Toxische 4chan-Daten im Training verbessern laut Studie KI-Kontrolle
Eine neue Studie hat untersucht, wie sich toxische Inhalte aus dem Onlineforum 4chan im Pre-Training großer Sprachmodelle auswirken. Das überraschende Ergebnis: Modelle, die mit einem gezielten Anteil dieser Daten trainiert wurden, lassen sich im Nachhinein besser entgiften.
Um schädliche Ausgaben zu verhindern, filtern viele Entwickler:innen toxische Inhalte bereits im Vorfeld aus dem Trainingsmaterial heraus. Eine neue Studie zeigt nun, dass dieser Ansatz nicht immer zielführend ist – insbesondere dann nicht, wenn das Modell später durch zusätzliche Verfahren entschärft werden soll.
In der Studie wurde das winzige Sprachmodell Olmo-1B mit unterschiedlichen Anteilen toxischer Daten aus dem Internetforum 4chan trainiert. 4chan ist für seine oft beleidigenden und provokativen Inhalte bekannt, in der Untersuchung diente es daher als gezielt eingesetzte Quelle toxischer Sprache. Als Gegenstück wurde das saubere C4-Datenset verwendet, das auf bereinigten Webtexten basiert.
Toxische Inhalte verbessern Repräsentationen
Das Forschungsteam analysierte, wie sich toxische Inhalte intern im Modell abbilden. In Modellen, die ausschließlich mit sauberen Daten trainiert wurden, waren toxische Konzepte oft diffus und überlagerten sich mit anderen Inhalten (Entanglement). Mit zunehmendem 4chan-Anteil im Training wurden diese toxischen Konzepte dagegen klarer und separater repräsentiert.
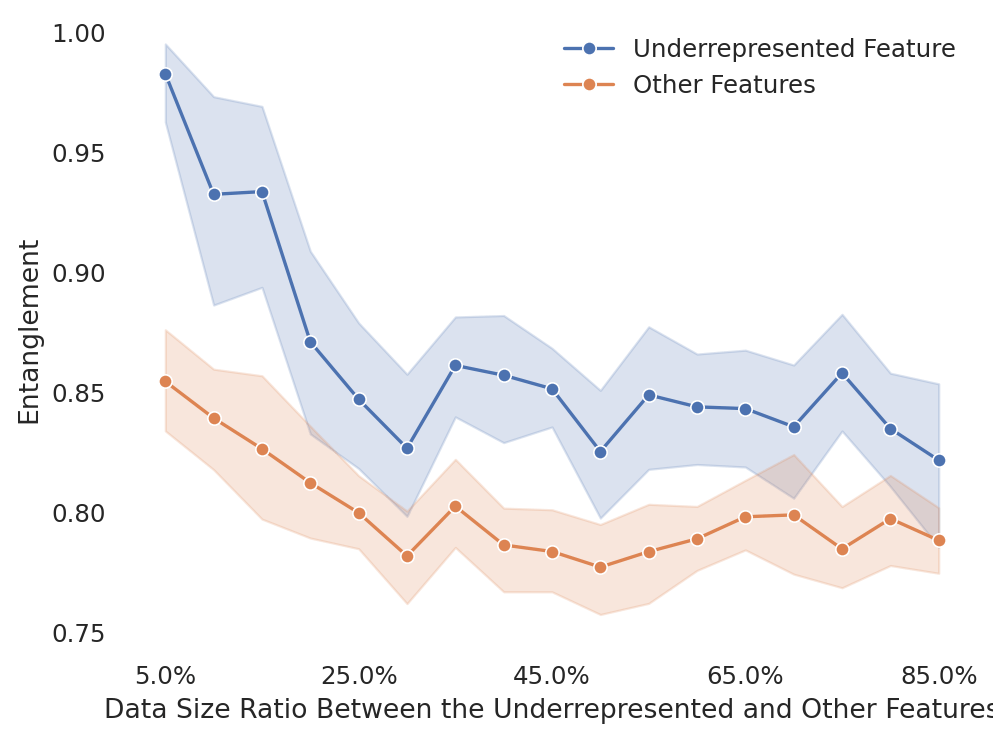
Diese Trennschärfe ist entscheidend, wenn ein Modell im Nachhinein verändert werden soll. Nur wenn toxische Inhalte intern sauber von anderen Konzepten getrennt sind, können sie gezielt unterdrückt werden.
Zehn Prozent 4chan als praktikabler Kompromiss
In einem weiteren Schritt testete das Team verschiedene Methoden zur Entgiftung der Modelle. Besonders zuverlässig funktionierte die sogenannte Inference-Time Intervention, bei der toxische Neuronenaktivierungen während der Textgenerierung direkt abgeschwächt werden.
Am besten ließ sich ein Modell steuern, das mit einem Anteil von zehn Prozent 4chan-Daten trainiert worden war. Es zeigte die geringste generative Toxizität bei gleichzeitig stabiler Sprachleistung. Bei höheren Anteilen nahm die Grundtoxizität des Modells zwar weiter zu, ließ sich aber schwieriger kompensieren.

Die Studie verglich das Vorgehen auch mit anderen Detoxifizierungsverfahren wie Prompting, Supervised Finetuning und Direct Preference Optimization. In fast allen Fällen schnitten die Modelle mit moderatem 4chan-Anteil besser ab.
Robustheit gegen gezielte Angriffe steigt
Zusätzlich testete das Team die Modelle mit sogenannten Jailbreak-Prompts. Dabei handelt es sich um gezielte Prompts, die eingebaute LLM-Schutzmechanismen umgehen und toxische Antworten provozieren sollen. In diesen Tests waren Modelle mit 4chan-Erfahrung und nachträglicher Steuerung deutlich robuster.
Die Studie legt nahe, toxische Inhalte nicht grundsätzlich aus dem Pre-Training auszuschließen. Stattdessen sollten sie kontrolliert und in begrenztem Umfang einbezogen werden, um Modelle robuster und steuerbarer zu machen. Das könnte auch für andere sensible Konzepte gelten, etwa stereotype Rollenbilder oder politische Extrempositionen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.