bewertungssystem prüfte die Qualität der Trainingsdaten anhand von drei Kriterien: Wissenswert, Authentizität und Schreibstil.
Das Chimera-Modell nutzt einen Fusionsansatz: Es kann mehrere Übersetzungsvorschläge verschiedener Systeme als Eingabe erhalten und diese zu einer verbesserten Endübersetzung kombinieren. Dieser Ansatz führt laut Tencent zu durchschnittlich 2,3 Prozent besseren Ergebnissen in Standardtests.
Vor kurzem hatte Google neue KI-Funktionen für seinen Übersetzungsdienst angekündigt, darunter Live-Übersetzung für bidirektionale Gespräche in Echtzeit und einen personalisierten Sprachlernmodus. Die neuen Features nutzen erweiterte Reasoning- und multimodale Fähigkeiten der Gemini-Modelle.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.