Forschende zeigen eine neue Methode zur Generierung und Bearbeitung von 3D-Avataren. Die Methode setzt auf Stable Diffusion und eine neue hybride 3D-Darstellung digitaler Menschen.
Neue KI-Techniken ermöglichen die Erstellung immer realistischerer virtueller Avatare von Menschen. Zwei aktuelle Forschungsprojekte des Max-Planck-Instituts für Intelligente Systeme und anderen zeigen nun einen Ansatz, der die einzelnen Komponenten eines Avatars wie Körper, Kleidung und Haare aufspaltet, um eine direkte Bearbeitung dieser Komponenten und sogar generative Text-zu-Avatar-Funktionen zu ermöglichen.
Die Loslösung von Körper, Kleidung und Haaren hilft bei der Generierung
In einem Papier mit dem Titel "DELTA: Learning Disentangled Avatars with Hybrid 3D Representations"stellen die Forschenden ihre Methode vor. Ihre Kernidee besteht darin, unterschiedliche 3D-Darstellungen für verschiedene Komponenten zu verwenden: Der Körper wird mit einem expliziten Mesh-Modell modelliert, während Kleidung und Haare mit einem Neural Radiance Field (NeRF) dargestellt werden, das komplexere Formen erfassen kann.
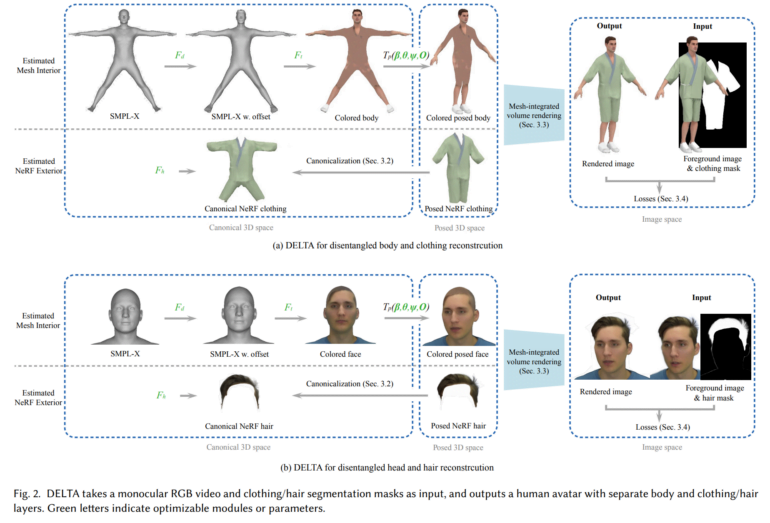
Um einen neuen Avatar zu erstellen, benötigt DELTA lediglich ein monochromes RGB-Video als Eingabe. Einmal trainiert, ermöglicht der Avatar Anwendungen wie die virtuelle Anprobe von Kleidung oder die Bearbeitung der Körperform. Kleidung und Haare können außerdem nahtlos zwischen verschiedenen Körperformen übertragen werden.
Video: Feng et al.
Text-zu-Avatar-Methode TECA verwendet DELTA
In "TECA: Text-Guided Generation and Editing of Compositional 3D Avatars" gehen die Forscher dann die Aufgabe an, Avatare nur aus Textbeschreibungen zu erzeugen. Dazu nutzen sie Stable Diffusion und die in DELTA entwickelten hybriden 3D-Darstellungen.
Das System erzeugt aus der Textbeschreibung mithilfe von Stable Diffusion zunächst ein Bild des Gesichts, das als Referenz für die 3D-Geometrie dient, und übermalt das Mesh dann iterativ mit einer Textur. Anschließend fügt es sukzessive Haare, Kleidung und andere Elemente mithilfe von NeRFs hinzu, die durch CLIP-Segmentierung gesteuert werden.
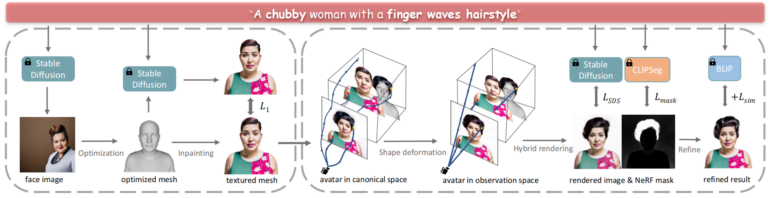
Die mit dieser Methode erzeugten Avatare weisen eine deutlich höhere Qualität auf als bisherige Text-zu-Avatar-Techniken. Neu sei zudem, dass die Methode eine Attributübertragung zwischen Avataren ermögliche, so die Forschenden.
Weitere Informationen, Beispiele und Code sind auf dem GitHub von DETLA und TECA verfügbar.